360内部消息队列系统Qbus介绍
Posted 360云计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了360内部消息队列系统Qbus介绍相关的知识,希望对你有一定的参考价值。

女主宣言
做为每个互联网公司处理大数据的基础组件,诸如Kafka、rabbitMQ等一系列的消息队列系统越来越受到服务端程序猿的青睐,为了保持数据的持久性、可扩展性及高可用性,团队针对公司内部的现状以及业务特点,基于kafka深度定制了一款符合360内部特点的消息队列系统Qbus。今天小主就为大家奉上这篇关于消息队列的干货分享,希望能够帮助大家。
PS:丰富的一线技术、多元化的表现形式,尽在“HULK一线技术杂谈”,点关注哦!
Qbus简介
起源:
LinkedIn用于日志处理的分布式消息队列kafka;
需要对用户行为(登录、浏览、点击、分享、喜欢)以及系统运行日志(CPU、内存、磁盘、网络、系统及进程状态)进行实时处理;
传统队列太重、性能也跟不上;
特点:
消息都是持久的,保存在磁盘;
高吞吐量;
客户端维护消费状态;
分布式,生产者、消费者、服务端都可分布式;
支持订阅;
Push/pull方式;
作为普通的消息系统来使用(同步、异步消息)
日志收集收集业务日志进行实时分析,存储等
数据同步
使用订阅模式,同步数据到各个机房
监控服务
监控服务访问情况,防止用户对网站进行无限制的抓取数据
活动流跟踪等
Storm和Hadoop结合使用,在storm上消费数据,storm处理结果存储到QBus,数据可以异步复制一份到hadoop
与其它队列对比,相比gearman, JMS对比具有以下优势:
消息可持久化,不担心消息丢失;
分布式,服务器平滑扩展,业务无需感知;
