互联网金融消息队列ZeroMQ
Posted HelloWorld搬运工
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了互联网金融消息队列ZeroMQ相关的知识,希望对你有一定的参考价值。
之前对消息队列服务中间件进行了对比,具体可以参看。
一般互联网公司都使用消息队列来实现系统解耦,提速,广播,流量削峰等应用场景。
ZeroMQ,低延时、高性能特性,被应用于实时性要求高的系统解耦。
1、什么是ZeroMQ:
据官方文档介绍,ZeroMQ是一个可伸缩的分布式或者高并发的异步网络消息库。不同于其他的服务,例如RabbitMQ等消息队列服务,以一种可独立运营的服务存在,ZeroMQ是一套高效的socket library,是对BSD socket进行的上层封装。在传统的BSD网络开发模型中,采用的是socket与socket之间的消息传输,即1:1的消息传输链接,在ZeroMQ中是node与node之间的消息传输,node之间存在多条数据链接,即N: M的消息传输链接。ZeroMQ在底层实现了关于进程通信、网络通信、线程通信等各种细节的封装,让开发者更多的关注应用层的开发。
简单来说,ZeroMQ是对Socket进行了封装的lib库,在使用的时候不用搭建队列环境,只需要引入lib包,然后在生产方和消费方调用API就可以。
2、ZeroMQ的主要特点
I/O操作属于后台异步操作,同时采用的是无锁数据结构,提高应用的高并发性;
存在断线重连机制,Server、Client启动的无序性;
消息的消费者处理速度比较慢时,会导致消息的生产者阻塞或者,可以在使用过程中进行设置;
消息内容可以使用任何的格式,框架本身不对消息格式做任何的限制;
3、ZeroMQ的基本使用模型
ZeroMQ提供了三个经常使用的基本模型,分别为:Request—Reply、Publish—Subscribe、Parallel PipeLine三种工作模型,通过这三种工作模型可以衍生出很多的使用模型。下面分别对这三种模型进行简单的介绍:
1)Request—Reply模型
Request—Reply模型与传统的BSD网络开发模型类似,也就是俗称的“应答模型”,具体模型如下图所示
Server代码如下:
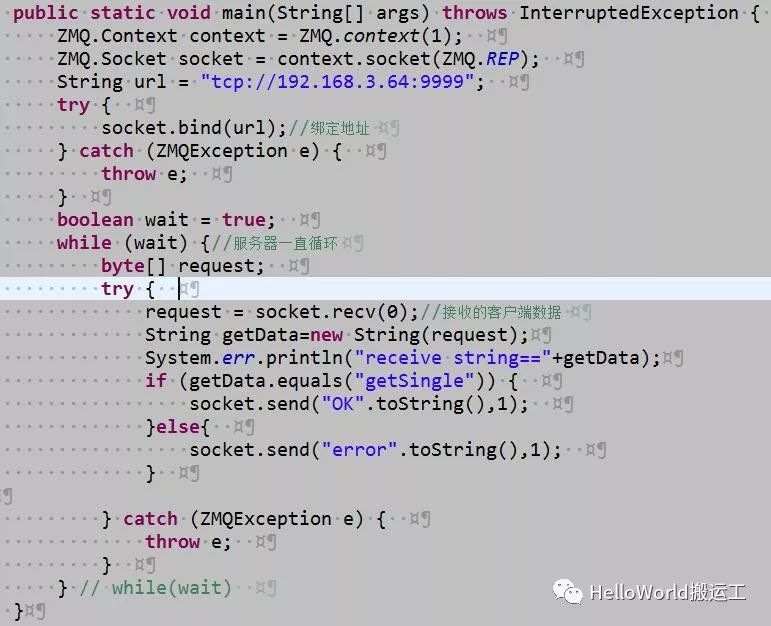
Client代码如下:
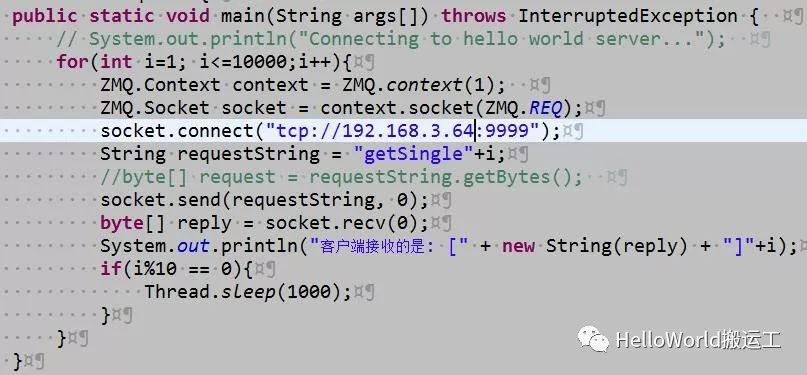
在使用该模型过程中存在几个注意事项:
必须采用严格的发送——接受的顺序,否则会导致此次的发送或者接受失败;
