分布式框架之高性能:消息队列
Posted TPVLOG
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式框架之高性能:消息队列相关的知识,希望对你有一定的参考价值。
本文首发于Ressmix个人站点:https://www.tpvlog.com
一、简介
消息队列大家应该不陌生,没接触过的可以先看下我写的分布式消息中间件系列(https://www.tpvlog.com/article/125)。目前常见的开源分布式消息队列主要有下面几种:
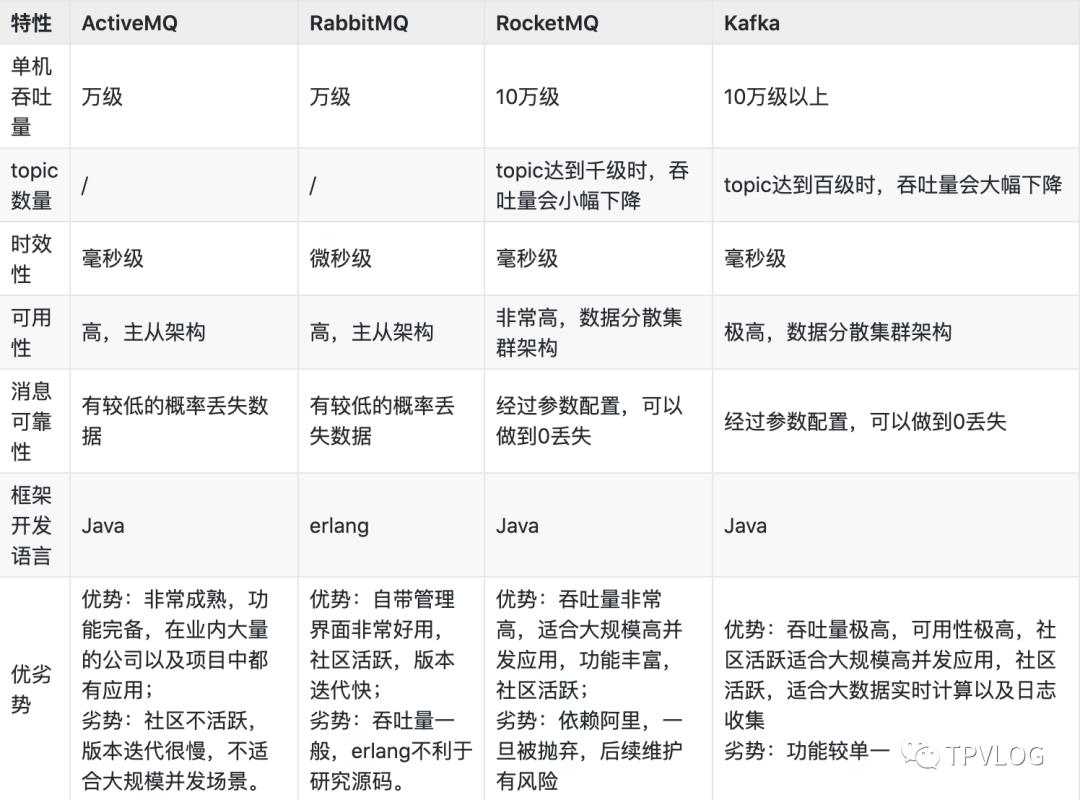
我们后续会针对RabbitMQ、RocketMQ、Kalfka这三种主流MQ作讲解,本章我们先来看下为什么要在我们的系统中引入分布式消息队列?
