AlphaQ-自研轻量级顺序型消息队列
Posted 点我达技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AlphaQ-自研轻量级顺序型消息队列相关的知识,希望对你有一定的参考价值。
前言
目前大热的微服务化,也迫使我们在构建服务的同时,越来越讲究服务间的解耦。而利用消息中间件是当前最常用的解决方案。那我们在利用消息中间件带来便利的同时,不可避免的会遇到两个问题:

1. 消息的顺序性
2. 消息的重复性
重复性问题的产生源于消息投递和消费时At least once的保障,可以通过业务幂等的方式来解决。本篇我们主要讨论怎么解决消息的顺序性问题以及介绍轻量级消息队列AlphaQ。
消息有序
消息有序指的是严格按照消息的产生顺序来消费。比如完成一笔点我达运单将产生了5条消息:创建、指派、到店、离店和完成。在某些场景下,依赖订单状态机的下游系统必须要保证有序消费才能完成内部流程。
怎么样保证顺序性?
假如生产者产生了2条消息:m1、m2,要保证这两条消息的顺序,应该怎样做? 我们首先来看下普通消息队列模型:
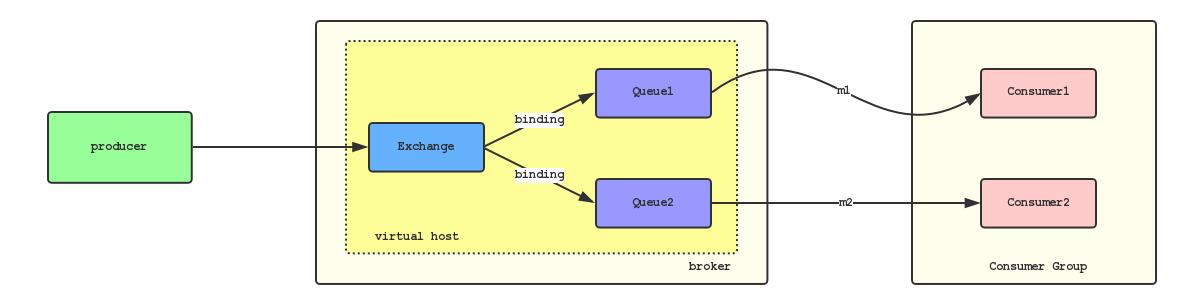
在上面的模型中,m1、m2有可能被分发到了两个不同Queue1,Queue又可能被不同集群中Consumer消费。因为每个Queue的消费进度及网络等原因,会导致m1、m2的消费先后顺序无法保证。
如果要保证两个消息的被顺序消费,那么需要m1到达消费者被消费且ack后,通知Queue2,然后Queue2再将m2发送到消费者。跨队列的协同需要一个协调器来解决问题,这并不是一个小的成本代价。那假设不引入协调器,如何才能在MQ集群中保证消息的顺序?
