换种视角看问题——支持向量机(SVM)
Posted Stata and Python数据分析
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了换种视角看问题——支持向量机(SVM)相关的知识,希望对你有一定的参考价值。
文字编辑:孙晓玲
技术总编:张 邯
Stata暑期线上课程火热招生中~
爬虫俱乐部将于2020年7月11日至14日在线上举行为期四天的Stata编程技术定制培训。课程通过案例教学模式,旨在帮助大家在短期内掌握Stata的基本命令、编程、数据处理以及结果输出等技术,并针对最新版Stata中的实用新功能做出详细介绍,包括框架功能(frame:读入多个数据集)等等。同时,此次云端课程提供录播,提供线上答疑。详细培训大纲及报名方式请查看,或点击文末阅读原文直接提交报名信息呦~
魔鬼把大侠的妻子劫走了,大侠为了救她,来和魔鬼交涉。魔鬼说:“你若能解答出我的问题,我便放了她”。大侠同意了,随后魔鬼大手一挥,在桌子上出现了两种颜色的球,要求用一根棍子将它们分开:
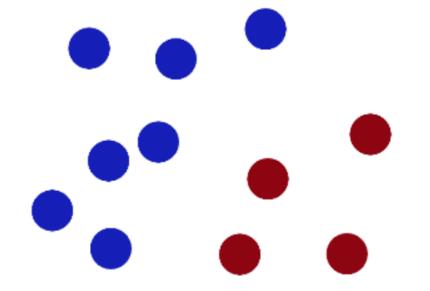
大侠不假思索将棍子放在了中间的位置。
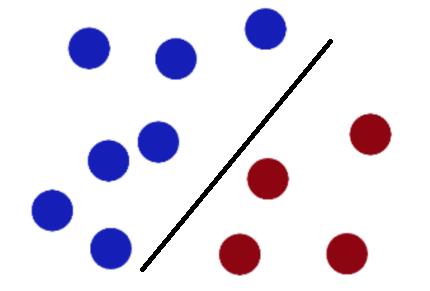
为了刁难他,这时魔鬼又挥了挥手,球变成了下面的摆法:
大侠略一思索,将桌子一拍,在球飞到空中时,将一张纸扔在两种球之间便分开了,问题迎刃而解。魔鬼无奈,只得让大侠将他的妻子带走了。
大侠是怎么做到的呢?看了下面对今天的算法的介绍,你就会有答案的。我们上一讲介绍Logistic回归(《》)时说过,这个分类器是通过在线性函数f(x)=wTx+b上利用Sigmoid函数得到分类的结果,在求解过程中使所有点都尽可能远离分类的“木棍”。这一分类器实际上属于线性分类器的一种,即通过特征的线性组合来做出分类决定。而我们今天要介绍的支持向量机SVM(Support Vector Machines)也是线性分类器的一种,与Logistic回归不同,SVM并不需要使所有的点都远离分类的那根“木棍”,它只要求最靠近“木棍”的那些点尽可能地离分界处最远,这些点称为 支持向量,因此得到的分类算法称为支持向量机。既然属于线性分类的一种,那么毫无疑问分类的“木棍”就是f(x)=wTx+b,在二维空间里就是一条直线,在三维空间中代表一个平面,当大于三维时很难对其可视化,我们将这些统称为超平面,而SVM就是要找到最优的超平面,使支持向量到超平面的最小距离达到最大。所以根据点到直线的距离公式我们可以得到
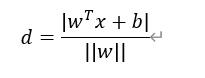
假设类别标签为1和-1,即
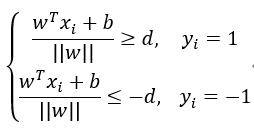
也就是分类标签为1的样本点到直线的距离都大于等于d,对于所有分类标签为-1的样本点到直线的距离都小于等于d。两侧同时除以d,并进行化简,上式也可以写成下面的形式
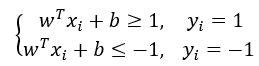
即得到约束yi(wT xi+b)≥1。我们说过,SVM是用支持向量求解d的最大值,而支持向量的特点就是wTxi+b=1,因此我们的目标函数可以改写为
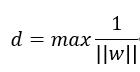
这等价于
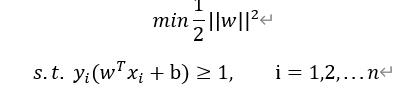
这就是SVM的数学模型。讲到这里,您一定明白了故事里大侠用的方法了(如下图),其实就是找到了一个超平面来分类,从魔鬼的角度看,看到的仍然是一条线分开了两种球。
对最优超平面的求解方法就是对目标函数转化为拉格朗日函数
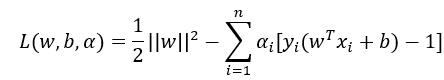
得到目标函数的对偶问题,然后基于KKT条件约束,利用SMO算法求得,这里我们不进行详细讨论。上面我们介绍的是数据完全线性可分的情况,即所有样本都正确划分,得到的超平面称为 硬间隔。但实际问题中可能并不存在这样一个超平面将数据完美分开(比如数据存在噪音时),此时我们就要找到一个软间隔,即允许一些样本不满足yi(wT xi+b)≥1的约束,此时就引入了松弛变量εi,优化目标就变为
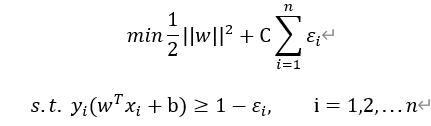
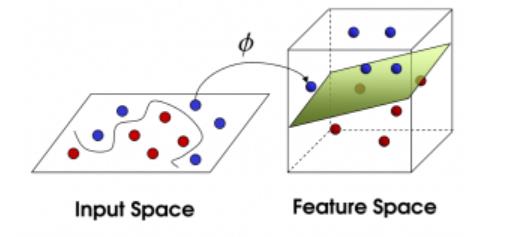
其中εi≥0,C≥0为惩罚因子,对于这个目标函数依然是利用拉格朗日函数和对偶问题求解。另一种情况是样本是非线性的,此时我们利用线性的f(x)=wTx+b没有办法处理,因此要利用核函数,在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优超平面。此时我们考虑的是f(x)=∑wiФi(x)+b,经过核函数映射后就变为f(x)=∑αiyi <Ф(xi),Ф(x)> +b(其中<Ф(xi),Ф(x)> 表示核函数)。常用的核函数包括线性核、多项式核、高斯核、拉普拉斯核、Sigmoid核等,区别仅在于映射方式的不同。我们这里虽然只介绍了二分类的情况,但与Logistic回归类似,利用我们上一讲介绍的“一对多”等方式就可实现多分类。同时,SVM算法也是一种既可以用于分类也可以用于回归的算法。理解了原理以后,下面我们来看看在sklearn中我们应该如何应用。
