分布式框架之高性能:消息队列的可用性
Posted TPVLOG
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式框架之高性能:消息队列的可用性相关的知识,希望对你有一定的参考价值。
本文首发于Ressmix个人站点:https://www.tpvlog.com
我们在上一篇文章提到,引入消息队列后系统整体的复杂度会上升,我们此时必须要关注消息队列自身的可用性,因为一旦消息队列出现问题,会导致整个系统不可用。
本章,我们将以RabbitMQ和Kafka为例,介绍下这两种分布式MQ是如何实现自身的高可用的,关于更多消息队列内容,读者后续可以关注我的另一个专栏《深入浅出消息队列系列》(目前还在抽空整理中)。
一、RabbitMQ
RabbitMQ有两种部署模式:普通集群模式和镜像集群模式。但是无论哪一种模式,单个RabbitMQ实例都可以看成存储着所有数据,也就是说RabbitMQ是不对数据进行分片存储的。我们在中曾提供过集群有两种模式:数据集中集群和数据分散集群,RabbitMQ其实就是数据集中集群。
1.1 普通集群模式
普通集群模式是RabbitMQ的默认模式,就是说在多台机器上启动多个RabbitMQ实例时,创建的queue只会存放在一个RabbitMQ实例上,但是其它实例都会同步queue的元数据:
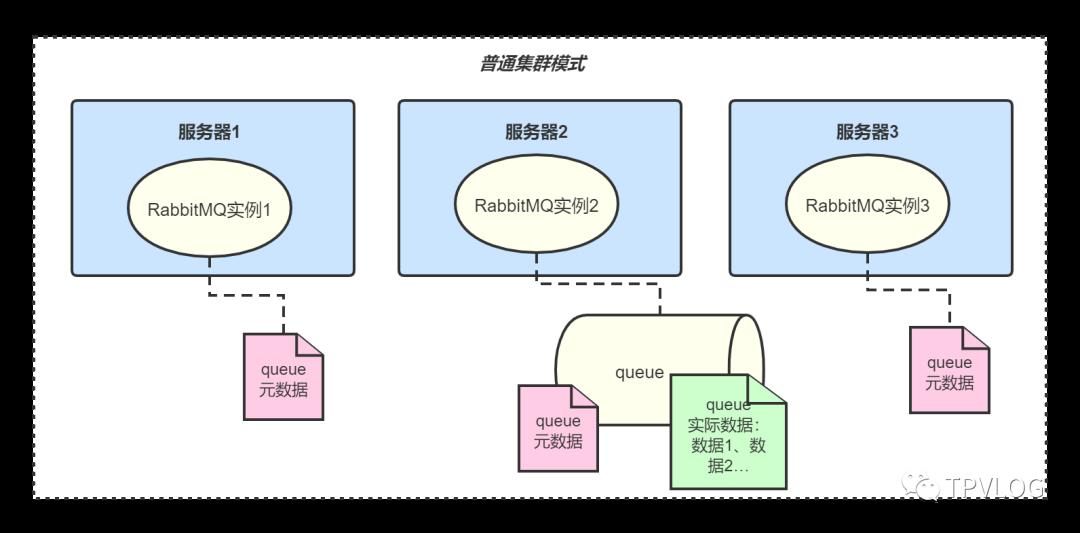
上图中,3台机器上各部署一个RabbitMQ实例,构成了一个普通集群模式,只有中间那个实例的queue中保存着真正的数据。
