58分布式消息队列WMB设计与实践
Posted 58架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了58分布式消息队列WMB设计与实践相关的知识,希望对你有一定的参考价值。
背景
为了能够承载58业务的快速扩展及海量的用户访问,分布式系统已经成为公司一种主流架构设计。而消息队列是大型分布式系统中不可或缺的通信桥梁,在分布式系统解耦、异步通信、事件通知、流量削峰等业务场景中起着重要作用。
现常见的开源消息队列有Kafka、RocketMQ、RabbitMQ等,都有着不同的使用场景和特点。RabbitMQ采用erlang 语言开发,具有较高的可靠性,但是性能较差;kafka突出的特点是高吞吐量,但不能保证消息投递的低延迟,多用于日志数据的上报;当前比较流行的RocketMQ,在可靠性和高吞吐特性上做了平衡,但开源版本不支持一主多从数据的强一致性及主从自动切换。在58业务发展之初,开源的MQ 尚不成熟,根据当时公司技术栈特点,参考了ActiveMQ设计,自主研发了一套功能单一的消息队列ESB,但不支持所有消息的持久化,可靠性较低,静态配置不易扩展、客户端故障消息丢失、buffer堆积等问题层出不穷。
WMB是在兼容ESB基础上进行了两阶段大的重构开发,第一阶段重在提升服务可用性,完善服务端存储结构、添加了注册中心、Collector收集器、可视化管理平台等模块,在此基础上丰富了消息发送/订阅方式、配置动态扩展、可视化细粒度立体监控、消息查询等功能,并对多语言客户端(Java、php、C/C++、Go)提供了支持;第二阶段重在提升服务可靠性,引入一致性算法Paxos,实现了主从强一致性、主从秒级自动切换等能力,该版本能够同时满足高数据可靠性,且不失高可用和高吞吐的场景。
整体架构
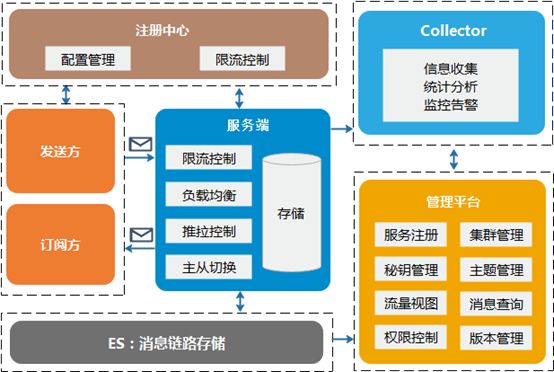
图1 整体架构
消息发送方:提供了高并发的异步发送,以及多种不同可靠级别的同步发送方式;
消息订阅方:提供了推送、拉取订阅方式,分别保证“至多一次”与“至少一次”消息投递。另外还支持回溯消费、延迟消费、定时消费、重试消费、广播消费等灵活可靠的消费方式;
服务端:对接收到的消息多副本持久化存储,并提供消费队列动态负载均衡、毫秒级延迟推送、主从消息强一致、主从秒级自动切换等能力;
注册中心:负责客户端与服务端配置管理,从而支持集群动态扩/缩容、快速增删主题、发送方秒级限速控制等功能;
Collector收集器:负责收集服务端定时上报的主题收发量、消费进度、在线状态等信息,并提供实时告警功能;
可视化管理平台:为管理员和业务提供了资源管理、权限控制、流量实时展示、消费进度查询等完备的运维平台,同时支持消息模糊查询、全链路消息轨迹跟踪等功能方便排查问题。
集群架构
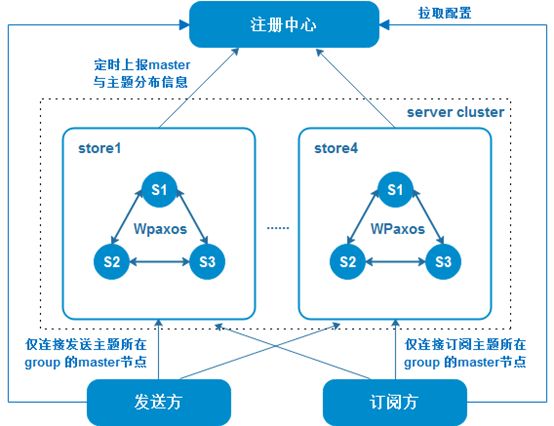
图2 集群架构

表1 主题分布
每个服务集群有多个store单元,非顺序消息通过轮询方式均匀发送到每个store;
每个store部署多个数据强一致的server节点,每个server节点包含多个相同的Paxos group;