一种简单的方式就是将m1、m2通过binding来shard到同一个Queue上:
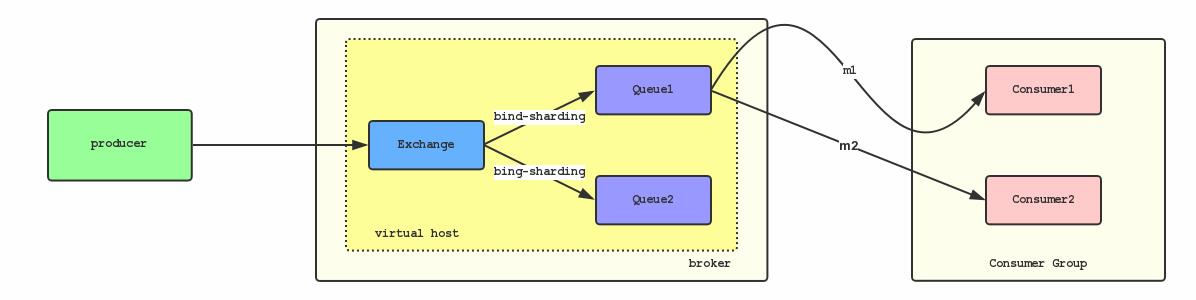
根据FIFO消费的原则,这样就一定程度上保证了消息发送的有序。这个模型也仅仅是理论上可以保证消息的顺序,在实际场景中可能会遇到下面的问题: 如果因为网络问题,如果发送m1耗时大于发送m2的耗时,那么m2就仍可能被先消费。即便是m1和m2同时到达消费端,由于不同机器对不同消息的的处理速度的差异,仍然有可能出现m2先于m1被消费的情况。
那为了解决这个问题,又想到我们可以保证每一个Queue只被一个Consumer消费,如下图所示:
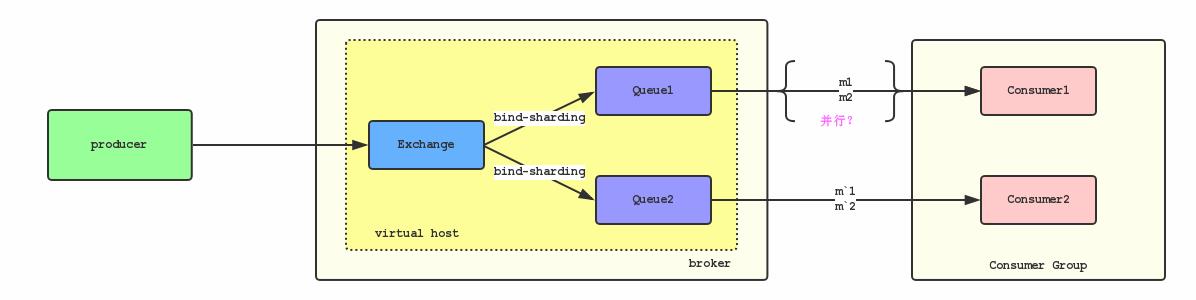
但在实际的使用场景中,为了保证消费速度,一般消息都是批量并行处理,那这样又出现另一个问题,Consumer对于不同消息的处理的速度也会存在差异,假设处理m2的速度比处理m1的速度快,那么也会乱序。
那么最终我们想到的方式,让Consumer串行消费Queue的消息:
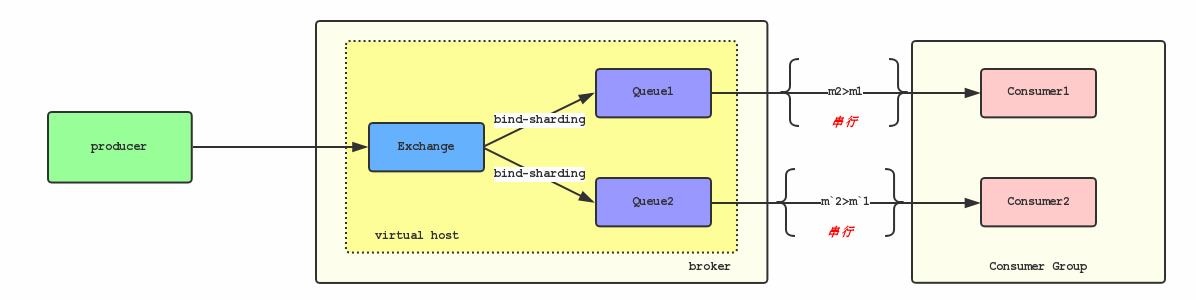
上面的图可以简化成:

这样的确可以严格地保证消息消费的顺序性 根据上面可以看到,要实现严格的顺序消息,简单且可行的办法就是:
保证 Producer2 - Queue - Consumer 是一对一对一的关系
一些常见的消息队列如RabbitMQ、RocketMQ或Kafka都通过这种方式实现了顺序型消息。但是这种串行结构依旧来带了新问题:
1. 并行度就会成为消息系统的瓶颈(吞吐量不够)