当客户端请求消费消息时,连接到的可能是任意一个RabbitMQ实例,如果该实例上只有queue的元数据,就会从真正queue所在的那个实例上拉取数据,然后返回给客户端:
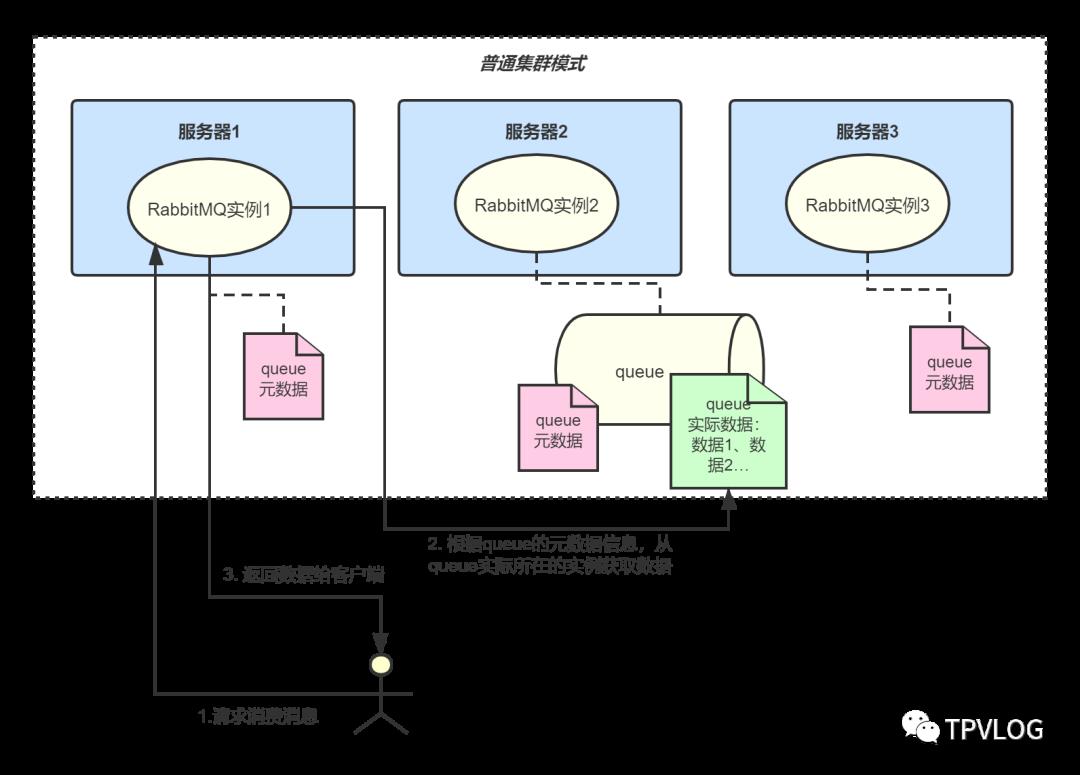
这种方式显然很有问题:
客户端每次请求都可能需要从真正queue实例那拉取数据,具有额外开销;
queue所在的RabbitMQ实例本身成为了性能瓶颈;
如果 queue所在的RabbitMQ实例挂了,那queue的数据就丢失了,没法保证高可用。
1.2 镜像集群模式
我们再来看下RabbitMQ的镜像集群模式。在镜像集群模式下,每一个RabbitMQ实例都保存着queue的消息数据和元数据,当客户端请求写消息时,接受消息的那个实例会自动把消息同步到其它实例的queue里:
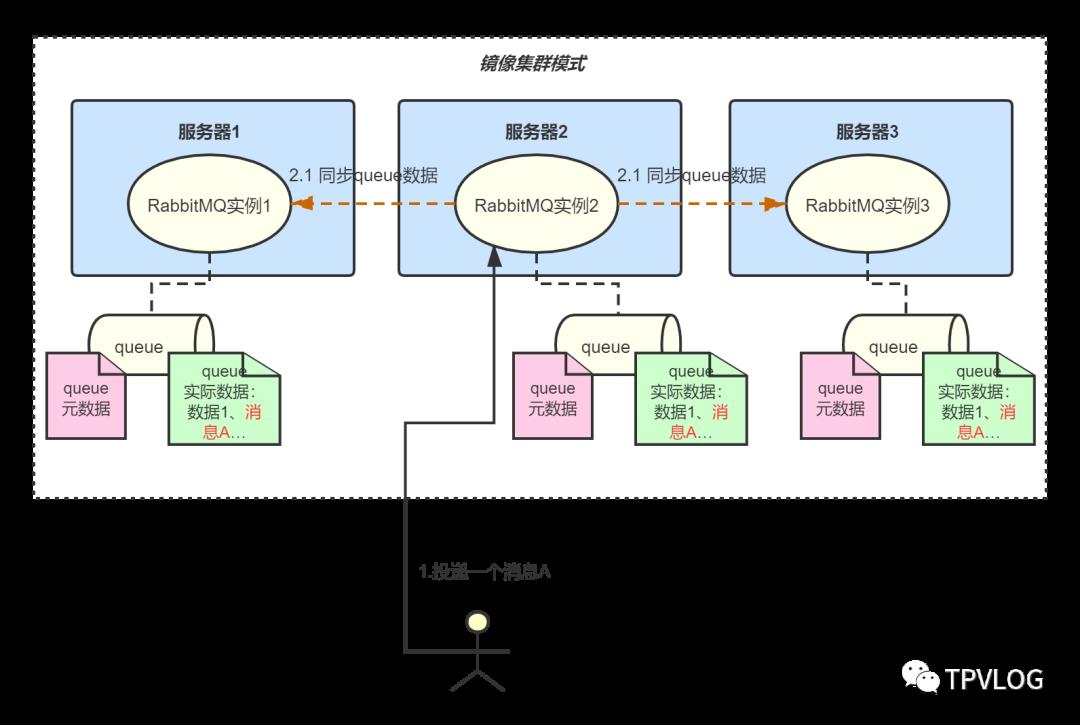
这种模式的优点是即使一个节点宕机了,其它节点还包含着queue的完整数据,从而保证了集群的可用性。
缺点也很明显:
单个节点需要容纳完整的数据,如果数据量很大,是没法水平扩展的;
同步消息数据到其它所有节点的性能开销是很大的。
RabbitMQ并不是分布式消息队列,他就是传统的消息队列,只不过提供了一些集群、HA的机制而已,因为queue的数据始终都放在一个RabbitMQ实例里面,镜像集群下,也只是每个实例保存一份queue的完整数据。
二、Kafka
2.1 副本机制
Kafka集群是真正的分布式数据分散集群,也就是说每个节点只保存整体数据的一部分。Kafka集群由很多个称为“Broker”的组件构成,每个Broker在操作系统上就是一个进程,可以看成一个Kafka数据节点。当创建一个Topic时,这个Topic可以划分为多个partition,每个partition存放总体的一部分数据,保存在不同的Broker上。
