HTTP Server : 一个差生的逆袭
Posted 码农翻身
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTTP Server : 一个差生的逆袭相关的知识,希望对你有一定的参考价值。
我刚毕业那会儿,国家还是包分配工作的,我的死党张大胖被分配到了一个叫数据库的大城市,天天都可以坐在高端大气上档次的机房里,在那里专门执行SQL查询优化,工作稳定又舒适。
隔壁宿舍的小白被送到了编译器镇,在那里专门把C源文件编译成EXE程序,虽然累,但是技术含量非常高,工资高,假期多。
我成绩不太好,典型的差生,四级补考了两次才过,被发配到了一个不知道什么名字的村庄,据说要处理什么HTTP请求,这个村庄其实就是一个破旧的电脑,令我欣慰的是可以上网,时不时能和死党们通个信什么的。
不过辅导员说了,我们都有光明的前途。
HTTP Server 1.0
HTTP是个新鲜的事物,能够激起我一点点工作的兴趣,不至于沉沦下去。
一上班,操作系统老大扔给我一大堆文档:“这是HTTP协议,两天看完!”
我这样的英文水平, 这几十页的英文HTTP协议我不吃不喝不睡两天也看不完,死猪不怕开水烫,慢慢磨吧。
两个星期以后,我终于大概明白了这HTTP是怎么回事:无非是有些电脑上的浏览器向我这个破电脑发送一个预先定义好的文本(HTTP Request), 然后我这边处理一下(通常是从硬盘上取一个后缀名是html的文件),然后再把这个文件通过文本方式发回去(HTTP Response),就这么简单。
唯一麻烦的实现,我得请操作系统给我建立HTTP层下面的TCP连接通道, 因为所有的文本数据都得通过这些TCP通道接收和发送,这个通道是用socket建立的。
弄明白了原理,我很快就搞出了第一版程序,这个程序长这个样子:
(注:详情参见文章《》)
看看,这些socket, bind, listen , accept... 都是操作系统老大提供的接口,我能做的也就是把他们组装起来:先在80端口监听,然后进入无限循环,如果有连接请求来了,就接受(accept),创建新的socket, 最后才可以通过这个socket来接收,发送http数据。
老大给我的程序起了个名称,Http Server, 版本1.0 。
这个名字听起来挺高端的,我喜欢。
我兴冲冲地拿来实验, 程序启动了,在80端口“蹲守”,过了一会儿就有连接请求了,赶紧Accept,建立新的socket,成功 !接下来就需要从socket 中读取HTTP Request了。
可是这个receive 调用好慢,我足足等了100毫秒还没有响应 !我被阻塞(block)住了!
操作系统老大说:“别急啊,我也在等着从网卡那里读数据,读完以后就会复制给你。”
我乐得清闲,可以休息一下。
可是操作系统老大说:“别介啊,后边还有很多浏览器要发起连接,你不能在这儿歇着啊。”
我说不歇着怎么办?receive调用在你这里阻塞着,我除了加入阻塞队列,让出CPU让别人用还能干什么?
老大说:“唉,大学里没听说过多进程吗?你现在很明显是单进程,一旦阻塞就完蛋了,想办法用下多进程,每个进程处理一个请求!”
老大教训的是,我忘了多进程并发编程了。
HTTP 2.0 :多进程
多进程的思路非常简单,当accept连接以后,对于这个新的socket,不在主进程里处理,而是新创建子进程来接管。这样主进程就不会阻塞在receive 上,可以继续接受新的连接了。

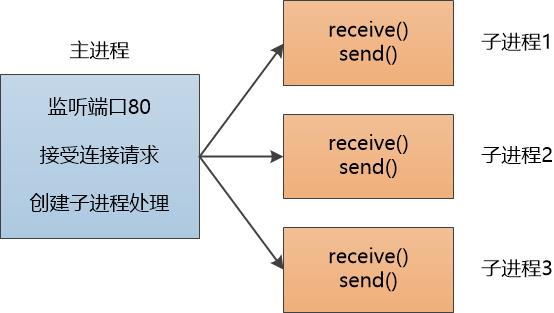
我改写了代码,把HTTP server 升级为V2.0,这次运行顺畅了很多,能并发地处理很多连接了。
这个时候Web 刚刚兴起,我这个HTTP Server 访问的人还不多,每分钟也就那么几十个连接发过来,我轻松应对。
由于是新鲜事物,我还有资本给搞数据库的小明和做编译的小白吹吹牛,告诉他们我可是网络高手。
没过几年,Web迅速发展,我所在的破旧机器也不行了,换成了一个性能强悍的服务器,也搬到了四季如春的机房里。
现在每秒都有上百个连接请求了,有些连接持续的时间还相当得长,所以我经常得创建成百上千的进程来处理他们,每个进程都得耗费大量的系统资源,很明显操作系统老大已经不堪重负了。
他说:“咱们不能这么干了,这么多进程,光是做进程切换就把我累死了。”
“要不对每个Socket连接我不用进程了,使用线程?”