区别传统的BSD开发,Server先启动,Client再启动的流程,在ZeroMQ中Server与Client启动顺序没有要求;
消息内容的无关性,ZeroMQ不关心传输数据的具体内容,由发送或者接收方负责编码或者解析;
发送频率受端口链接数限制,如果超过限制会导致jvm停止
2)Pub-Sub模型
Pub-Sub模型是一个服务器将消息发送给多个客户端,类似于群发短信的业务场景
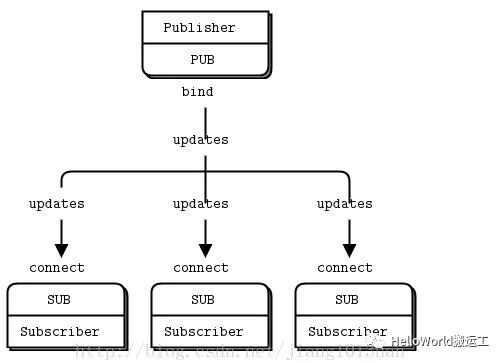
Pub侧代码如下:
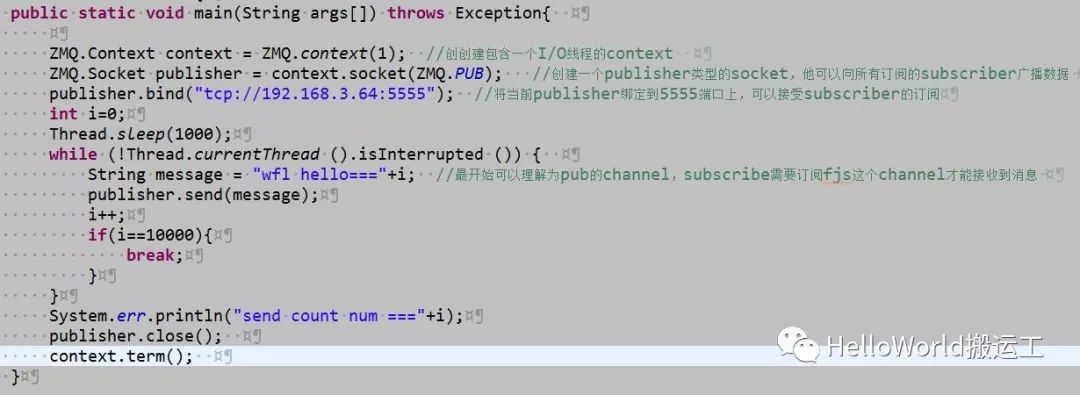
Sub侧代码如下:
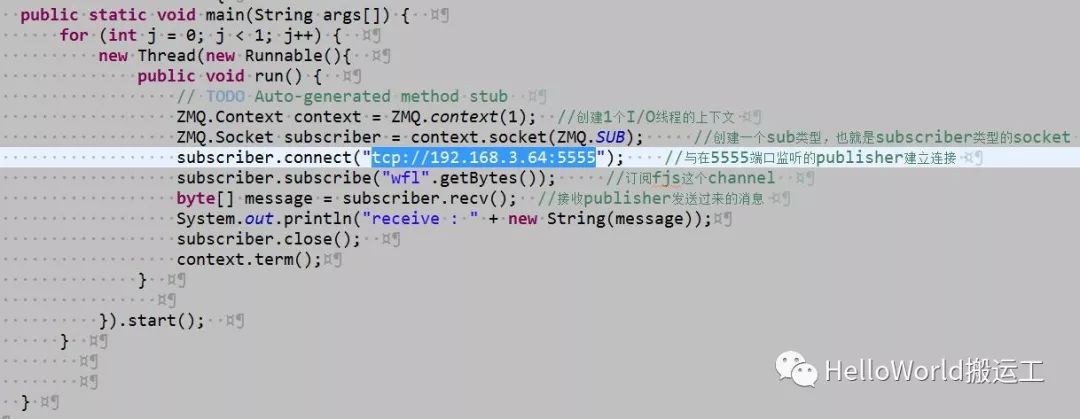
Pub-Sub模型使用过程中的注意事项为:
需要在服务中显式设置服务是PUB还是SUB,即在服务中需要明确在系统中扮演的角色;
扮演PUB角色的服务,不可以调用zmq_recv,扮演SUB角色的服务,不可以调用zmq_send角色,否则会导致服务出错;
PUB允许存在多个SUB服务,SUB服务也允许从多个PUB中订阅数据;
使用这种模型最适合的场景为:SUB在启动时,不关心PUB已经发送的数据内容;
PUB在没有接收到SUB连接请求的情况下,PUB会丢弃全部的数据;
如果SUB的处理效率比较慢,PUB侧会维持消息队列;
根据设置的过滤条件的不同,过滤条件生效的位置不同;
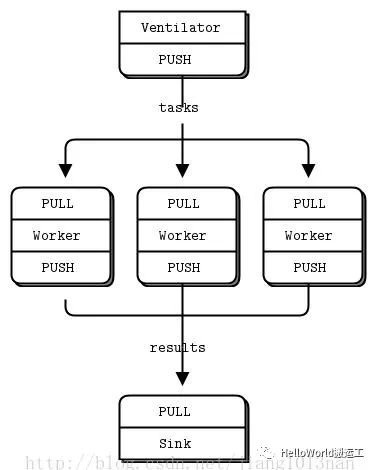
3)Parallel PipeLine
Server端作为Push端,而Client端作为Pull端,如果有多个Client端同时连接到Server端,则Server端会在内部做一个负载均衡,采用平均分配的算法,将所有消息均衡发布到Client端上。如果有多个Server端同时连接到Client端,这里Push与Pull之间的对应关系是多个Push角色对应一个Pull角色,在ZeroMQ中,给这种结构取的名叫做公平队列,这里也就是说将Pull角色理解为一个队列,各个Push角色不断的向这个队列中发送数据。与发布订阅模型相比,推拉模型在没有消费者的情况下,发布的消息不会被消耗掉;在消费者能力不够的情况下,能够提供多消费者并行消费解决方案。该模型主要用于多任务并行处理。
Push端代码实现:
Pull端代码
注意事项:
PULL端可以过滤接收到的消息,在设置connect参数的时候在端口后边添加过滤字符串。
以上是关于互联网金融消息队列ZeroMQ的主要内容,如果未能解决你的问题,请参考以下文章