深入SVM:支持向量机核的作用是什么
Posted DeepHub IMBA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入SVM:支持向量机核的作用是什么相关的知识,希望对你有一定的参考价值。
您可能听说过所谓的内核技巧,这是一种支持向量机(SVMs)处理非线性数据的小技巧。这个想法是将数据映射到一个高维空间,在这个空间中数据变成线性,然后应用一个简单的线性支持向量机。听起来很复杂,但操作起来确实如此。尽管理解该算法的工作原理可能比较困难,但理解它们试图实现的目标却相当容易。往下读,自然就会明白了!
当数据是线性可分的:线性支持向量机
支持向量机是如何工作的呢?支持向量机可用于分类和回归任务,但是在本文中,我们将主要关注前者。让我们首先考虑具有线性可分的两个类的数据。我们将创建两个独立的点团,并使用scikit-learn对它们拟合成一个线性支持向量机。注意,我们在拟合模型之前对数据进行了标准化,因为支持向量机对特征的尺度很敏感。
X, y = make_blobs(n_samples=100, centers=2, n_features=2, random_state=42)
pipe = make_pipeline(StandardScaler(), LinearSVC(C=1, loss="hinge"))
pipe.fit(X, y)
plot_svm(pipe, X)
customplot_svm()函数的输出将在下面看到,它由相当多的matplotlib代码组成。
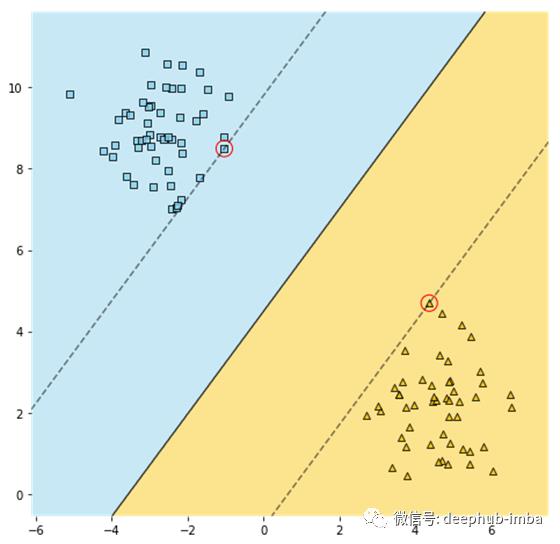
有许多行可以完美地将这两个类分开,确切地说,有无穷多行。SVM拟合的直线的特殊之处在于,它是两个虚线标记的直线之间的中间线,并且这条线距离两个类之间的距离近似相等。这样,支持向量机的决策线(标记为实黑线)离两个类的距离越远越好,保证了模型能很好地泛化到新的例子。
用红色圈出的直线边界上的观测称为支持向量,因为它们确定直线的位置。如果我们增加一些这条直线外的观察,它不会改变位置。
注:这是一个硬边分类的例子,这意味着不允许观察到边界。或者,我们可以做一个软边界分类:允许对频段进行一些加宽。这会减小异常值的影响,并且可以由LinearSVC()中的参数C控制:例如,我们原本将其设置为1,随后减少到0.1,将会导致更宽的直线,但其中会有一些观察值。不管怎样,这和我们的内容没有什么关系。
现实生活中的大多数数据集都不是线性可分的。让我们看看线性SVM是如何处理月亮形状的数据的。
X, y = make_moons(n_samples=100, noise=0.1, random_state=42)
pipe = make_pipeline(StandardScaler(), LinearSVC(C=1, loss="hinge"))
pipe.fit(X, y)
plot_svm(pipe, X)
