PK光明顶?江湖上流传的几大消息队列门派,到底有什么本质的区别?
Posted 狸猫技术窝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PK光明顶?江湖上流传的几大消息队列门派,到底有什么本质的区别?相关的知识,希望对你有一定的参考价值。
目录
(1)流派1:有Broker的暴力路由
(2)流派2:有Broker的复杂路由
(3)流派3:无Broker的通信流派
(4)总结
平时经常会看到很多人写文章分析Kafka、RabbitMQ、RocketMQ等各种MQ之间的性能比较,功能比较,但是实际上从MQ消息队列的门派上来说,这些MQ其实是分属不同的门派的。
那么这不同的门派之间,到底有什么区别呢?
(1)流派1:有Broker的暴力路由
这个流派最典型的就是Kafka了,Kafka实际上为了提升性能,简化了MQ功能模型,仅仅提供了一些最基础的MQ相关的功能,但是大幅度优化和提升了吞吐量。
首先,这个流派一定是有一个Broker角色的,也就是说,Kafka需要部署一套服务器集群,每台机器上都有一个Kafka Broker进程,这个进程就负责接收请求,存储数据,发送数据。
Kafka的生产消费模型做的相对是比较暴力简单的,就是简单的数据流模型。
简单来说,他有一个概念,叫做“Topic”,你可以往这个“Topic”里写数据,然后让别人从这里来消费。
这个Topic可以划分为多个Partition,每个Partition放一台机器上,存储一部分数据。
在写消息到Topic的时候,会自动把你这个消息给分发到某一个Partition上去。
然后消费消息的时候,有一个Consumer Group的概念,你部署在多台机器上的Consumer可以组成一个Group,一个Partition只能给一个Consumer消费,一个Cosumer可以消费多个Partition,这是最最核心的一点。
通过这个模型,保证一个Topic里的每条消息,只会交给Consumer Group里的一个Consumer来消费,形成了一个Queue(队列)的效果。
假如你想要有一个Queue的效果,也就是希望不停的往Queue里写数据,然后多个消费者消费,每条消息就只能给一个消费者,那么通过Kafka来实现,其实就是生产者写多个Partition,每个Partition只能给Consumer Group中的一个Consumer来消费。如下图所示:
如果要实现Publish/Subscribe的模型呢?就是说生产者发送的每条消息,都要让所有消费都消费到,怎么实现?
那就让每个消费者都是一个独立的消费组,这样每条消息都会发送给所有的消费组,每个消费组里那唯一的一个消费者一定会消费到所有的消息。
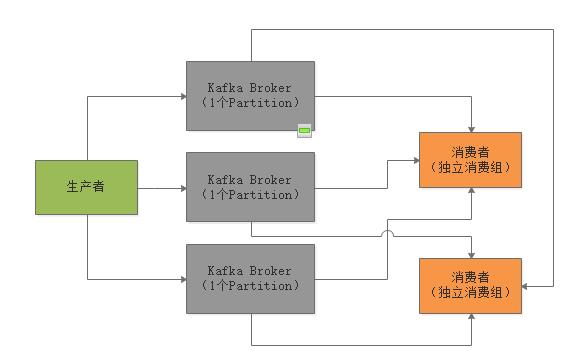
但是除此之外,Kafka就没有任何其他的消费功能了,就是如此简单,所以属于一种比较暴力直接的流派。
它就是简单的消费模型,实现最基础的Queue和Pub/Sub两种消费模型,但是内核中大幅度优化和提升了性能以及吞吐量。
所以Kafka天生适合的场景,就是大数据领域的实时数据计算的场景。
因为在大数据的场景下,通常是弱业务的场景,没有太多复杂的业务系统交互,而主要是大量的数据流入Kafka,然后进行实时计算。
所以就是需要简单的消费模型,但是必须在内核中对吞吐量和性能进行大幅度的优化。
因此Kafka技术通常是在大数据的实时数据计算领域中使用的,比如说每秒处理几十万条消息,甚至每秒处理上百万条消息。
(2)流派2:有Broker的复杂路由
第二个流派,就是RabbitMQ为代表的流派,他强调的不是说如何提升性能和吞吐量,关注的是说要提供非常强大、复杂而且完善的消息路由功能。
所以对于RabbitMQ而言,他就不是那么简单的Topic-Partition的消费模型了。
在RabbitMQ中引入了一个非常核心的概念,叫做Exchange,这个Exchange就是负责根据复杂的业务规则把消息路由到内部的不同的Queue里去。