我们在自己的系统中引入消息队列,无非就是三个目的:解耦、异步、削峰。本文我们就通过三个示例来讲解下消息队列的这三项基本功能。
二、解耦
在分布式系统中,解耦的目的就是降低服务之间的直接依赖。我们来看下面这个系统。
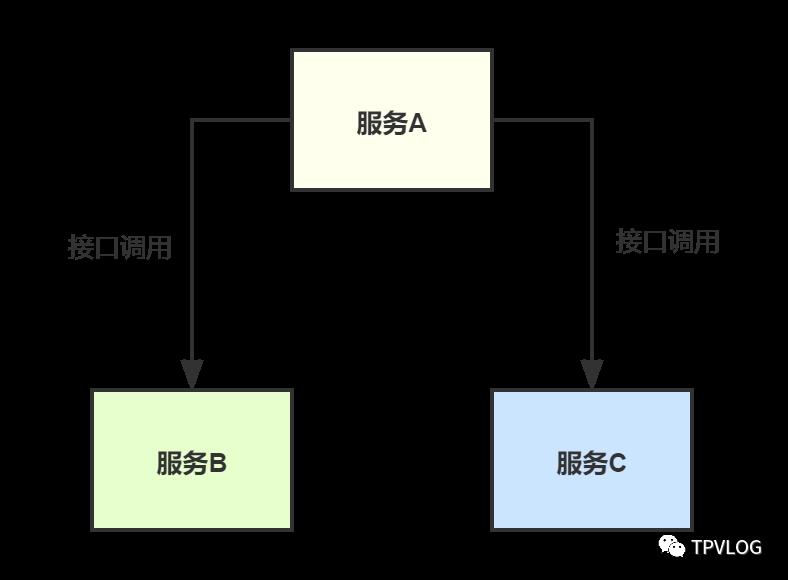
2.1 解耦前
服务A是一个供数系统,会产生一些比较关键的数据,然后通过接口调用的方式把数据给服务B和服务C,最开始服务B和服务C所需的数据是相同的,所以一切都没什么问题:
一段时间后,服务C要求服务A做一些更改,原来送的数据有些地方需要做变更,所以服务A要重新调用一个服务C的专用接口:

又过了一段时间,来了服务D和服务E,也要求服务A针对它们需要的数据调用定制接口,同时服务B告诉服务A,以前那个通用接口不用了,因为服务B要下线了:
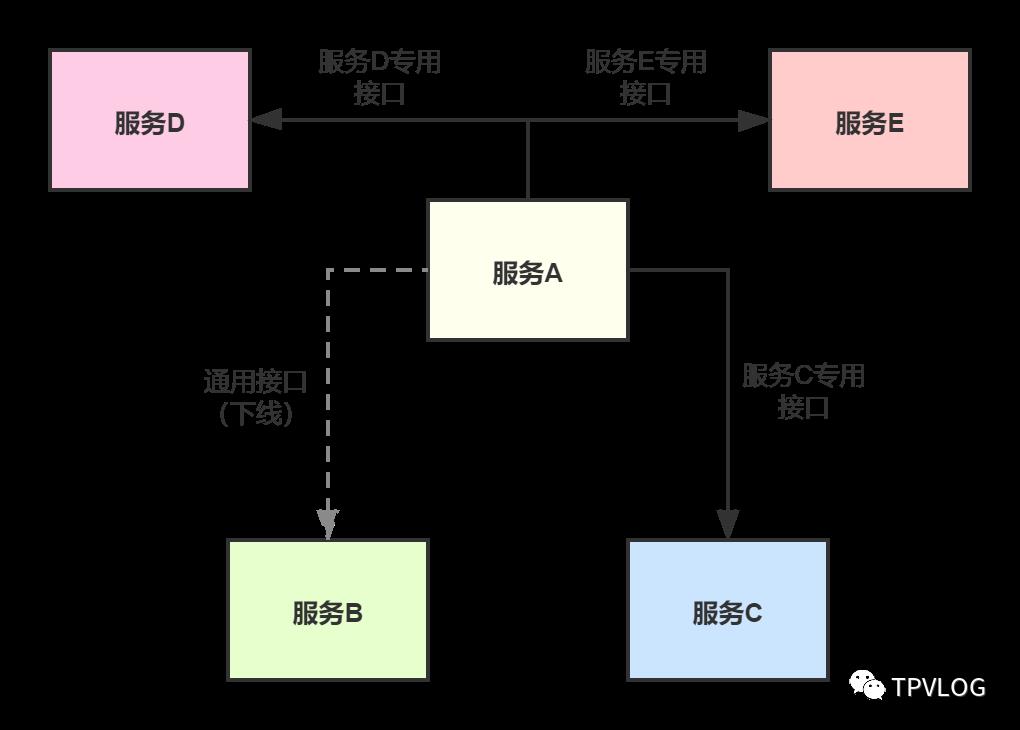
这种直连的方式导致服务A跟各种各种乱七八糟的服务紧耦合在一起,同时还要考虑超时问题、是不是要做重试机制,维护服务A的童鞋估计要崩溃。
2.2 解耦后
我们来看下如何通过消息中间件解耦:
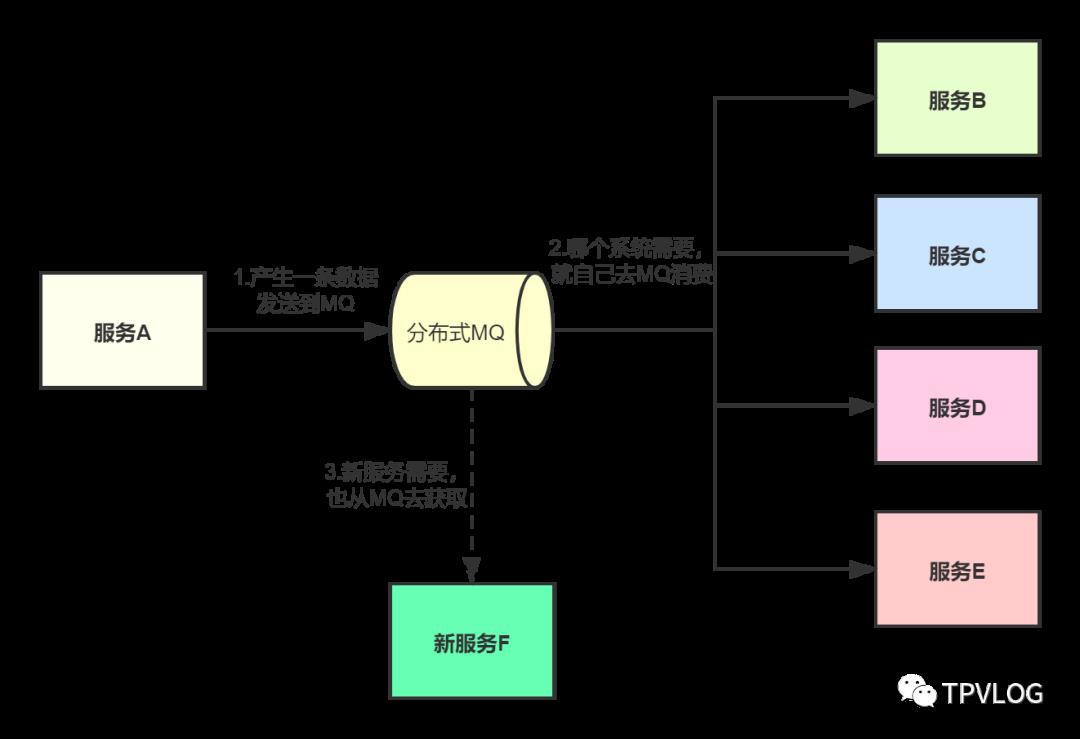
上图中,在服务A和各个服务之间加入MQ,服务A产生的数据全量扔到MQ,并约定好格式,哪个服务需要数据就自己去MQ消费,然后自己处理。服务A也不用考虑什么接口调用超时、重试之类的问题了。