我们通过一个示例来理解下,假设我们创建了一个Topic,并指定其partition数量为3,当生产者往Kafka写消息时(假设写了三条消息:MsgA、MsgB、MsgC),那么这三条消息其实是保存在不同的Broker节点上的,如下图:
那么,万一某个Broker进程挂了,岂不是上面的数据就丢失了?Kafka如何保证节点的高可用性呢?
Kafka 0.8以后,提供了replica副本机制:Kafka会将每一个partition都copy几个replica副本,然后均匀分布到其它Broker节点上,然后所有replica会选举一个leader出来,生产和消费只跟这个leader打交道,其他replica都是follower,当某个leader挂掉后就会重新选举出一个leader,从而保证了集群的高可用性。
写入消息时:消息会路由到leader,由leader负责将数据落地磁盘后,其它follower会自动从leader同步数据,当所有follower都同步完成后,会发送ack确认消息给leader,leader收到所有响应后,返回响应给生产者。
消费消息时:消费者只会从leader去消费。(注意,只有当该消息已经被所有follower同步成功并且leader收到所有ack响应后,这个消息才会被消费者读到)
为什么读/写都能对针对leader?因为如果可以随意读写任意一个follower,就要关注数据一致性的问题,系统复杂度将大幅提升,很容易出问题。
以上是关于分布式框架之高性能:消息队列的可用性的主要内容,如果未能解决你的问题,请参考以下文章