举个例子,如果要实现最简单的队列功能,就是让exchange往一个queue里写数据,然后多个消费者来消费这个queue里的数据,每条消息只能给一个消费者,那么可以是类似下面的方式。
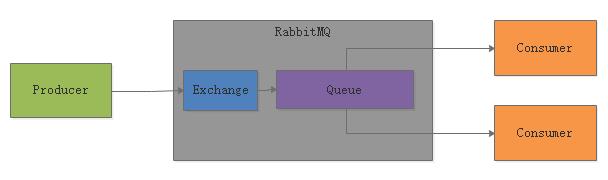
如果想要实现Pub/Sub的模型,就是一条消息要被所有的消费者给消费到,那么就可以让每个消费者都有一个自己的Queue,然后绑定到一个Exchange上去。
接着,这个Exchange就设定把消息路由给所有的Queue即可,如下面这样。
此时Exchange可以把每条消息都路由给所有的Queue,每个Consumer都可以从自己的Queue里拿到所有的消息。
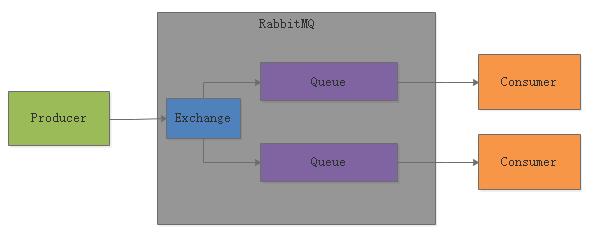
RabbitMQ这种流派,其实最核心的是,基于Exchange这个概念,他可以做很多复杂的事情。
比如:如果你想要某个Consumer只能消费到某一类数据,那么Exchange可以把消息里比如带“XXX”前缀的消息路由给某个Queue。或者你可以限定某个Consumer就只能消费某一部分数据。总之在这里你可以做很多的限制,设置复杂的路由规则。
但是也正是因为引入了这种复杂的消费模型,支持复杂的路由功能,导致RabbitMQ在内核以及架构设计上没法像Kafka做的那么的轻量级、高性能、可扩展、高吞吐,所以RabbitMQ在吞吐量上要比Kafka低一个数量级。
所以这种流派的MQ,往往适合用在Java业务系统中,不同的业务系统需要进行复杂的消息路由。
比如说业务系统A发送了10条消息,其中3条消息是给业务系统B的,7条消息是给业务系统C的,要实现这种复杂的路由模型,就必须依靠RabbitMQ来实现。
当然,对于这种业务系统之间的消息流转而言,可能不需要那么高的吞吐量,可能每秒业务系统之间也就转发几十条或者几百条消息,那么就完全适合采用RabbitMQ来实现。
(3)流派3:无Broker的通信流派
ZeroMQ代表的是第三种MQ。说白了,他是不需要在服务器上部署的,就是一个客户端的库而已。
也就是说,他主要是封装了底层的Socket网络通讯,然后一个系统要发送一条消息给另外一个消息消费 。
通过ZeroMQ,本质就是底层ZeroMQ发送一条消息到另外一个系统上去。
所以ZeroMQ是去中心化的,不需要跟Kafka、RabbitMQ一样在服务器上部署的。
他主要是用来进行业务系统之间的网络通信的,有点类似于比如你是一个分布式系统架构,那么此时分布式架构中的各个子系统互相之间要通信,你是基于Dubbo RPC?还是Spring Cloud HTTP?
可能上述两种你都不想要,就是要基于原始的Socket进行网络通信,简单的收发消息而已。
此时就可以使用ZeroMQ作为分布式系统之间的消息通信,如下面那样。
(4)总结
其实现在基本上MQ主要就是这三个流派,很多小众的MQ一般很少有人会用。
而且用MQ的场景主要就是两大类:
业务系统之间异步通信
大数据领域的实时数据计算
所以一般业务系统之间通信就是会采用RabbitMQ/RocketMQ,需要复杂的消息路由功能的支撑。
大数据的实时计算场景会采用Kafka,需要简单的消费模型,但是超高的吞吐量。
至于ZeroMQ,一般来说,少数分布式系统中子系统之间的分布式通信时会采用,作为轻量级的异步化的通信组件。
作者简介:
爱钓鱼的桌子哥,资深架构师
作者先后工作于滴滴、百度、字节跳动等国内一线互联网大厂,从事基础架构相关工作。带领团队设计与构建了大规模的分布式存储系统、分布式消息中间件、分布式数据库,对分布式架构设计、系统高可用体系构建、基础中间件架构都有丰富的经验。
END
为您推荐:
长按下图二维码,即刻关注【狸猫技术窝】
阿里、京东、美团、字节跳动
顶尖技术专家坐镇
为IT人打造一个 “有温度” 的技术窝!
以上是关于PK光明顶?江湖上流传的几大消息队列门派,到底有什么本质的区别?的主要内容,如果未能解决你的问题,请参考以下文章