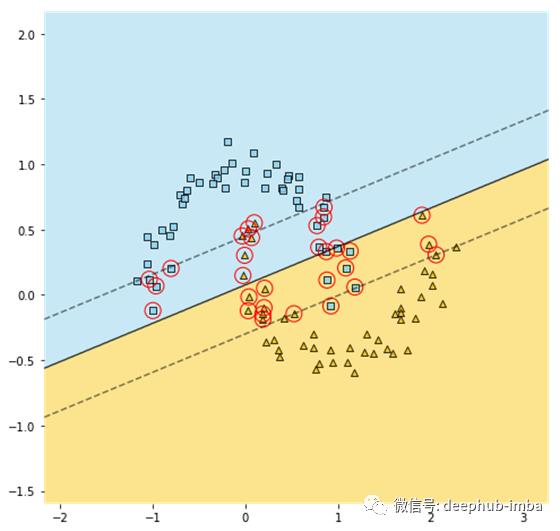
这看起来不太好,让我们想想该怎么处理这样的数据。
将数据映射到更高维度
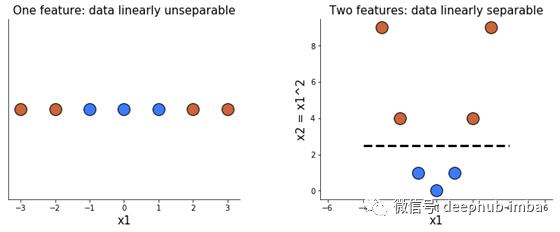
在我们讨论支持向量机内核和它们的作用之前,让我们先看看它们利用的一个思想:在高维空间中,数据变得线性可分的可能性更大。
下面两幅图清楚地说明了这一点。当我们只有一个特征x1时,我们不能用一条线把数据分开。加上另一个特征x2,等于x1的平方时,分离这两个类变得容易。
支持向量机的内核到底是什么?
那么,内核技巧是关于什么的呢?这只是一种向数据添加更多特性、希望使其线性可分的智能方法。因为添加它们将使模型时间复杂度增加,创作者利用一些神奇的数学特性(不在本文的范围),使我们能够获得相同的结果而模型运行速度并没有变慢。
两种常见的核是多项式核和高斯径向基函数(RBF)核。它们添加的特性的类型不同,让我们来看看它们的功能!
多项式核添加的多项式特征
创造更多特征的一种方法是在一定程度上使用它们的多项式组合。例如,有两个特征A和B, 2次多项式将产生6个特征:1(任何特征都为0次幂),A, B, A², B²和AB。我们可以手动使用scikit-learn库的PolynomialFeatures()很容易地添加这些功能:
X, y = make_moons(n_samples=100, noise=0.1, random_state=42)
pipe = make_pipeline(StandardScaler(),
PolynomialFeatures(degree=3),
LinearSVC(C=5))
pipe.fit(X, y)
plot_svm(pipe, X)
或者我们可以简单地使用多项式核:
X, y = make_moons(n_samples=100, noise=0.1, random_state=42)
pipe = make_pipeline(StandardScaler(), SVC(kernel="poly", degree=3, C=5, coef0=1))
pipe.fit(X, y)
plot_svm(pipe, X)
您可以自己验证两个实现生成两个大致相同的图形,有点像这样:
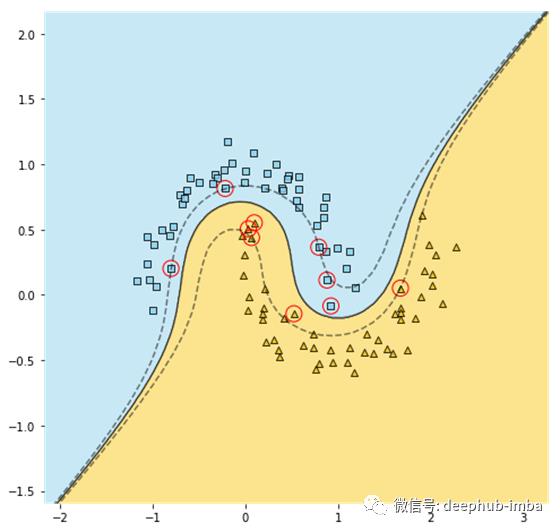
使用内核的好处是,您可以调整核的属性,从而增加数据在这个高维空间中线性可分的可能性,而不会降低模型的速度。
对于我们的月亮数据,很明显,从散点图可以看出3次多项式是足够的。但是,对于更复杂的数据集,可能需要使用更高的次数。这时内核技巧的威力可以更好地体现出来。
基于高斯RBF核的相似性特征
另一种向数据添加更多特征的方法是使用所谓的相似特征。相似特性度量现有特性的值与地标的距离。让我们实际一点:我们有一个只有一个特征的数据集,x1。我们想要创建两个相似特征,所以我们选择两个标准,即从我们的单一特征中选择参考值。比如-1和1。然后,对于每个x1的值,我们计算它与第一个地标的距离。这是我们新的相似性特征,x2。然后我们做同样的事情,比较x1和第二个参考值来得到x3。现在我们甚至不需要原始的特性x1!这两个新的相似特征使我们的数据很容易分离。
