时常会思考消息队列的价值是什么?新人加入团队后该如何理解消息队列?又该如何理解小米的自研产品 Talos 和 EMQ?鉴于这些考虑,我把对消息队列的理解做一个简单总结,希望能帮助感兴趣的同学了解 Talos/EMQ 的价值和定位,以及它在企业架构中扮演着什么样的角色。 作者批注:思考手上的工作,找到它的价值和定位,就找到了工作的目标 — 努力将价值最大化
一、日志与消息队列
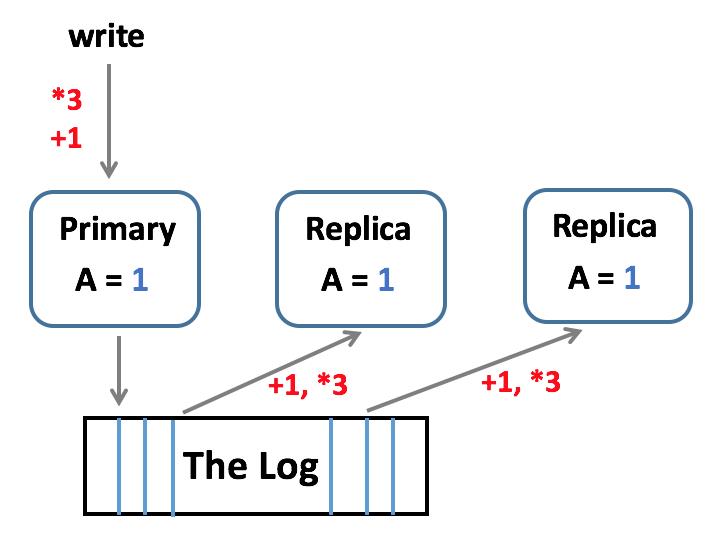
说到消息队列,就不得不说一下日志 作者批注:本质上日志与消息队列都可以抽象成 Pub/Sub 的模式Jay Kreps (Confluent CEO,Kafka 核心作者) 在《The Log: What every software engineer should know about real-time data's unifying abstraction》[1] 中系统性描述了日志的价值和重要性,指出了日志特定的应用目标:它记录了什么时间发生了什么事情(they record what happened and when)。而这,正是分布式系统许多问题的核心。 作者批注:《日志:每个软件工程师都应该知道的有关实时数据的统一抽象》据说是史诗般必读文章 这个“按时间天生有序”的特性让日志解决了分布式系统中的两个重要问题:修改操作的排序和数据分发(ordering changes and distributing data),这为并发更新的一致性和副本复制提供了基础。分布式系统中为了保证各副本的一致性,协商出一致的修改操作顺序是非常关键且核心的问题,利用日志天生有序的特性可以将这个复杂的问题变得简单。我们来看一个不太严谨的例子:假设系统有三个副本,都存储着 A=1 的初始值,某一时刻,要执行一个加法乘法的操作序列对 A 的值进行修改:"+1"、"*3" 假设 Primary 收到两条指令后,对其他副本依次广播了 "+1"、"*3",由于网络的不确定因素,第一个副本收到的指令为 "*3"、"+1",第二个副本收到的指令为 "+1"、"*3",这就会带来副本的一致性问题;如何解决这个问题呢?