1.参数说明
在sklearn中有 SVM类来实现该算法,在做分类时,我们有SVC,NuSVC和LinearSVC三种选择,其中SVC和NuSVC方法类似,唯一区别就是损失函数的度量方式不同(体现在参数上就是NuSVC中的nu参数和SVC中的C参数),而 LinearSVC是实现线性核函数的支持向量分类,没有kernel参数,也缺少一些属性如support等。在做回归时使用的则是SVR。这里我们主要介绍和使用的是SVC,它有以下参数:
(1) C: 表示目标函数的惩罚系数,默认为1.0,C越大训练集准确率越高,但有时也容易发生过拟合;
(2) kernel:用来选择核函数,可选项为linear(线性核)、poly(多项式核)、rbf(径向基核即高斯核)、sigmoid(双曲正切核)、precomputed(要求特征属性数目和样本数目一样)或者自定义,默认为rbf;
(3) degree:使用多项式核函数时,给定多项式的项数,默认为3,其它核函数忽略此参数;
(4) gamma:代表rbf、poly和sigmoid核函数的系数,默认为'auto',即样本特征数的倒数;
(5) coef0:当核函数为poly或者sigmoid时,给定的独立系数b,默认为0.0;
(6) shrinking : 是否进行启发式;
(7) probability: 是否使用概率估计,默认是False;
(8) tol:训练结束要求的精度,默认为0.001;
(9) cache_size:缓存数据的最大内存大小,默认是200MB;
(10) class_weight:给定各个类别的权重,默认为1;
(11) verbose:是否详细输出训练过程,默认为False;
(12) max_iter: 最大迭代次数,默认是-1,该参数优先级高于tol,不论训练的标准和精度是否到达要求,都停止训练。
(13) decision_function_shape:多分类时选择的方式,有'ovo' (“一对一”)、'ovr'和None三种,默认为None;
(14) random_state:将训练集打乱顺序时使用的伪随机数生成器的种子,默认为None。
2.算法实例
我们这里使用的仍然是鸢尾花的数据集,并将参数decision_function_shape的值设置为'ovr',random_state设置为'123',其他参数值均为默认值。首先我们导入库和数据,将数据分成训练集和测试集,并对测试集进行预测,程序如下:
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn import svmiris_sample = load_iris()x_train, x_test, y_train, y_test = train_test_split(iris_sample.data, iris_sample.target, test_size=0.25, random_state=123)svclf = svm.SVC(kernel='rbf', decision_function_shape='ovr', random_state=123)svclf.fit(x_train, y_train)y_pre = svclf.predict(x_test)
所得预测结果如下图:
可以看到只有一个样本预测错误。然后我们查看一下在训练过程中那些样本作为支持向量,以及每一个类别支持向量的个数,同时输出预测准确度,程序如下:
print('支持向量为:', svclf.support_) #输出支持向量的序号print('各类的支持向量数:', svclf.n_support_)print('预测准确度:', svclf.score(x_test, y_test))
结果如下图:
寻两样本中总共有36个支持向量,每一类分别有4个、16个和16个,预测准确率为97.37%。SVM在中小样本量的数据上能得到不错的效果,同时利用支持向量进行求解,避免了“维数灾难”,利用核函数可以解决非线性问题,因此应用较广泛,但要注意如果特征数量比样本数量大得多,在选择核函数时要避免过拟合的问题。

关于我们
1)必须原创,禁止抄袭;
2)必须准确,详细,有例子,有截图;
注意事项:
1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。
2)邮件请注明投稿,邮件名称为“投稿+推文名称”。
3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

以上是关于换种视角看问题——支持向量机(SVM)的主要内容,如果未能解决你的问题,请参考以下文章