三、异步
消息队列的另一个重要功能就是异步化接口调用,我们考虑这样一种场景:用户通过浏览器发起一个请求,后台服务针对请求做处理,但事实上用户并不需要立刻得到该请求的响应,因为页面有其它地方可以让用户稍后查询请求的结果。这是一种典型的异步请求场景,我们现在看下同步的情况。
3.1 同步请求
下图中,服务A本地执行一些逻辑耗时20ms,然后依次同步调用服务B、服务C、服务D的接口,由于各个依赖服务本地执行的逻辑各不相同,在加上网络开销,一个请求的耗时接近1s。
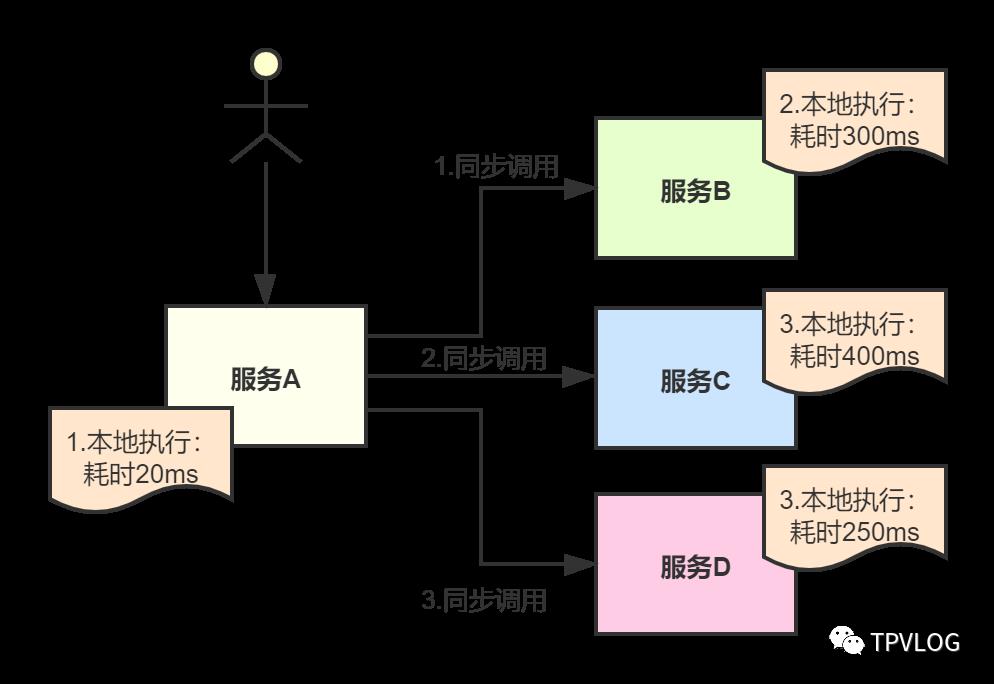
一般来说,对于互联网应用,如果是涉及与用户直接交互的,基本都要在200ms内完成,所以显然这种同步调用方式在当前业务场景下是不可取的。
3.2 异步请求
我们再来看下如何通过消息中间件将请求异步化:
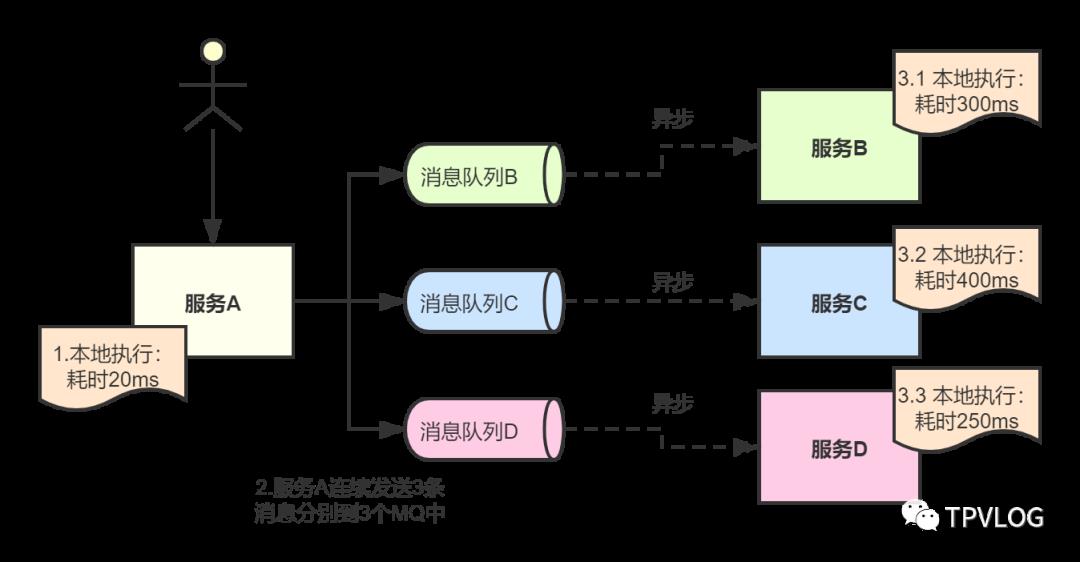
上图中,假设服务A发送3个消息耗时5ms,加上自身执行逻辑耗时20ms,那么25ms就可以将结果响应给用户。至于服务B、服务C、服务D,都是异步从消息队列中获取消息然后执行本地逻辑,从而大大减小了请求耗时,提升了用户体验。
四、削峰
消息队列最后一种常用的场景,就是在高峰时间进行削峰。