“可能好一点,但我还是得切换线程啊,你想想办法限制一下数量吧。”
我怎么限制?我只能说同一时刻,我只能支持x个连接,其他的连接只能排队等待了。
这肯定不是一个好的办法。
HTTP Server 3.0 : Select模型
老大说:“我们仔细合计合计,对我来说,一个Socket连接就是一个所谓的文件描述符(File Descriptor ,简称 fd ,是个整数),这个fd 背后是一个简单的数据结构,但是我们用了一个非常重量级的东西‘进程’来表示对它的读写操作,有点浪费啊。”
我说:“要不咱们还切换回单进程模型?但是又会回到老路上去,一个receive 的阻塞就什么事都干不了了。”
“单进程也不是不可以,但是我们要改变一下工作方式。”
“改成什么?” 我猜不透老大在卖什么关子。
“你想想你阻塞的本质原因,还不是因为人家浏览器还没有把数据发过来,我自然也没法给你,而你又迫不及待地想去读,我只好把你阻塞。在单进程情况下,一阻塞,别的事儿都干不了。“
“对,就是这样。”
“所以你接受了客户端连接以后,不能那么着急地去读,咱们这么办,你的每个socket fd 都有编号,你每次把一批socket的编号告诉我,就可以阻塞休息了。”
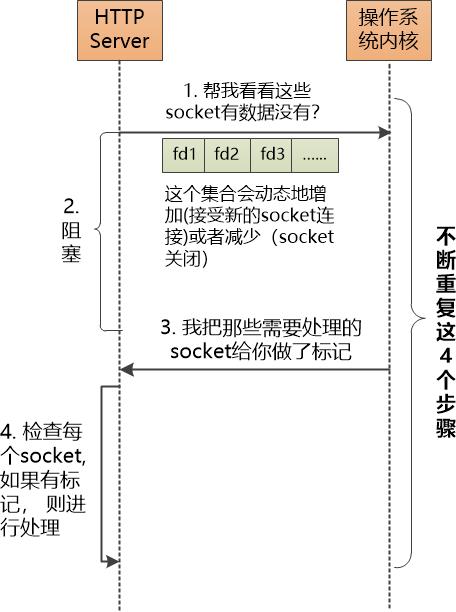
[注:实际上,HTTP Server和操作系统之间传递的并不是socket fd的编号,而是一个叫做fd_set的数据结构]
我问道:“这不和以前一样吗?原来是调用receive 时阻塞,现在还是阻塞。”
“听我说完,我会在后台检查这些编号的socket,如果发现这些socket 可以读写,我会把对应的socket 做个标记,把你唤醒去处理这些socket 的数据,你处理完了,再把你的那些socket fd 告诉我,再次进入阻塞,如此循环往复。”
我有点明白了:“这是我们俩的一种通信方式,我告诉你我要等待什么东西,然后阻塞, 如果事件发生了,你就把我唤醒,让我做事情。”
“对,关键点是你等我的通知,我把你从阻塞状态唤醒后,你一定要去遍历一遍所有的socket fd(实际上就是那个fd_set的数据结构),看看谁有标记,有标记的做相应处理。我把这种方式叫做 select模型。”
我用select的方式改写了HTTP server,抛弃了一个socket请求对于一个进程的模式, 现在我用一个进程就可以处理所有的socket了。
HTTP Server4.0 : epoll
这种称为select的方式运行了一段时间,效果还不错,我只管把socket fd 告诉老大,然后等着他通知我就行了。
有一次我无意中问老大:“我每次最多可以告诉你多少个socket fd?”
“1024个。”
“那就是说我一个进程最多只能监控1024个socket了?”
“是的,你可以考虑多用几个进程啊。”
这倒是一个办法,不过“select”的方式用的多了,我就发现了弊端,最大的问题就是我需要把socket的编号(实际上是fd_set数据结构)不断地复制给操作系统老大,这挺耗资源的,还有就是我从阻塞中恢复以后,需要遍历这1000多个socket fd,看看有没有标志位需要处理。
实际的情况是,很多socket 并不活跃, 在一段时间内浏览器并没有数据发过来,这1000多个socket 可能只有那么几十个需要真正的处理,但是我不得不查看所有的socket fd,这挺烦人的。
难道老大不能把那些发生了变化的socket 告诉我吗?
我把这个想法给老大说了下,他说:“嗯,现在访问量越来越大,select 方式已经不满足要求,我们需要与时俱进了,我想了一个新的方式,叫做epoll。”
“看到没有,使用epoll和select 其实类似,” 老大接着说 :“不同的地方是,我只会告诉你那些可以读写的socket , 你呢只需要处理这些准备就绪的socket 就可以了。”
“看来老大想得很周全,这种方式对我来说就简单得多了。”
我用epoll 把HTTP Server 再次升级,由于不需要遍历全部集合,只需要处理那些有变化的、活跃的socket 文件描述符,系统的处理能力有了飞跃的提升。
我的HTTP Server 受到了广泛的欢迎,全世界有无数人在使用,最后死党数据库小明也知道了,他问我:“大家都说你能轻松地支持好几万的并发连接,真是这样吗?”
我谦虚地说:“过奖,其实还得做系统的优化啦。”
他说:“厉害啊,你小子走了狗屎运了啊。”
我回答:“毕业那会儿辅导员不是说过吗,每个人都有光明的前途。”
后记:最近有几个人问我select和epoll的事情,其实我几年前写过一篇文章的,只是有些小错误,今天整理一下再发一次。
《》
以上是关于HTTP Server : 一个差生的逆袭的主要内容,如果未能解决你的问题,请参考以下文章