每个Paxosgroup的master节点可能为store内的任何server节点,同store的server节点互为主备,每个group有独立的一套存储单元;
集群下每个主题隶属于其中某一个Paxos group,由Paxos group的master节点发起消息的批量有序commit;
WMB采用的Paxos算法组件为WPaxos,参考了微信开源生产级Paxos类库PhxPaxos,并做了调整和优化,采用Java开发实现。
下面介绍下,在以上架构基础上WMB如何保证服务的高可靠、高可用与高性能。
高可靠性
发送可靠性
WMB客户端提供了高并发的异步发送,以及多种不同ack级别的同步发送方式,消息发送过程如下图所示。
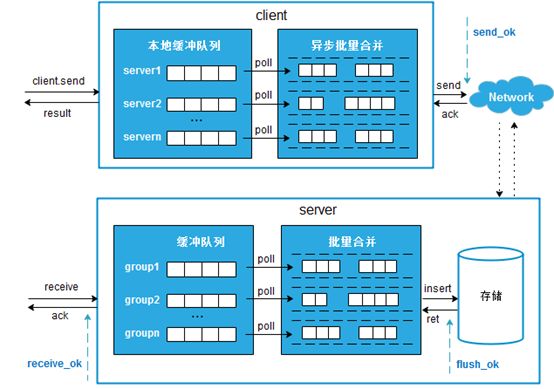
图3 消息发送
业务调用客户端发送接口投递消息,客户端根据主题消息顺序性要求,选择主题所在集群某一个server节点发送消息。对于客户端发送的每条消息,正常情况下服务端都会返回ack,ack可选级别有send_ok,master_receive_ok,master_flush_ok,可靠性依次增强,异步发送方式可以在sendcallback回调中获取到发送结果,业务自定义发送失败处理逻辑,同步发送方式可以直接获取到发送结果,在同步发送请求超时之前,若存在消息发送失败,默认会重试3次发送,从而保证了消息的可靠发送。
存储可靠性
WMB的存储设计参考了开源消息队列RocketMQ与PhxQueue,存储过程如下图所示:
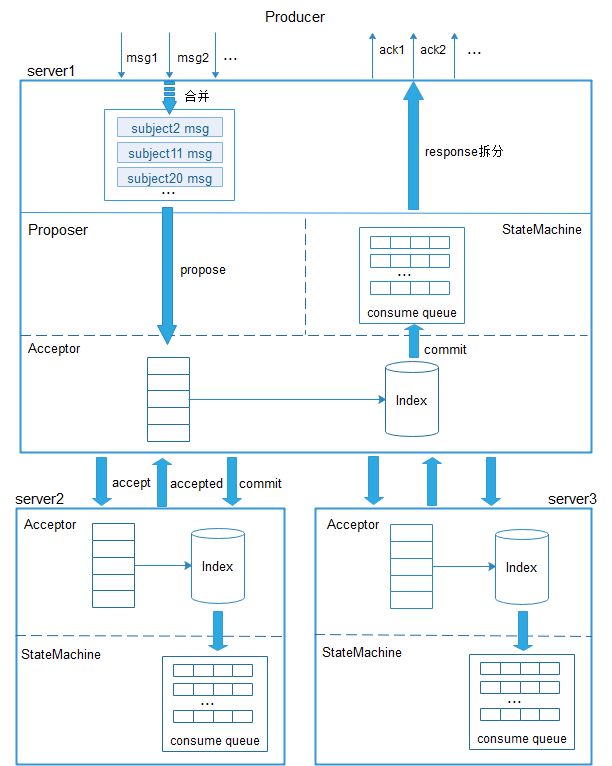
图4 消息存储
WMB存储结构主要包括physic log、物理索引、消费队列consume queue三个部分,数据存储都采用mmap内存映射的方式,数据先写入pagecache再异步刷盘到物理文件。通过一致性算法Paxos做主从多副本数据同步。
其中,每个paxos group共享physic log、物理索引存储单元,服务端将每个group的消息依次批量合并为BatchMsg,封装为一个新的数据实例instance,由paxos group的master节点发起instance数据同步申请,将instance数据封装在accept请求发向slave节点,等待slave节点返回accept结果,若在超时之前,收到过半节点(包括自己)接受了数据同步申请,再向所有节点发起commit请求,确认instance有效数据存储。若没有接收到过半节点accept返回成功,将延迟一段时间重新发起prepare请求进行二阶段数据提交,防止数据冲突。
Commit阶段主要是指状态机的回调执行,将封装在instance实例中的BatchMsg解析,获取单条消息的主题号以及在physic log中的offset、size、存储时间戳等元信息,分发到对应主题的某一个consume queue。只有当元信息被分发到consume queue存储成功后,消息才可能会被订阅方消费到,从而保证了多副本有效数据的一致性。
WMB通过引入Paxos算法,保证了主从数据的强一致性,当server节点故障,master可随机切换,主从节点数据能够快速对齐,大幅度降低了消息丢失率。