4.1 削峰前
一般的应用可能是下图这样的,在非高峰期时期,系统几乎没什么压力,但是一旦遇到高峰流量,请求都直接打到数据库,mysql一般扛个每秒2000请求差不多快到极限了,再高就可能崩溃:
4.2 削峰
峰值流量持续的时间不会很久,一般最多1小时就差不多了,我们完全可以利用MQ存储高峰期的请求,然后系统A依然以自身最大能力去消费MQ(假设每秒消费2000个请求),这样即使在高峰期,系统也不会挂掉:
因为非峰值时期的流量一般是很低的,所以对于积压的消息,会在高峰期过后被慢慢消费掉。举个例子,假设每秒MQ积压3000条消息,那么1小时积压1080万条消息,这1080万条消息基本上1个半小时就可以被系统A处理完。
五、总结
引入分布式消息队列后,会给系统带来很多好处,最主要的就是性能方面,但同时也会使系统的复杂性变高。一方面,MQ自身需要做到高可用,另一方面,多个系统通过MQ进行交互,如何保证数据一致性?(比如3.2中的系统A处理完后直接返回成功,系统B、C、D中的BC写库成功,但是D失败了,这时候数据就不一致了)
以上是关于分布式框架之高性能:消息队列的主要内容,如果未能解决你的问题,请参考以下文章
微服务框架Spring Cloud之使用事件和消息队列实现分布式事务
分布式技术专题线程间的高性能消息框架-深入浅出Disruptor的使用和原理