答案是日志,利用日志将并发更新进行排序,所有副本从日志中按顺序读取更新操作,应用到本地,就可以将这个复杂的问题简单化。如图,Primary 依次进行 "+1"、"*3" 的操作,并写入日志,利用日志做修改操作的“数据分发”,使得各副本能够在本地应用完全相同的操作序列,从而保证各副本数据的一致; 作者批注:本质上是是把多台机器一起执行同一件事情的问题简化为实现分布式一致性日志,通过日志的 Pub/Sub 保证多台机器对数据处理的最终一致上面的例子能很好的说明为什么顺序是保证副本间一致性的关键,而日志为此提供了基础和载体。让我们进一步思考和联想:Primary 将各种操作通过日志序列化,各 Replica 从日志中读取并应用到本地状态,这种解决问题的模式也叫 Pub/Sub,即抽象成通用的数据订阅机制,而将这种抽象产品化,就是消息队列。
二、消息队列的应用价值
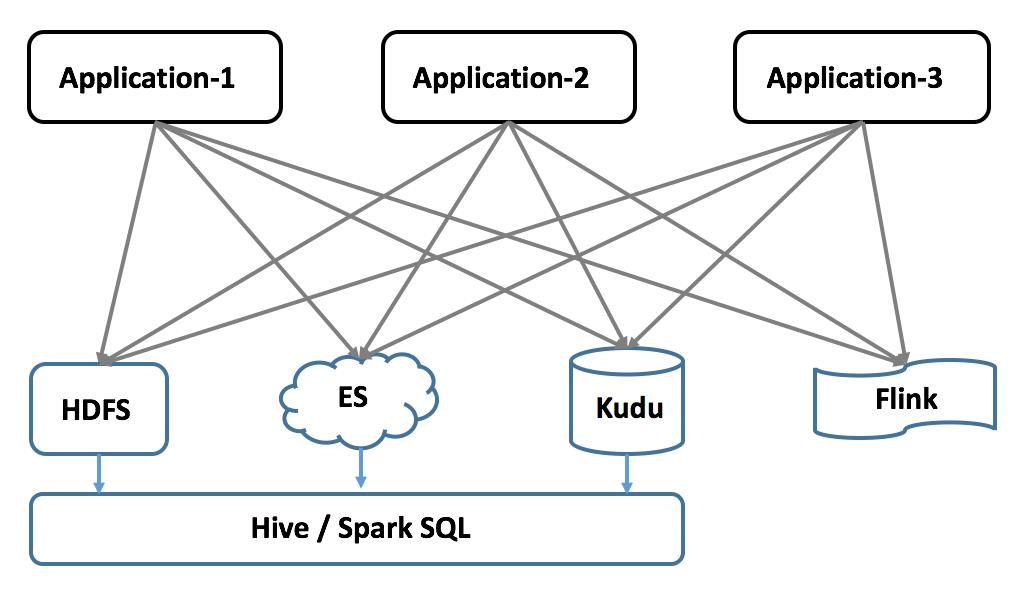
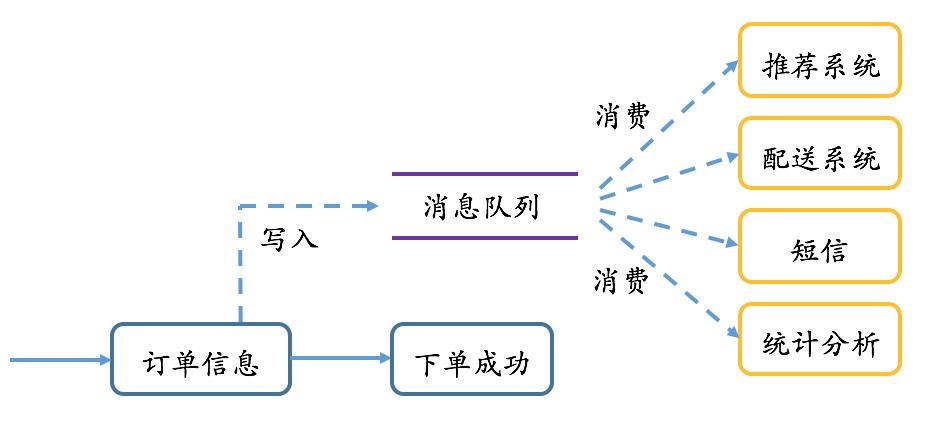
消息队列作为大型分布式系统的关键组件,在实时数据或流式数据架构中扮演着重要角色,它通常被应用在系统解耦、异步处理、流量削峰,分布式事务/金融电商等场景中,接下来我们分别从这几个场景浅谈消息队列的应用价值。1. 数据集成与系统解耦如果说日志为解决分布式一致性问题提供了基础,那么同样是 Pub/Sub 模式的消息队列,则为琳琅满目的数据系统之间协作提供了一件利器,大大简化了数据集成的复杂度(O(N^2) 变为 O(N)),提升了数据流转的效率,加速了数据价值展现;什么是数据集成?引用 Jay Kreps 的文章: Data integration is making all the data an organization has available in all its services and systems. 数据集成即将一个组织所拥有的数据,使其在所有的服务和系统中都可用。那么数据集成是解决什么问题?