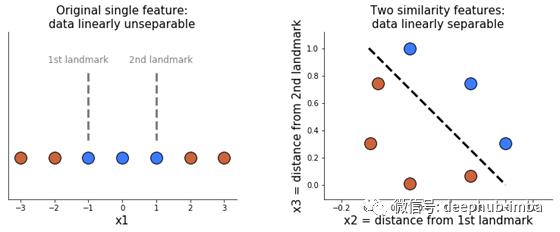
那么,如何计算每次目标点到参考值的距离呢?一个普遍的选择是使用高斯径向基函数RBF。定义为:
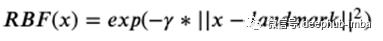
其中x是我们最初的特征,而参数γ是0.3。
例如,在我们唯一的原始特征上,第一次观察的得分为-3。我们计算x2=exp(-0.3 *(3 -(1))²)≈0.30,x3=exp(-0.3 *(3 -(1))²)≈0.01。这是右图最下面的两点。
在上面的例子中,我们幸运地选择了两个恰巧运行良好的参考。在实践中,一个特征可能需要很多参考,这意味着许多新的相似特征。这将大大降低支持向量机的速度——除非我们使用内核技巧!与多项式核类似,RBF核允许我们获得完全相同的结果,就好像我们在原始特征的每个值上都添加了一个参考,实现过程而不需要我们去做。让我们在月亮形状的数据上试试。
X, y = make_moons(n_samples=100, noise=0.1, random_state=42)
pipe = make_pipeline(StandardScaler(), SVC(kernel="rbf", gamma=0.3, C=5))
pipe.fit(X, y)
plot_svm(pipe, X)
决策边界看起来相当不错,但是您可能已经注意到一些分类错误的示例。我们可以通过调整参数γ的方式来解决这个问题,它作为一个正则化器——越小则决策边界越平滑,这可以防止过拟合。然而,在本例中,我们似乎还没有完全匹配,所以我们将γ增加到0.5。
现在所有的特征都正确分类了!
总结
支持向量机通过寻找离数据尽可能远的线性决策边界来进行分类。它们在线性可分离数据方面工作得很好,但在其他方面则经常失败。
为了使非线性数据线性可分(从而方便支持向量机),我们可以给数据添加更多的特征,因为在高维空间中,数据线性可分的概率会增加。
两种常用的新特征类型是现有特征的多项式组合(多项式特征)和从参考计算的距离,即一些参考值(相似特征)。
实际上,添加它们可能会降低模型的速度。
内核技巧策略利用一些数学属性来提供相同的结果并有效提高模型速度,就像我们添加了一些额外的特性,而速度上没有添加它们一样。
多项式核和RBF核可以分别添加多项式特征和相似度特征。
引用
Geron A., 2019, 2nd edition, Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems
感谢阅读!我希望你学到一些有用的东西,这将提高你的项目水平 以上是关于深入SVM:支持向量机核的作用是什么的主要内容,如果未能解决你的问题,请参考以下文章