无单点(多机房保证);
支持订阅,一份消息,多份接收(支持跨机房结构,便于并行处理);
高吞吐;
支持消息批量处理;
使用简单
Qbus原理介绍
原理图:
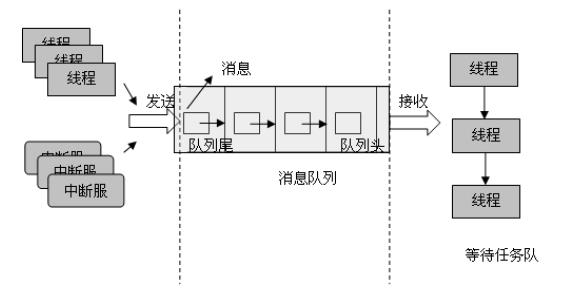
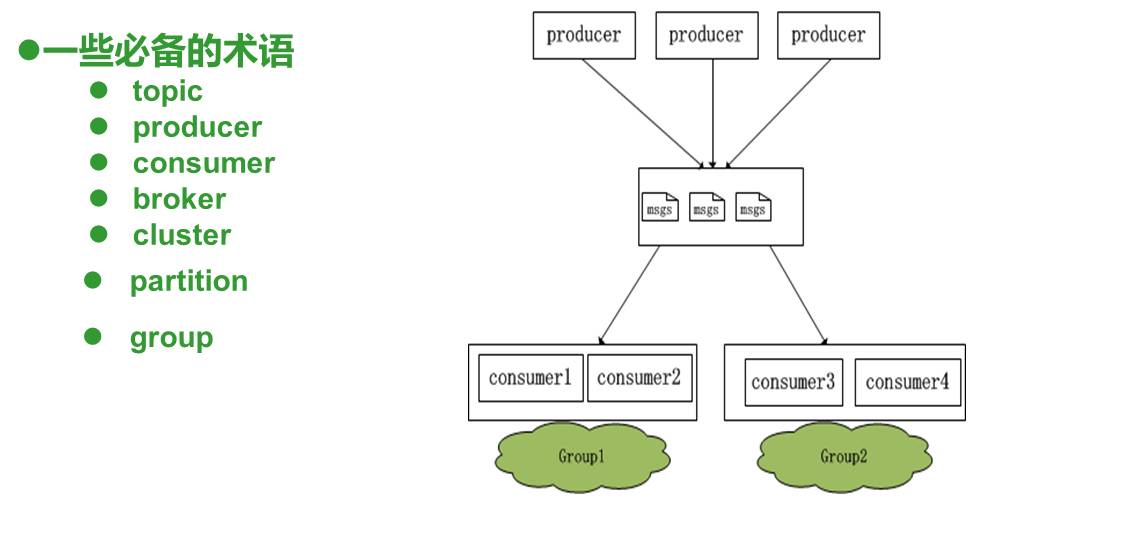
meta信息:
集群broker的信息,包含其ip:port
topic的存储的位置
partition的消费位置信息
所有consumer的信息
当值的coordinator
agent配置和存活状态信息
一条消息从生产到消费的路径:
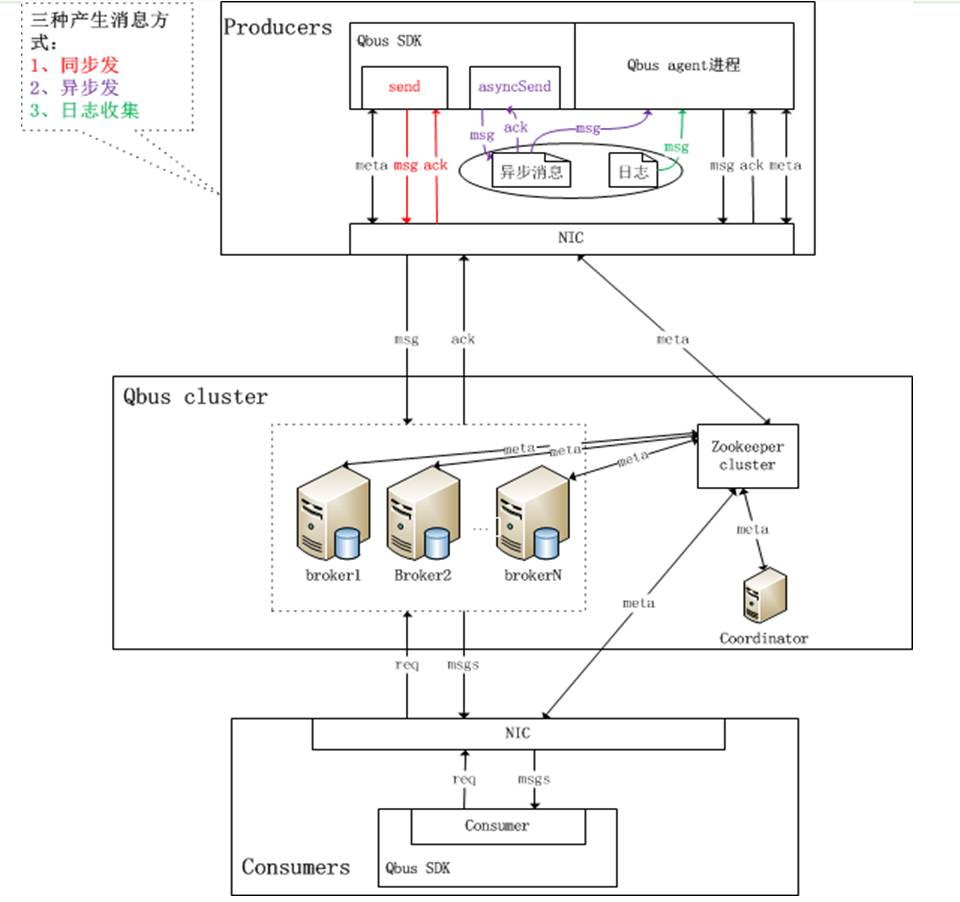
broker集群:
多个broker之间完全对等(可以平滑扩容)
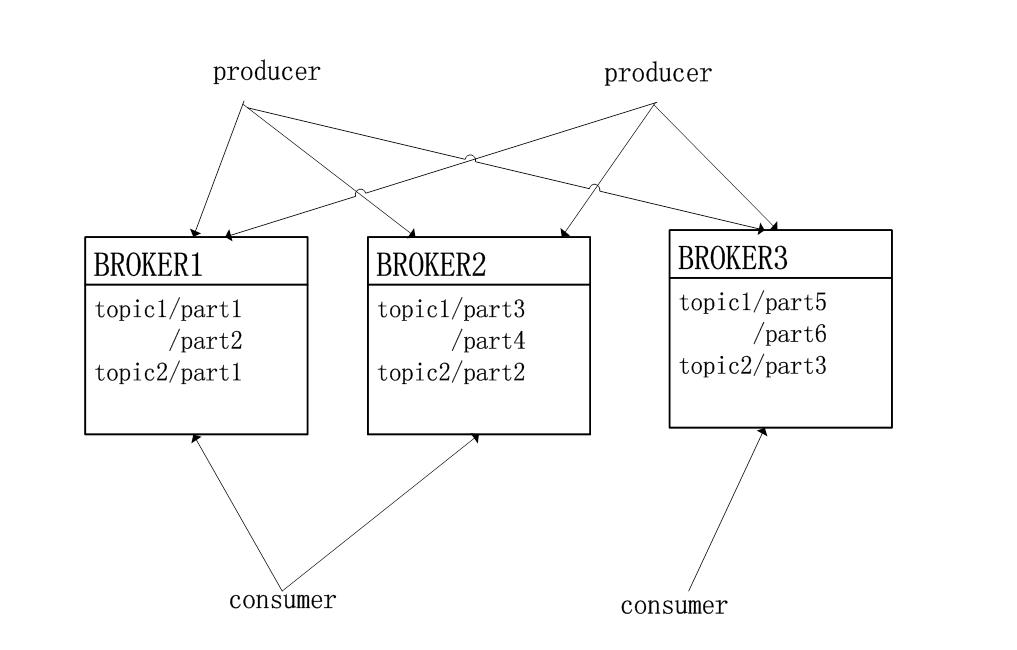