使用消息队列又是如何加速数据集成的?我们看一个案例不少业务都有这样的场景:随着业务量的爆发,为理解用户行为,需要收集日志保存到 Hadoop 上做离线分析;为了能方便定位问题,同时把日志导一份到 ElasticSearch 做全文检索;为了给老板查看业务状况,需要将数据汇总到数仓中提供统计报表;此外还需要进行一些实时的流式计算...一个业务系统需要同时与多个大数据系统交互,一段时间后,团队有了新的业务,新业务系统又重复上面的事情,对接各种系统,如下图,最终的结果是系统架构盘根交错,快乐与痛苦齐飞。
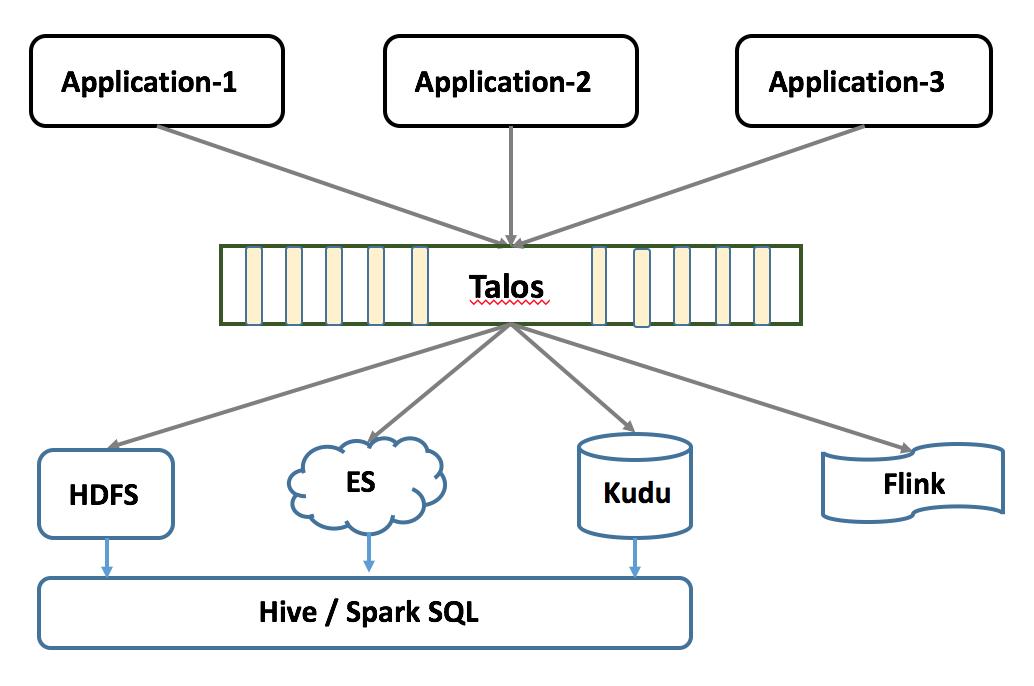
可以看到,上面案例本质上是一个数据集成的需求,但数据集成的难处就在于需要面对:1)越来越多的数据;2)越来越多的数据系统;为什么会有这种现象,只能说大数据时代下,很难有一个系统能够解决所有的事情,这就导致了业务数据因为不同用途而需要存入不同的系统,比如上面说的检索,分析,计算等;于是,数据集成的挑战就变成了不同系统间繁杂的数据同步,有多复杂?M 个业务,N 个数据系统:1)所有业务都需要关心到每一个系统的数据导入,复杂度 M*N 2)架构复杂交错,各个链路容易互相影响。比如一个业务数据写入 A 系统失败,一般会影响 B 系统的写入; 3)出现问题后很难定位,且容易丢失数据,数据恢复也变得困难如何解决上面这些问题,从而提高集成的效率呢?还是 Pub/Sub 的思路,引入消息队列做数据分发,架构如下:
六、参考文献
[1]《The Log: What every software engineer should know about real-time data's unifying abstraction》
https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
[2]《杠上 Spark、Flink?Kafka 为何转型流数据平台》
https://www.infoq.cn/article/l*fg5StAPoKiQULat0SH