订阅可靠性
WMB提供了推送(push)、拉取(pull)订阅方式,分别保证“至多一次”与“至少一次”消息投递。
Push VS Pull

订阅交互过程如下图所示:

图5 消息订阅
每个主题在服务端默认有8个consume queue,可动态调整,相同clientID的不同client向服务端发起订阅,服务端会通过动态负载均衡机制,将consume queue尽量平均分配给每个client,每个queue最多只能分配给一个client消费,不同queue的消息可并行消费。
无论是推送模式还是拉取模式,当消息推送到客户端后,首先都放入本地接收队列message queue,同一个queue的消息会顺序执行messageReceiveHandler消费回调。
消息消费过程可靠性主要由以下几个机制保证:
推送/拉取堆积控制
客户端实时统计本地接收队列消息量,超过阈值则停止拉取或者向Server发送停止推送命令,恢复时再继续拉或发送继续推送命令,防止出现大量消息堆积导致客户端内存溢出。
消费ack
对于Pull消费方式,会定时向服务端提交消费offset,已经推送到客户端,没有提交消费ack的消息,重新初始化拉取时,会被再次推送到客户端,另外,消费失败的消息也可选择重试消费。
重试消费
重试消费的消息会被订阅方重新发送到服务端,分配到对应clientID的重试消费队列,如图5中的队列10001(10000+ClientID),延迟一定时间后重新推送给客户端,一条消息最多可被重复消费6次。
回溯消费
如果业务某段时间内存在大面积消息处理故障,可选择回溯消费,调整消费offset到故障前的时间点,重推消息。
小结
综上所述, 发送、存储、订阅的可靠性共同支撑了WMB服务的可靠性,采用同步发送或者异步发送+回调的方式、服务端高可靠消息持久化机制、订阅方拉取消费+ack确认方式,可以为业务提供一个完全不丢的消息通信链路。但可靠性带来的另外一个问题是消息重复,当发送或者消费过程因网络问题ack丢失,都可能会导致消息重发,目前WMB还不支持消息去重,去重逻辑交给业务去做幂等性实现。
高可用性
容灾能力
线上环境总会存在一些不可预知的故障,如服务器宕机、网络抖动、服务节点因未知bug挂掉等,WMB在异常情况下的容灾能力直接关系到服务的可用性。
服务端容灾能力
如WMB集群架构所示,每个服务节点都可能会分布着一些paxos group的master节点与另外一些group的slave节点。若节点故障或者与store内其它节点网络隔离,master租约周期结束之前续约失败,master可能会漂到其它节点,发生主从自动切换。如果服务节点仅与store内部分节点网络出现抖动,通过过半节点的投票以及多个续约周期的判定,可以防止master随着网络抖动而发生多次不必要的切换。
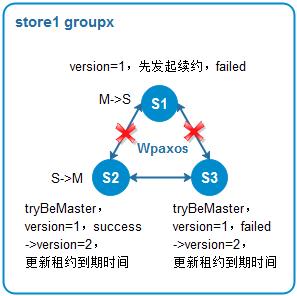
图6 容灾1
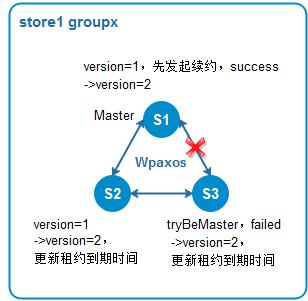
图7 容灾2
如果master发生变更,会通过注册中心下发配置给客户端,客户端立即重连到新的master,降低了服务不可用时间。
客户端容灾能力