Broker存储:
每个partition对应一个逻辑log,由多个segment组成
新的消息追加到最后一个segment文件末尾
消费者可以根据offset回溯到消息存在的位置重新进行消费
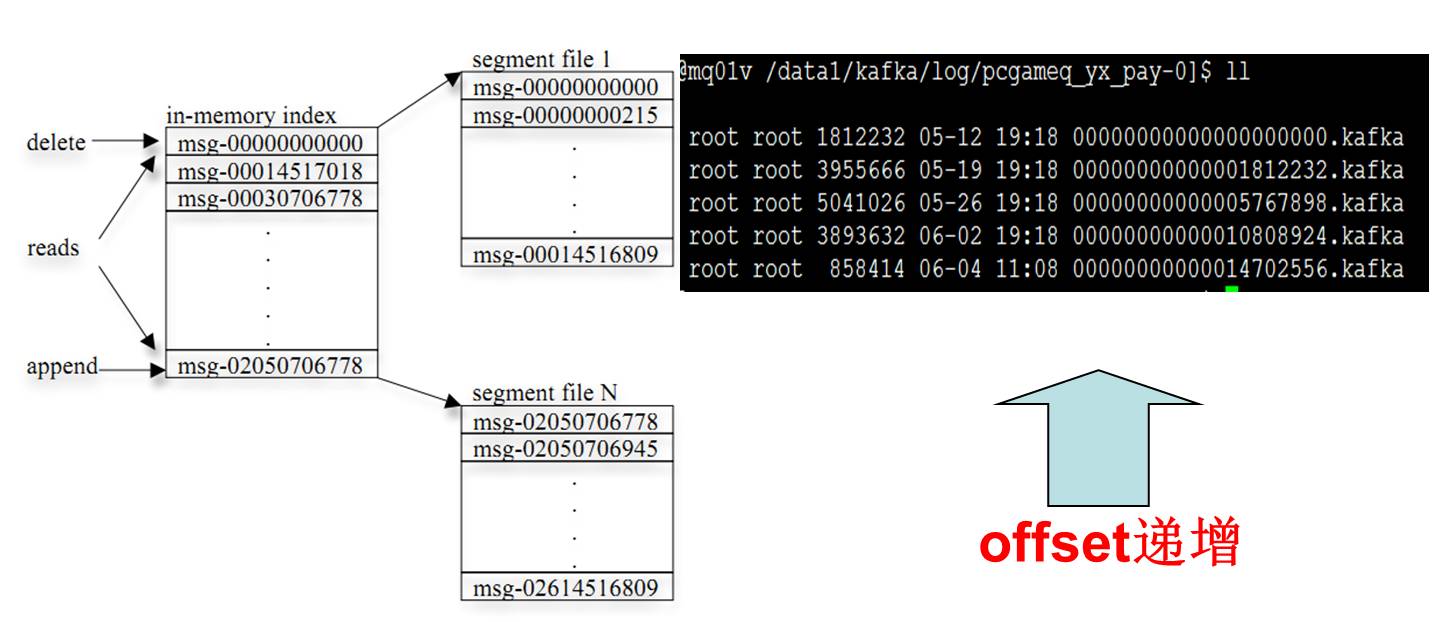
Broker高性能的关键:
利用文件系统缓存,用户空间不缓存消息
zero-copy(比read-send方式节省60 - 70%时间)
端到端的批量压缩
顺序读写磁盘效率很高
不关心消息的状态(是否被消费,消费到哪等等)
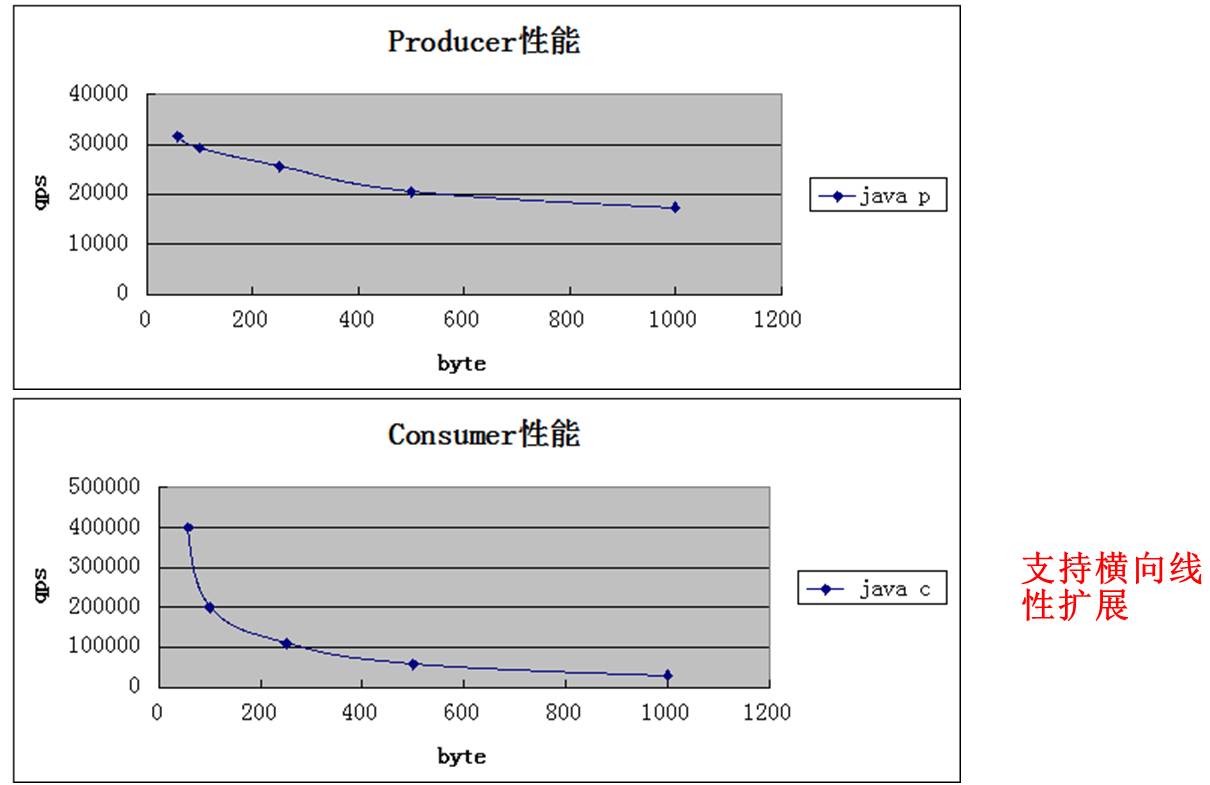
性能:
支持php、C/C++、java版本SDK,性能与消息大小的趋势图如下:
(2.40GHz CPU单核环境,broker同机房)
