聊聊消息队列到消息中间件
Posted 乖摸摸头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊消息队列到消息中间件相关的知识,希望对你有一定的参考价值。
任何技术演变都离不开业务发展和设计者重点解决的问题的推动,从早期狭隘的内存消息队列到现如今的独立的消息中间件,消息中间件在应用系统中承担了很重要的削峰填谷,系统解耦以及业务处理实时性的作用。这里就先八一八本人经历过的内存消息队列设计研发的场景和设计思路,即使到消息中间件时代,依然能从内部实现机制看到过去的思路。
大约从2006年开始,接触实时处理类应用,应用系统不再是准实时处理离线的文件数据,也就是从各个业务模块之间文件数据方式实现业务数据处理传递转变为实时消息请求。
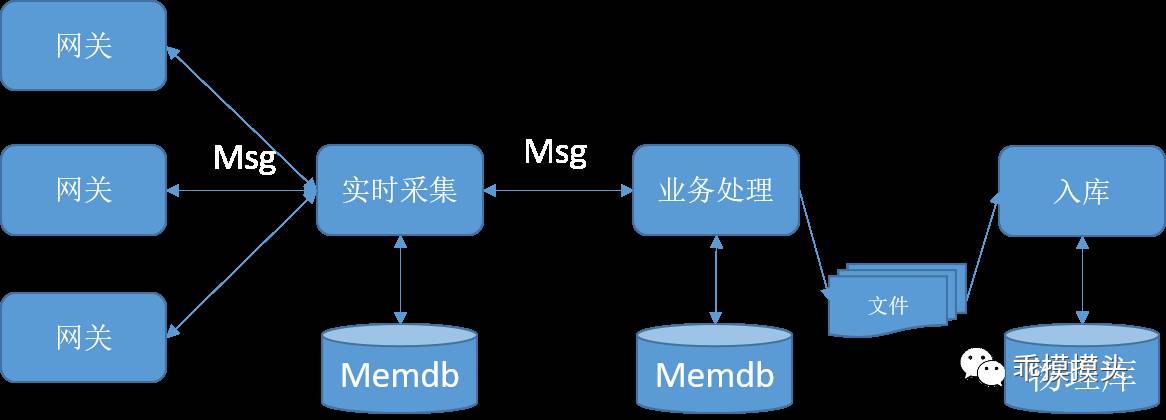
准实时处理应用结构:
消息处理模式增强处理实时性:
1.第一个阶段,内存消息队列
达到实时性处理能力的手段:
1. 基于TCP 之上 socket通信标准API,封装应用层协议
实时系统要解决分布式部署的能力,就需要涉跨主机应用通信。对于实时处理系统,跨主机之间通过封装客户端/服务端通信框架,来实现跨主机之间数据通信问题。
另外封装应用层协议,来实现数据传递的标准定义和序列化处理。
本文主要聊一聊消息队列,暂时此处不就通信框架展开说明。
2.主机单节点内部通信,通过内存消息队列封装来提升应用模块之间数据传递实时性
偏向底层一些计算机语言可以操作Unix/Linux的Posix标准提供的共享内存IPC。采用主机级独立管理的共享内存来封装消息通信队列,实现消息在模块间传递通信。
对于要实现模块间双向消息通信的要求,在消息内存队列结构定义如下:
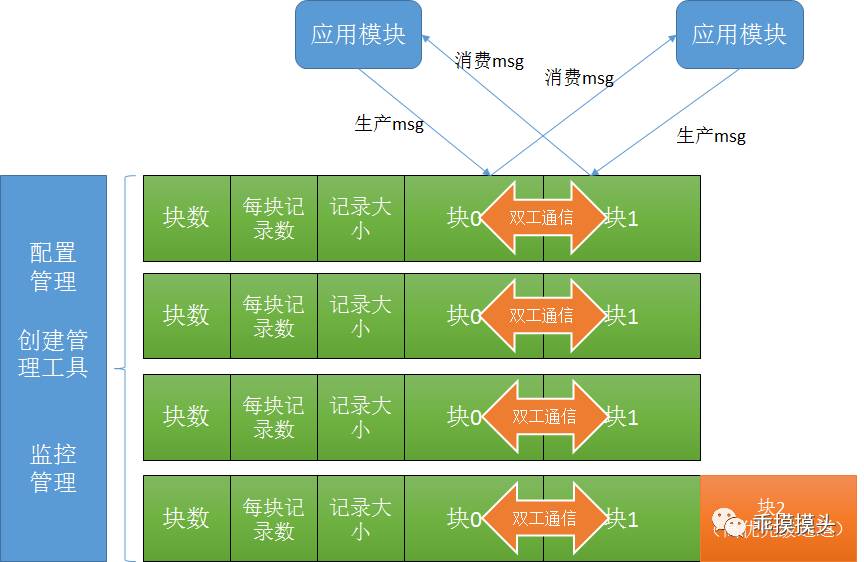
消息队列的封装思路:
1)内存结构的封装
内存队列采用Unix/Linux Posix标准的IPC共享内存实现消息数据存储的管理。
每个队列定义包括如下部分:
a.队列头部信息,包括队列块数(定义双工通信)、每块记录数、每块大小
b.队列块结构,每个块对应的队列内部结构为一个队列,具体结构定义如下:
支持FIFO先进先出的队列结构模式:
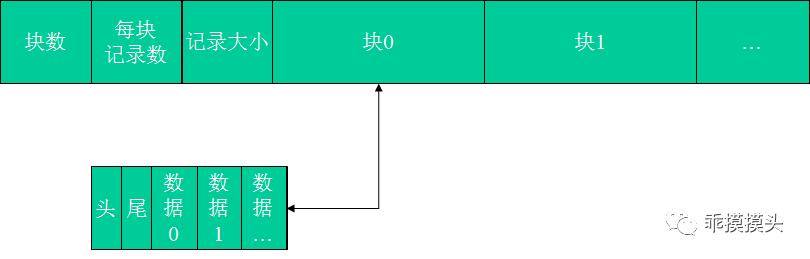
每个队列块为一个头、尾部滑动型队列构成。这种队列封装结构没有索引,支持FIFO先进先出的消费模式。
支持随机访问的索引结构队列模式(优势就是根据索引支持随机访问):
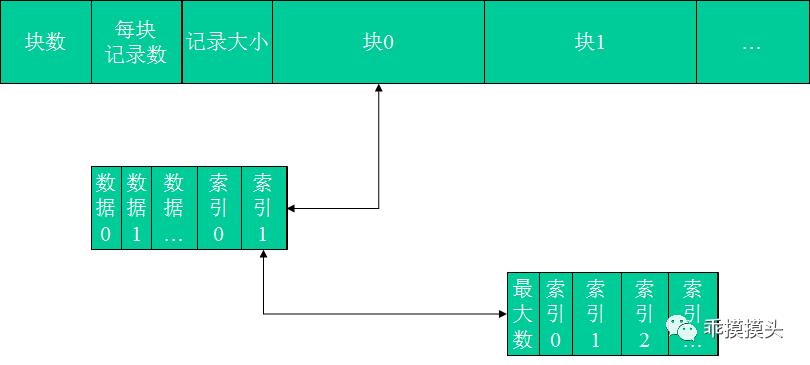
•块由滑动型队列(已排序),已使用索引,未使用索引构成
•索引包括最大索引数和索引
2.第二个阶段,解决内存消息队列持久化、在线扩容的问题
封装完成内存结构的消息队列之后,本主机的业务模块通过消息内存队列实现共享通信。
此时带来的问题:
1)消息队列共享内存结构,由于消息队列作为组件方式内嵌应用使用,应用进程退出或者主机意外宕机,会导致内存消息队列数据不可恢复。
2)消息队列内存共享结构,存在初始化定义大小容量的限制,在并发高峰期如何在线扩容消息队列内存容量成为应对高峰处理的关键。
解决设计思路,采用日志文件思路,全量+实时增量刷新:
1)针对内存消息持久化的问题
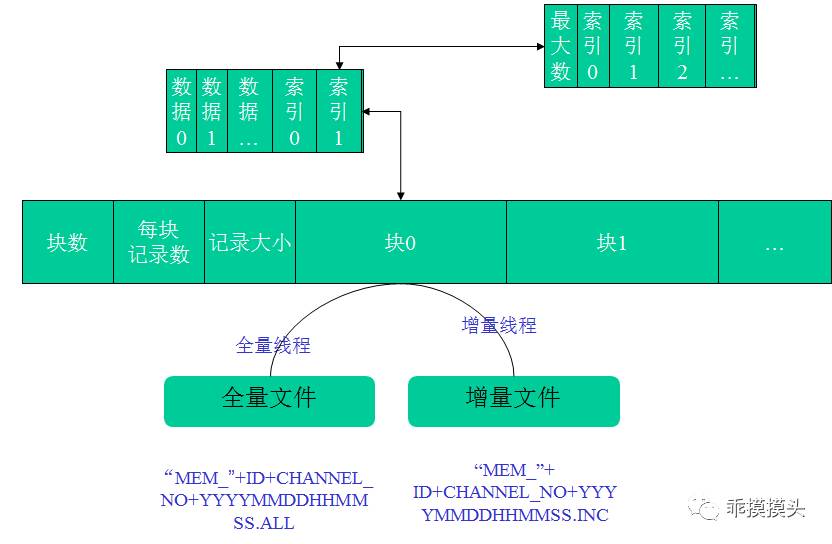
采用日志文件:
全量:间隔时间,使用子线程方式,对消息内存结构进行备份。
增量配置:间隔时间+操作次数,使用子线程方式
2)消息队列内存在线扩容(采用类似字符串空间自动扩容申请的思路)
内存消息队列存在一个高峰消息存储可能固定空间不够的问题,当内存消息队列达到一定的比例,如何自动增大和在低估的时候缩小内存占用空间,成为解决问题的重点。

通过在消息内存队列结构中新增状态信息,设计思路如下:
a. 状态为0,该内存队列对生产和消费者应用有效;
b. 状态为1,该内存队列对生产和消费者应用有效,进程正在申请第二块内存。
c. 状态为2,新老两个内存块同时有效,进程需要完成新块的attach切换。
3.第三个阶段,解决共享消息队列并发性能问题,同时通过增加业务级的队列映射关系,来实现类似消息中间件的Topic
采用共享内存IPC封装的消息队列充当了进程和线程之间共享处理数据的通道,但是共享必然带来并发控制问题。
通常针对共享资源并发最常用的控制手段就是锁的控制。
改善性能:
1)文件锁
通过判断文件是否存在来控制,如果存在则做一些事情,如果不存在做一些另外的事情。
文件锁可以设置阻塞和非阻塞两种类型,通常使用在防止应用被多次重复启动上面。
2)信号量作为锁
封装信号量锁机制,通过lock、unlock中封装PV原语操作来控制共享资源的并发。
信号灯的集合可以用来定义表示资源,通过维护下标来区分每个信号灯,如果要使用第i个的信号灯,就设置该信号灯值为-i,如果处理完成后释放资源,则+i。
共享消息队列就一开始就采用信号量封装锁机制来控制并发操作。
定义信号灯集,控制消息队列的块,实现数据更新时候的块区锁定。
尽管这个时间非常的短,但是在高并发的情况下,共享的并发控制依然会出现信号量操作的瓶颈。
优化思路:
借鉴Oracle锁机制:
–Oracle数据库封锁方式有三种:共享封锁(表级),独占封锁(表级) ,共享更新封锁 (行级)
–共享封锁
•共享方式的表封锁是对表中的所有数据进行封锁,该锁用于保护查询数据的一致性,防止其它用户对已封锁的表进行更更新
•共享该表的所有用户只能查询表中的数据,但不能更新,可以再施加共享更新锁
–独占封锁
用于封锁表中的所有数据,其它的用户不能再对该表施加任何封锁 ,但可以查询该表
–共享更新封锁
•对表的一行或多行进行封锁,因而也称作行级封锁
•确保在用户取得被更新的行到该行进行更新这段时间内不被其它用户所修改
分析参考之后,可以通过行级锁标记,细粒度控制到具体队列中某个位置信息的共享。性能比较的高。
标记锁中采用CAS乐观锁的算法,是一种交换和比较无锁算法,CAS的语义是“我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉V的值实际为多少”。
多线程并发处理共享资源时,如果使用标记锁,则会存在CPU到内存的值刷新问题。通常voliate变量机制能够支持这种强制刷新。
相比voliate,CAS优势当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
#if defined(__linux__)
