网络爬虫前奏:HTTP的请求与响应
Posted AI编程笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫前奏:HTTP的请求与响应相关的知识,希望对你有一定的参考价值。
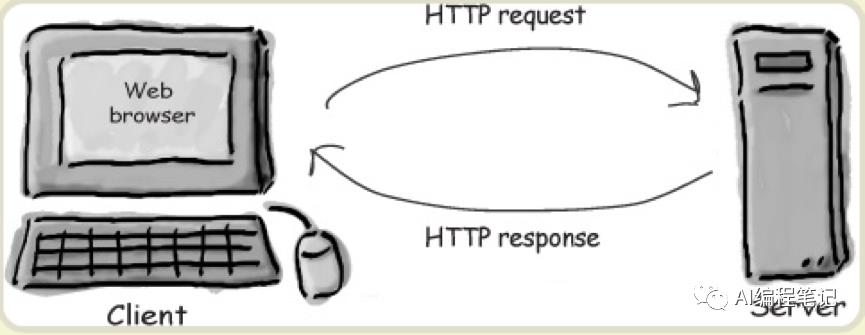
输入URL按回车,浏览器向服务器发送了HTTP请求
服务器根据请求把响应文件发送给浏览器
浏览器分析响应的html,发现其中引用了很多其他文件(CSS文件、JS文件以及image文件等)。浏览器会再向服务器发送请求去获取这些文件
当所有的文件都下载成功后,网页根据HTML语法结构完整地显示在屏幕上
HTTP传输协议
HTML网页结构
scheme:协议(http、https等)
port#:服务器端口
path:访问资源的路径
query-string:参数,发送给http服务器的数据
anchor:跳转到网页的指定锚点位置
HTTP是浏览器与服务器之间进行信息传输需要遵循的一种协议。这种协议其实就是一个简单的请求-响应协议,它指定了浏览器可以发送给服务器什么消息以及浏览器可以得到什么响应。
< HTTP请求 >
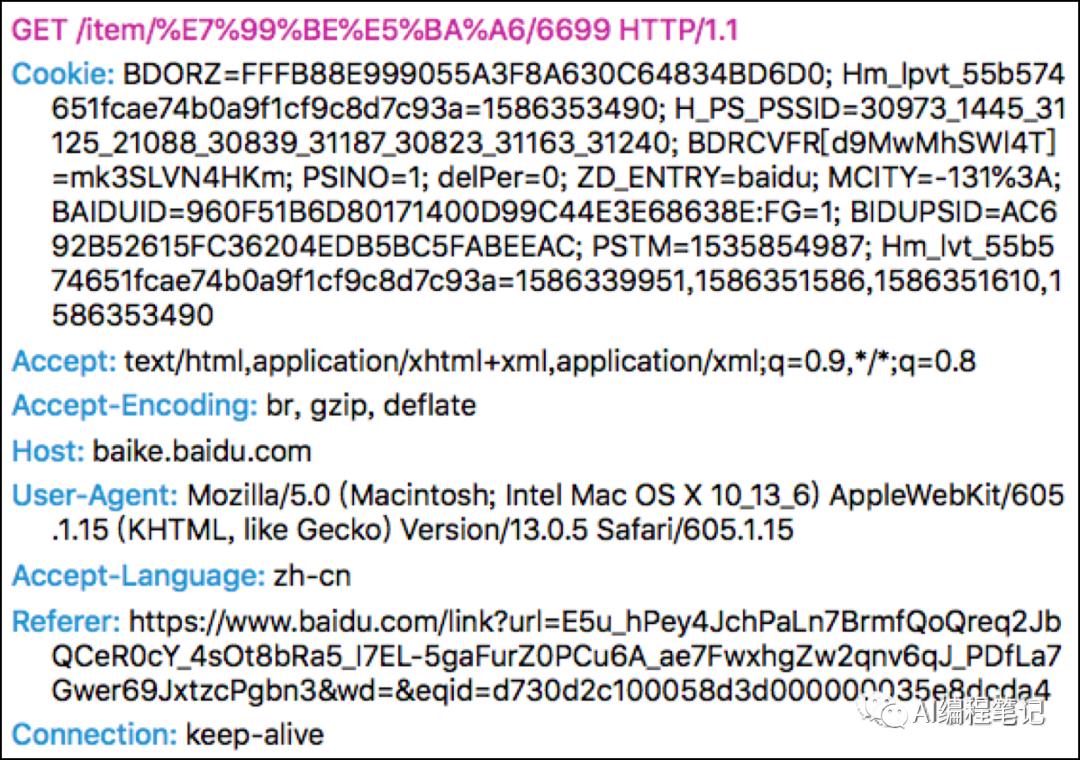
请求行:GET /item/%E7%99%BE%E5%BA%A6/6699 HTTP/1.1,包含三部分:
请求方式:GET,HTTP请求主要有GET和POST两种方法
URL:/item/%E7%99%BE%E5%BA%A6/6699
HTTP协议及版本:HTTP/1.1
常用的请求头有:
Host:主机和端口号
Accept:客户端可接受的内容类型
Accept-Encoding:客户端支持的压缩方式
Accept-Charset:客户端可接受的字符编码集
User-Agent:浏览器名称
Accept-Language:客户端可接受的语言
Referer:页面跳转处,可以表明产生请求的网页的来源
Connection:表示客户端与服务器的连接类型
Cookie:浏览器用这个属性向服务器发送Cookie
Content-Type:POST请求里用来表示消息体的媒体类型和编码
Content-Length:POST请求中请求体的长度
1
xx:表示服务器已成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程2
xx:表示服务器已成功接收请求并已完成整个处理过程,常用2003
xx:表示为完成请求,客户端需要采取进一步细化请求4
xx:表示请求有错误,常用404或4035
xx:表示服务器出现错误,常用500
Cache-Control:这个值表示服务端不希望客户端缓存资源
Connection:keep-alive,回应客户端的Connection
Content-Encoding:告诉客户端,服务器发送的资源采用的压缩方式
Content-Type:告诉客户端,资源文件的类型以及编码方式
Date:服务器发送资源的时间
Server:告诉客户端,服务器的信息
Transfer-Encoding:chunked,告诉客户端服务器分块发送资源
以上是关于网络爬虫前奏:HTTP的请求与响应的主要内容,如果未能解决你的问题,请参考以下文章