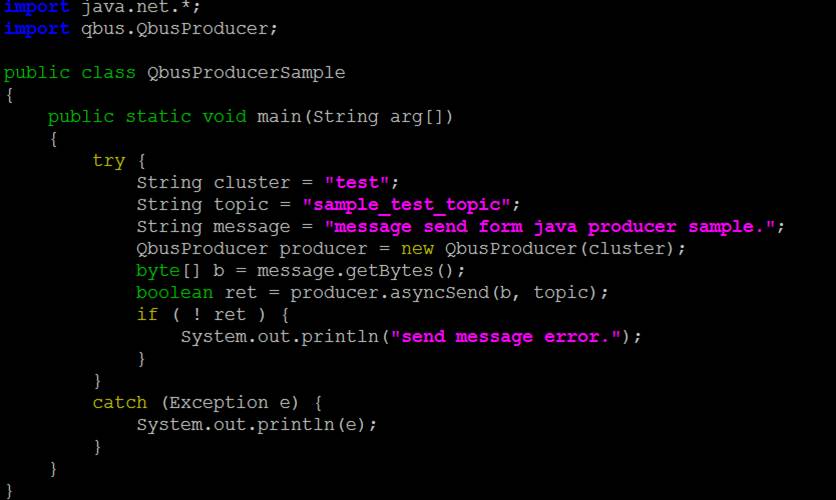
代码编写 java:
Producer:(异步)
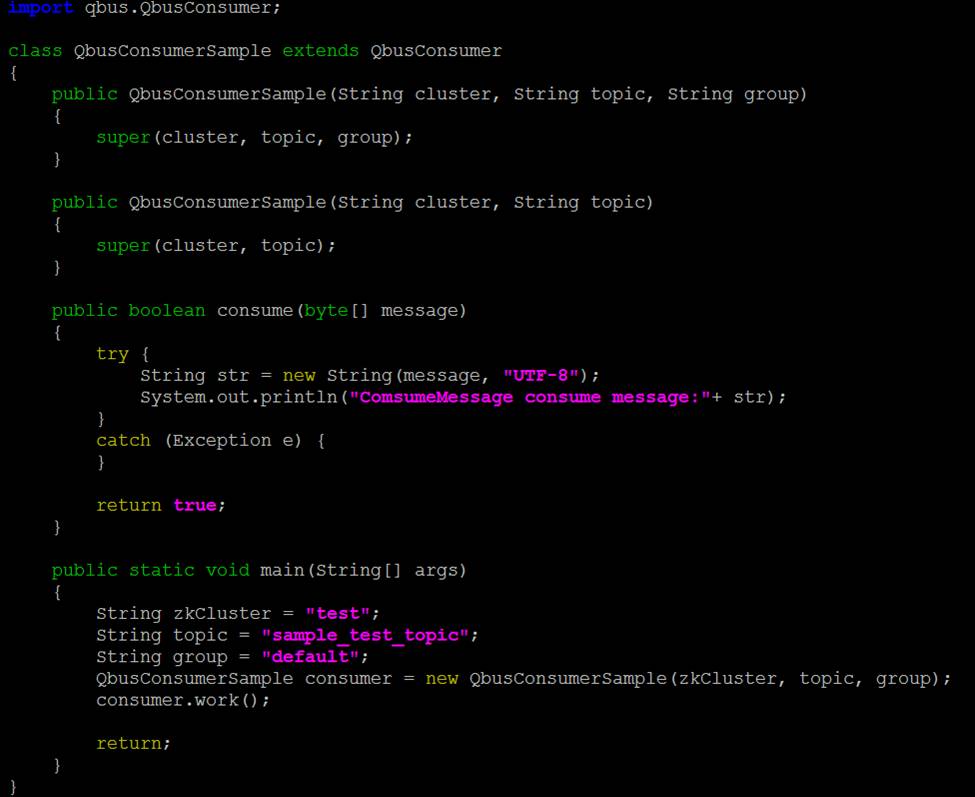
Consumer:(回调机制)
Producer:(同步、异步)
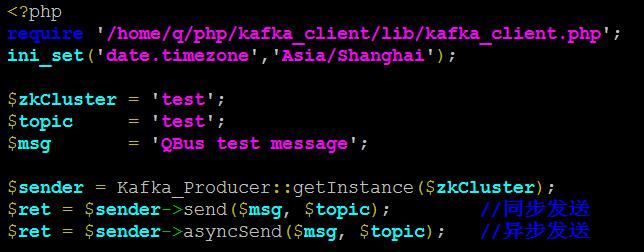
Consumer:(回调机制)
增加可靠传输请求类型,broker会对消息进行确认;
增加agent节点,用于异步消息收集和日志收集;
增加coordinator节点,独立消费分配逻辑,解决惊群效应,降低多语言开发成本;
根据QBus系统设计改进php sdk,并重写C/C++、java SDK;
增加消息自助管理平台,方便用户对消息进行管理;
以上是关于360内部消息队列系统Qbus介绍的主要内容,如果未能解决你的问题,请参考以下文章