2. 异常处理(延迟重试)带来的流程阻塞
那么总结下来,如果我们需要实现一个高性能的顺序型消息中间件,还需要考虑几件事情:
1. 能否打破Queue和Consumer的一对一关系
2. 能否一定程度上解决Consumer只能串行消费的问题
顺序型消息
在说明问题之前,我们重新思考一下什么是顺序型消息以及顺序型消息的特性。
顺序型消息通常3会有个主体Subject(如:订单A,订单B),每个主体会产生一系列的事件(如订单流程:创建、指派、到店、离店和完成)。我们广播这些事件变成一系列消息(例:M1, M2, M3...),这些消息在关注顺序的消费场景中就是顺序型消息。
我们可以看出所谓顺序型消息,我们只需要关注局部有序:即Subject内的消息有序,不同Subject间的消费并不关注顺序性。由此,我们设想可否把Queue给分拆成:
1.一个主体队列Subject Queue:存放所有主体标识,如SubjectId。
2. 每个主体都对应有一个内容队列Content Queue:存放该主体关联的所有消息。
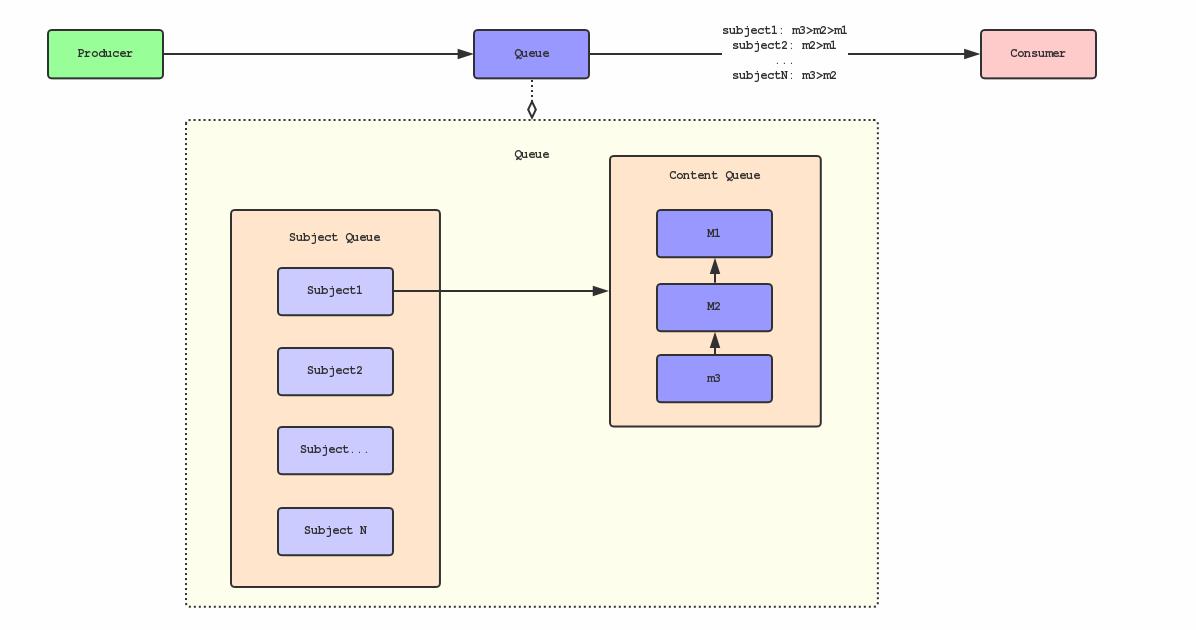
如上图所示,Consumer以Subject为维度并行地从Queue从消费消息,Consumer中的处理进程或线程有序处理某个Subject对应的Content Queue中所有的消息。
我们改造了Queue的结构,使用隔离的手段解决了消费的串行问题,并打破了Queue-Consumer只能一对一的关系,也是因为隔离使得Subject的异常处理(延迟重试)并不会对其他Subject的消息消费产生阻塞。
那么,看上去好像都搞定了嘛^.^!
等等,好像高兴得太早了!