typedef volatile int o_atomic_t ;
typedef o_atomic_t* o_atomic_p;
inline bool _check_lock (o_atomic_p pLockObject,int iOld,int iNew)
{
return __sync_bool_compare_and_swap (pLockObject,iOld,iNew)==false;
}
inline void _clear_lock(o_atomic_p pLockObject,int iValue)
{
return __sync_lock_release (pLockObject,iValue);
}
#elif defined(AIX)
#include <sys/atomic_op.h>
//sys/signal.h -> typedef volatile int sig_atomic_t;
typedef volatile int o_atomic_t;
typedef atomic_p o_atomic_p;//int*
#elif defined(hpux) || defined(__hpux__) || defined(__hpux)
#include <atomic.h>
typedef volatile uint32_t o_atomic_t ;
typedef o_atomic_t* o_atomic_p;
inline bool _check_lock (o_atomic_p pLockObject,int iOld,int iNew)
{
return atomic_cas_32 (pLockObject,iOld,iNew)!=iOld;
}
inline void _clear_lock(o_atomic_p pLockObject,int iValue)
{
atomic_swap_32 (pLockObject,iValue);
return;
}
#endif
CAS(比较并交换)是CPU指令级的操作,只有一步原子操作,所以非常快。而且CAS避免了请求操作系统来裁定锁的问题,不用麻烦操作系统,直接在CPU内部就搞定了
新增类似Topic机制,解决业务流向归类处理的问题
通过增加队列块类型和业务类型的映射关系配置,加载至缓存,用于应用进程连接队列的归类。类似现在消息中间件的Topic。
消息中间件时代:
消息队列作为应用模块间通信的手段之一,到后来已经不再局限于共享内存的方式。
消息队列到中间件转变:
1)消息队列作为通信手段不再通过共享内存受限在主机内部。逐步独立为中间件方式,通过网络通信的客户端封装,来实现消息的在中间的扭转。
2)消息队列的存储介质不再只是内存方式,开始与文件系统结合、内存与文件结合等方式管理消息经过中间件的存储。
3)基于消息队列提供了类似业务映射关系的Topic、分区分通道的能力,面向业务处理应用可以利用这些能力来实现业务层面有序消息的处理。
消息队列中间件时期,是分布式应用中一个核心重要的转变,有幸在技术的演进中都能参与其中。
后期再总结在消息中间件中的一些技术关键思路的认识。
以上是关于聊聊消息队列到消息中间件的主要内容,如果未能解决你的问题,请参考以下文章