WMB服务端采用集群部署结构,一个集群至少包括4个store单元,正常情况每个主题可用的master节点都会有多个。
如果客户端与服务节点之间出现网络中断,客户端能够立即感知到连接状态变化,会直接摘除该服务节点,再定期探测节点状态直至恢复。
如果客户端与服务节点出现网络抖动,连接状态正常,Master配置不会发生变化,客户端继续将请求发送到原有节点,这个时候请求有可能失败,客户端会将请求连续失败5次以上服务节点,自动踢除,再定期探测节点状态直至恢复。
横向扩展能力
WMB支持集群动态扩/缩容,当某集群负载较高时,可动态扩展store数量,增大集群容量,并对业务透明无感知。
过载保护能力
对于任何高并发的系统,在服务器资源有限的情况下,单位时间服务能力也是有限的,如果超过服务承受能力,可能会发生雪崩效应,造成整个服务crash。WMB提供了主题分布式限速机制,以及基于单点访问量与内存使用的过载保护能力,可对线上服务进行合理的容量规划。
高性能
高吞吐、低延迟是衡量分布式消息队列是否具有高性能的两个重要标准。下面介绍下WMB在提高性能方面做的一些优化。
批量化
批量化处理是提升WMB吞吐量的重要优化点,客户端将发向相同server的消息进行批量合并后发送,减少了网络开销,服务端将相同group的消息合并后,通过Paxos批量commit,同时减少了网络交互与写磁盘次数。
多分组存储
服务端将所有主题进行分组合并存储,不同分组可并行commit数据,提升了系统并发处理能力,但分组数过多又容易造成严重的写磁盘放大,通过性能压测对比,WMB最终将服务端分组数固定在9。
长轮询
WMB推送、拉取都采用长轮询机制,若没有消息到来,服务端会挂起推送任务或拉取请求,当有消息到来或者主题消费分配有变化时,立即异步通知,唤醒阻塞的拉取请求,继续推送消息,从而保证了消息投递的低延迟。
图8 长轮询拉取
Master负载均衡
在master随机切换的模式下,有可能会出现同一个store内master分布不均匀,对整个store的稳定性造成影响,为了解决这个问题,WMB添加了master平滑夺取机制,每次主从切换后,可在一定周期内实现master均衡分布,具体实现细节将在下篇文章中介绍。
在master均衡分布情况下,同一个store内的server节点对等部署,存储及消费压力均匀分配在每个节点,有效的降低了服务端消息处理延迟。
无论是推送还是拉取方式,在订阅方消费能力足够快时,WMB服务端从接收到一条消息到成功发送给订阅方,整个服务端消息处理延迟平均为4ms。在普通机械硬盘服务器上,512字节消息,WMB单个store的QPS可达23W。
总结
WMB为58自研的高可靠、高可用分布式消息队列,目前支撑了公司4000多个核心业务项目,每天流转300多亿数据,是58分布式架构中的重要组件。本文主要介绍了WMB的系统架构以及在高可靠、高可用、高性能方面的设计实践。由于篇幅限制,部分实现如动态扩/缩容机制、Master负载均衡机制、限流机制等没有详细展开介绍,还有消息顺序性、延时消息、消息广播等一些功能实现也没有提到,将在后面其它文章中详细介绍。
以上是关于58分布式消息队列WMB设计与实践的主要内容,如果未能解决你的问题,请参考以下文章