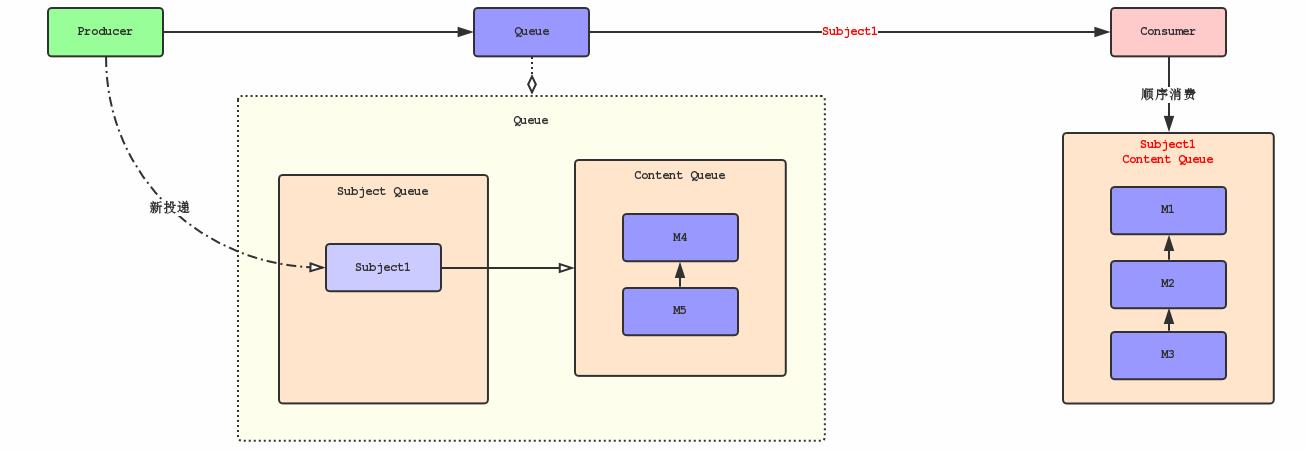
如图,假设Consumer正在消费Subject的消息M1,M2,M3,此时生产者又新投递了Subject的消息M4和M5。新投递的消息就有可能被不同Consumer或者相同Consumer的不同线程消费。那么还是无法完全保证消息的顺序性!
为了彻底实现消费顺序,我们需要重新制定消息的消费策略和内部处理逻辑。
消息消费将采用Pull的方式,Consumer先从Subject Queue中请求Subject,Subject Queue标记这个Subject在消费中,被标记消费中的Subject不会被其他的Consumer线程处理,Consumer依次从Content Queue中拉取消息M1、M2、M3进行顺序消费,当Subject Queue没有更多消息时,表示Subject在本次过程中已经消费结束,可以从Queue中移除!假设在Subject的消息被标记消费中,生产者投递了Subject的新消息M4和M5,Queue只需要把这些消息追加到该Subject的Content Queue即可,否则还需要将Subject添加到Subject Queue。
进一步,既然这个Subject Queue需要保证唯一性,所以,数据结构上更像是需要一个集合(Set)。但是,还需要保证一定的有序性,因为我们希望Subject间也应该大致能遵循FIFO,否则消息的消费时间无法得到保证!所以,也可以认为我们实际上需要的是Subject Sorted Set。
再进一步,我们前面说了对消费中的Subject打标记,但这些消息仍然占用了Subject Queue的空间,所以当Consumer来请求Subject时还需要过滤这些被标记的部分,这样无疑增加检索的复杂度!所以,再极限一点,可将待处理的和处理中的Subject Queue分拆成两个有序集合Todo Queue和Doing Queue。在投递新消息到Queue的时候,先去Todo Queue和Doing Queue里面检查一下Subject是否已存在,存在则只须追加消息到相应的Content Queue中,否则还需先将Subject添加Todo Queue里面。
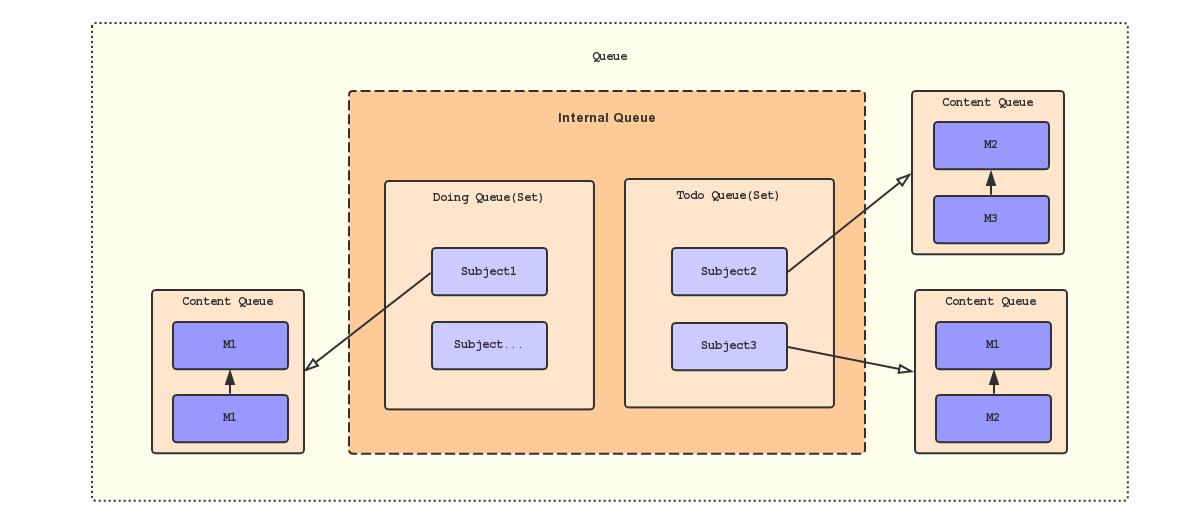
至此,虽然还有每次操作会涉及到内部多个队列的原子性问题还没有阐述,但一个“相对完整”的顺序型消息队列模型就已经完成了!
轻量级的AlphaQ
在以上的理论基础上,我们基于Redis + Lua Script实现了一套轻量级顺序型消息队列AlphaQ。
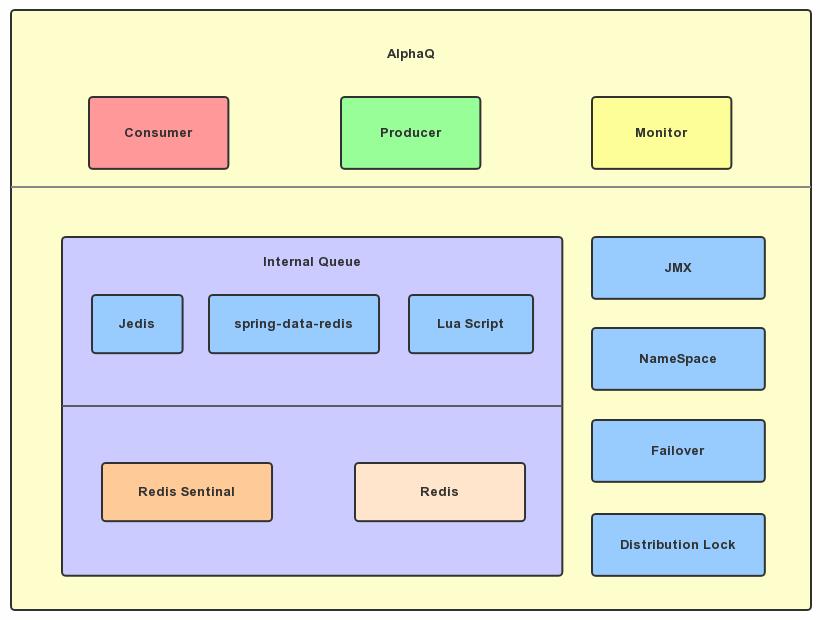
基本概念
内部队列(Internal Queue):是一个虚拟队列,负责协调待处理队列和处理中队列
待处理队列(Todo Queue):等待被消费的Subject队列,采用ZSET数据结构
