消息队列和kafka二
Posted 大数据的那些事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了消息队列和kafka二相关的知识,希望对你有一定的参考价值。
一、Topic 和Partition
每个Topic可以理解为一个队列,每条消息必须指定要放在哪个Topic中。为了让Kafka的吞吐率线性提高,可以把Topic分成多个Partition,每个Partition对应一个文件夹,在这个文件夹中存储着这个Partition的所有消息和索引文件。当来一条消息的时候,这个消息会在对应的Partition的末尾添加一条记录,如下图所示。
kafka的partition有点负载均衡的意思,类似于mapreduce里面partition。上游来了一个消息,属于这个Topic的,消息里面存有key和value,这个Topic有很多partition,那具体这个消息传入哪个partition呢,也是根据key做一个哈希来确定的。每个partition之间的数据是不可以重复的。在每个partition内部是可以严格按先来后到保证你的顺序,但是在一个Topic的众多partition的全局有序是保证不了的。
通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前broker保存;可以将一个topic切分成任意多个partitions来容纳更多的consumer,从而有效提升并发消费的能力。
Kafka和其他消息队列不同的是,即使消息被消费,仍然不会被立即删除,日志文件将会根据broker中的配置要求,保留一定的时间之后删除,通过这种方式即释放了磁盘空间,又减少了消息消费之后对文件内容改动的磁盘IO开支。
consumer需要保存消费消息的offset,当consumer消费消息时,offset将会"线性"的往前推进,从而顺序的消费消息。当然consumer可以通过重置offset值的方式来按任意顺序消费消息。
consumer和producer的状态信息保存在zookeeper中,kafka集群几乎不需要维护它们的任何信息,故它们的客户端实现非常轻量级,随意离开也不会对集群造成额外的影响.
Producer的写和Consumer的读是可以同时进行的,这是一个异步的方式。对于kafka来说,Producer和Consumer都是一个客户端,Producer不管这个消息没有人读都尽情的往里写,Consumer不管有没有生产者往里面写数据都尽情的往里读。这就相当于一个kafka集群把prodecer和Consumer这两端进行了异步解耦。
kafka的下游会有很多消费者,每一个消费者的消费进度不一样,就像看书,有人看书快,有人看书慢,每个人看书的位置(offset)是不一样的。如果要把每个人的偏移量这个数据交由kafka来记录的话,势必会造成kafka集群的复杂和性能的低下,所以kafka就把更多的主导权交给了消费者,由消费者来保存各自的offset偏移量。
磁盘上存储的消息格式如下:
message length:4 bytes(value: 1+4+n) 消息的长度
"magic" value:1 byte 交换码
crc:4 bytes 校验码
payload:n bytes 真实数据
在kafka内部,为了让消息能够更好和文件系统进行一个整合,那不可能是要把数据按照明文的方式去传输,肯定要把你的数据转换成二进制的形式,这样会有利于减少服务器端的开销并且提高IO速度。
Producer有同步和异步这两种模式,这个由produer.type这个参数来进行控制,值为sync时表示同步,为async时表示异步。同步就是实时发送,数据一来就马上发出去;异步就是当message积累到一定的数量或者等待一定时间后才能发送。
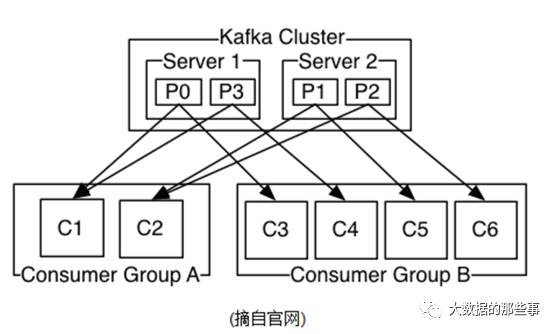
同一Topic的一条消息只能被同一个ConsumerGroup内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。
这是Kafka实现消息的广播和单播的关键。要实现广播,只要每个Consumer有一个独立的Group即可。要实现单播只需所有的Consumer在同一个Group里。
Kafka可以同时提供离线处理和实时处理。根据这个特点,可以将Kafka和Storm以及Hadoop同时对接。使用Storm对消息进行实时处理,使用Hadoop进行离线处理,将数据实时备份到另一个数据中心,这三个操作可以同时进行,只需要保证它们所使用的Consumer属于不同的Group即可。
每个Consumer属于一个特定的ConsumerGroup,可为每个Consumer指定group name,若不指定则属于默认的group。
如上图所示,有两个组A和B,kafka集群上有两个server,这每一个server代表一个broker,共有四个partition,左边的组A中有两个Consumer,右边的有四个Consumer。组B里面刚好有四个Consumer对应着四个partition,这是一一对应的关系,但是由于组A里面Consumer 的数目是小于partition总数,所以肯定会存在一个Consumer 对接多个partition的情况,但是不管怎样一个Group得到的是一个完整的数据。
如果一个Topic包含了多个partition,那最多有多少个Consumer同时在一个Consumergroup里面可以进行对这个Topic进行消费呢?有多少partition就最多有多少个Consumer,如果在一个group中Consumer过多的话,是不行的,因为每一个partition只能同一时间服务于一个Consumer。
partition内部真正落地数据的地方叫segment。假设一个partition对应着一个文件,这个文件是永远不断的增长的,会非常大。

对于这个大文件,想查某一个数据怎么查呢?最简单的方式就从前往后顺序查找,文件大的话这个顺序查找是非常慢的。kafka内部是这样做的,用多个segment把这个大文件给拆分,比如说先写1号segment,写完之后再写2号segment,然后写3号。这个1号segment,2号segment,3号segment,大小基本上是一致的,随着数据的不断积累,segment也是不断的增多,越早的数据存到了前面数字越小的segment里面去,越新的数据就存到了数字越大的segment里面去。
想查一个数据时,你知道这个数据的offset,但不知道该offset是具体在哪一个segment上,这个时候用二分法定位到某一个segment里面,然后通过顺序查找的方式定位所需查找的数据。
以上是关于消息队列和kafka二的主要内容,如果未能解决你的问题,请参考以下文章