处理中队列(Doing Queue):正在被消费的Subject队列,采用ZSET数据结构
消息内容队列(Content Queue):每个Subject的消息队列
消息权重(Priority):Subject的排序权重
命名空间(NameSpace):类似于Topic的功能,不同的队列使用Namespace进行空间隔离
生产者(Producer):消息的投递者
消费者(Consumer):一个实例或者进程,负责去Internal Queue中请求Subject,分发给工作线程Worker处理。等Worker职责完成后,向Internal Queue提交Ack指令。
工作者(Worker):负责顺序消费者某个Subject的Content Queue,通常是一个独立线程
为什么是Redis
单线程模型,使我们免于处理并发问题。
支持Lua Script且保证执行的原子性,完美地解决了前面提到的操作会涉及到内部多个队列的原子性。
Redis的数据结构多样性,如ZSET正好契合我们前面说的Subject Queue应该是有序集合的述求。
基于Sentinal的HA和持久化特性,保证了稳定性。
Redis的高吞吐量,下层基础决定了上层建筑,所以AlphaQ的吞吐是相当可观的,理论上可达Redis吞吐的1/6左右。
AlphaQ的特性
单个Queue的吞吐量高,生产业务压测读写QPS可达1W左右。
基于JMX暴露内部状态,便于监控管理。
灵活可定制的异常处理(延迟重试)机制。
依托于Redis的高可用。
实现了Producer - Queue - Consumer “N - 1 - N”的关系。
核心操作
1. Producer投递消息
往AlphaQ投递消息时,须先确认subjectId在Todo和Doing两个队列(其实是有序集合)中是否存在。若存在,则只将消息内容添加到Subject的Content Queue;否则,需先将subjectId推送到Todo队列。
local todoExist = redis.call('ZSCORE', todoSetKey, subjectId)
local doingExist = redis.call('ZSCORE', doingSetKey, subjectId)
if not(todoExist or doingExist) then
redis.call('ZADD', todoSetKey, score, subjectId)
end
return redis.call('RPUSH', contentQKey, content)
2. Consumer请求Subject
为支撑延迟消费的场景,AlphaQ先检查Todo队列的首元素是否满足消费条件。如果满足,则将该元素转移到Doing队列,并返回给Consumer;否则,返回无可消费消息。
local firstItem = redis.call('ZRANGE', todoSetKey, 0, 0, 'WITHSCORES'); --返回数组
if firstItem and firstItem[1] then
-- 校验消息是否已经到时间,用于解决延迟重试的问题
if (tonumber(firstItem[2]) > tonumber(nowTimestamp)) then
return nil
end
redis.call('ZREM', todoSetKey, firstItem[1])
redis.call('ZADD', doingSetKey, firstItem[2], firstItem[1])
return firstItem[1]end
3. Consumer消费Subject的Content Queue
Consumer请求得到Subject后,将Subject指派给Worker,由他来顺序消费Content Queue中内容。如果Content Queue已经没有更多消息,则从Doing队列中移除此subjectId,表示Subject的此轮顺序消费已经结束!Woker请求到消息时,其实消息还并未移出队列,需等待Ack后才会被移除,这样可以保证消息消费at least once。
local data = redis.call('LINDEX', contentQKey, 0)
if data then
return data
else
redis.call('ZREM', doingSetKey, subjectId)
end
4. 消息消费成功Ack
Worker消费消息成功后Ack,将该消息从Content Queue移除。
return redis.call('LPOP', contentQKey)
5. 消息失败处理策略
Worker处理消息失败后,在某些情况下需要重试,所以提供了相对灵活的重试机制,核心关注点即重试次数及重试时间。
local data = redis.call('LPOP', contentQKey)
if data then
local dataJson = cjson.decode(data)
local tryTimes = dataJson['tryTimes']
if not (tryTimes) then
tryTimes = 0
end
local result = false
if (tryTimes < tonumber(maxRetryTimes)) then
dataJson['tryTimes'] = tryTimes + 1 -- 修改尝试次数
local newData = cjson.encode(dataJson)
redis.call('LPUSH', contentQKey, newData)
result = true
end
-- 放回到待重试队列
redis.call('ZREM', doingSetKey, id) if (redis.call('LLEN', contentQKey) > 0) then
if not(result) then
nextScore = nowTimestamp
end
redis.call('ZADD', todoSetKey, nextScore, id)
end
return result
else
-- 如果没有数据则直接remove通知中id队列
redis.call('ZREM', doingSetKey, subjectId)
return false
end
消息流转
AlphaQ核心流程全貌:
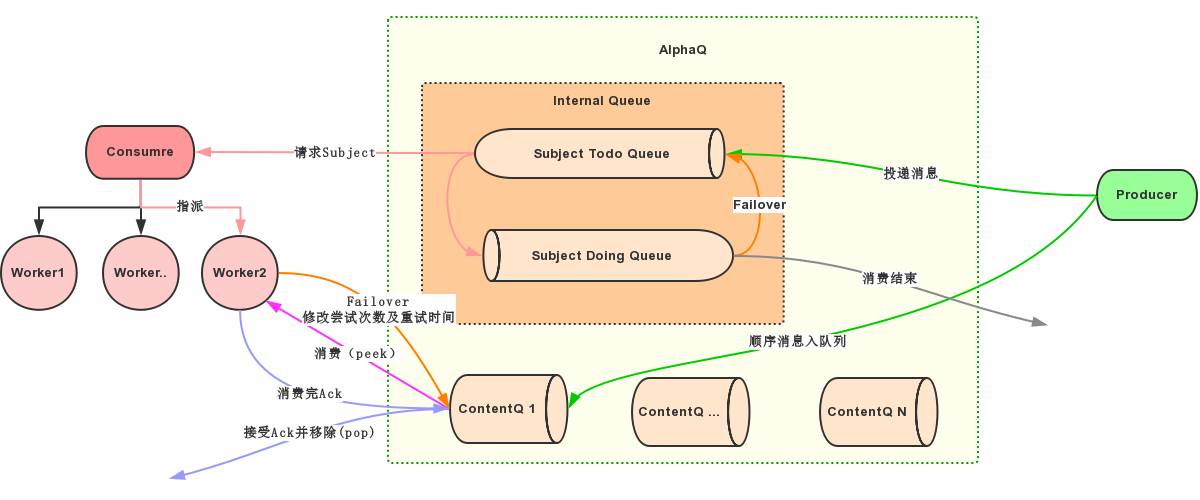
图中一样的箭头颜色代表一次原子性的操作。
需要完善的点
生产者和消费者需耦合同一个Redis,同时暴露了消息存储
当前版本并没有对消息做持久化,暂时只能一次性消费
目前还不支持多个Redis进行sharding,扩展还不够方便
因为Consumer也是单线程调度,所以单个Consumer的消费也存在能力上限,所幸设计上Consuemr支持集群消费变向规避了这个问题。
后语
前面我们提到了AlphaQ实现了“相对完整”的顺序型消息队列模型,因为模型本身还有一些问题没有完全解决。如多Producer生产密集型的顺序消息时,Producer在投递消息时,会因为网络等问题,导致写进Content Queue时就已经乱序。也许我们可以通过改变Content Queue的数据结构来达成目的,但又会引出很多的复杂性,难以避免额外的性能损耗!
是否一定要使用顺序性消息队列呢?
有些问题,看起来很重要,但实际上我们可以通过合理的设计或者将问题分解来规避。如果硬要把时间花在解决问题本身,实际上不仅效率低下,而且也是一种浪费。 所以从业务层面来保证消息的顺序而不仅仅是依赖于消息系统,我们也可以寻求的其他更合理的方式。
AlphaQ的未来
AlphaQ是在解决某一个特定问题衍生出的产品,在低密度的多Producer时也能做到很好的支撑,也还有一些需要完善的地方。未来可期的发展主要分两个方向:
1. 作为顺序消息调度器,消息内容队列支持自定义存储,以协助开发者自定义顺序消息队列
2. 实现或部分实现AMQP成为独立完整的顺序型消息中间件
AlphaQ近期有些细节调整后会开源,希望有跟多的人参与,给予意见或建议...
注解:
这里的指代的Queue只是个最小的集群概念,实际上可以用Virtual host或是Broker来指代。 ↩
Producer-Queue要保证一对一是因为消息从发送到持久化到Queue也会收到持久化周期和网络情况的影响,这个问题以后再讨论。 ↩
这里表述通常的意思是:不排除某些极端情况下,所有消息只有一个主体,这种场景不在这里的讨论范围之内。 ↩

点我达号

这个世界正在奖励默默努力的人
以上是关于AlphaQ-自研轻量级顺序型消息队列的主要内容,如果未能解决你的问题,请参考以下文章