搞定 HTTP 协议:HTTP 与网络基础
Posted 零幺小馆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搞定 HTTP 协议:HTTP 与网络基础相关的知识,希望对你有一定的参考价值。
无论是前端工程师、后端工程师、客户端工程师还是测试工程师,HTTP 协议都是我们每天需要打交道的东西。但是对于大多数人来说,也包括我自己,对于 HTTP 协议的学习都是碎片化且不成体系的。然而 HTTP 协议又如此重要,性能优化中一个非常重要的部分就是网络优化,全面理解 HTTP 协议就可以让我们的页面更快,体验更好。
同时,网络也是每一个程序员都应该掌握的底层知识,它与数据结构与算法、操作系统、编译原理等被称为程序员的内功,掌握了内功,我们才能在职场上走的更远。HTTP 协议属于网络协议中重要的一环,因此需要我们全面而深入的掌握它。
其实系统学习 HTTP 协议的材料非常少,像 《HTTP 权威指南》这样的大部头年代也非常久远,所以我最近的学习套路,是在阅读 HTTP/1.1 版本 RFC7230 文档的同时,在极客时间上阅读网络相关的几个专栏。
而在最近的深入学习中我也发现, HTTP 协议的概念众多,常常看了后面忘了前面。就像学习金字塔理论所指出的,通过听讲和阅读能记忆的知识其实是很少的,而且俗话说的好 —— “不动笔墨不读书”,我也希望通过一个系列的写作,更快更好地掌握 HTTP 协议。
本文是系列文章的第一篇 —— 《HTTP 与网络基础》。
起源
1989 年,欧洲核子研究组织(CERN)的蒂姆·博纳斯-李(Tim Berners-Lee)博士提出一个构想:借助多文档之间相互关联形成的超文本(HyperText),连成可参阅的 WWW(World Wide Web,万维网),以帮助远隔两地的研究者们共享知识。

在这个构想中,他提出了 3 项 WWW 构建的关键技术:
URI
HTTP
1990 年 11 月,CERN 研发出世界上第一台 Web 服务器和 Web 浏览器,远隔两地的人们终于可以在网络上共享信息了,但受限于当时网络的速度与技术的限制,网络上的绝大多数资源都是纯文本,所以诞生之初的 HTTP 仅提供 GET 方法,从服务器上获取 HTML 文档,设计相当简陋。此时的 HTTP 协议版本,后来被称为 HTTP/0.9 ,但它并没有作为正式的标准被建立,HTTP/0.9 也含有 HTTP/1.0 之前版本的意思。
1993 年 1 月,NCSA(National Center for Supercomputer Applications,美国国家超级计算机应用中心)研发出 Mosaic 浏览器,它以内联等形式显示 HTML 图像,人们终于可以看到图文混排的 HTML 文档了。
1995年,网景公司发布了 Netscape Navigator 1.0,微软发布了 IE 1.0 和 2.0,随后服务器软件 Apache 以及 HTML 2.0 版本的出现,让 Web 技术突飞猛进的增长。HTTP 也在 Web 技术飞速的发展中,不断地迭代。1996 年 HTTP/1.0 版本正式发布,记载于 RFC1945。虽说是早期版本,但是与现在最常用的 HTTP/1.1 版本差距并不是很大,所以该版本仍然在一些公司使用。
1995 年后,网景和微软的浏览器大战愈演愈烈,两家公司对当时发展中的 Web 标准视而不见,导致写 HTML 页面时,必须考虑兼容性问题,让很多人头痛不已。但不可否认的是,浏览器大战也推动了 Web 的发展。1999 年,HTTP/1.1 发布 RFC2612,虽然相对于 HTTP/1.0 来说改变不大,但却在日后的 20 多年里所向披靡,时至今日,HTTP/1.1 依然是绝大多数公司仍在使用的 HTTP 版本。
HTTP 是什么?
说了这么多 HTTP 的发展历史,那么 HTTP 到底是什么?
在 HTTP/1.1 最新标准 RFC7230 中,是这么定义 HTTP 的:
The Hypertext Transfer Protocol (HTTP) is a stateless application-level request/response protocol that uses extensible semantics and self-descriptive message payloads for flexible integration with network-based hypertext information systems.
HTTP 协议是一种无状态的、处于应用层的、以请求/应答方式运行的协议,使用可扩展的语义和自描述的信息格式,与基于网络的超文本信息系统灵活的相互作用。
在上面的定义中,有几个关键词是需要我们特别留意的,理解了这几个关键词,就可以掌握 HTTP 协议的本质。
无状态
无状态是指每一个请求/响应是被隔离的,后一个请求无法依赖前一个请求中的信息、字段等。也就是说 HTTP 协议不会对请求和响应之间的通信状态进行保存,不做持久化处理。比如,当用户 A 登录后,发起一个查询自己购物车中商品的请求,服务器会给出相应的响应。然而当用户 A 再次发起一个请求,想要查询自己信息的时候,服务器无法依据上一次请求判断用户 A 的身份,必须将用户身份再次告知服务器才可以。
应用层
应用层面向具体的应用提供数据。应用层的协议很多,比如 DNS 专门处理域名及 IP 的相互转换;FTP 专门传输文件;SMTP 专门发送邮件等等。而 HTTP 也是众多应用层协议中的一种,但是它却几乎可以传递一切东西,所以历经 20 余年的发展,依旧经久不衰,覆盖面及广
请求/应答
HTTP 的工作方式是由请求方首先建立连接发起请求,应答方接收到请求后才能做出响应,必须遵循”发起 - 接收“的工作模式。
可扩展语义
高度可扩展的语义,也是 HTTP 协议经久不衰的一个重要原因。从最早的只支持 GET 请求的 HTTP/0.9 版本到现在最常用的 HTTP/1.1,HTTP 协议逐渐增加了很多请求方法、版本号、状态码等等。而且只要服务端和客户端就 HTTP headers 达成语义一致,新功能就可以被轻松加入进来。
自描述消息格式
我们可以自己描述消息,从自己描述的消息中我们可以知道传递的是文本、图片、音频还是视频。
超文本
所谓超文本,就是 HTTP 协议不仅可以传输文本,还可以传输图片、音频、视频以及超链接等复杂的数据。
网络分层到底是什么?
OSI 概念模型
OSI(Open System Interconnection Reference Model),开放式系统互联通信参考模型,也就是我们常说的 7 层模型。从它的名称就可以看出来,OSI 只是一个供参考的概念模型,它从未被真正的实现。
OSI 的 7 层,从上至下分别是:
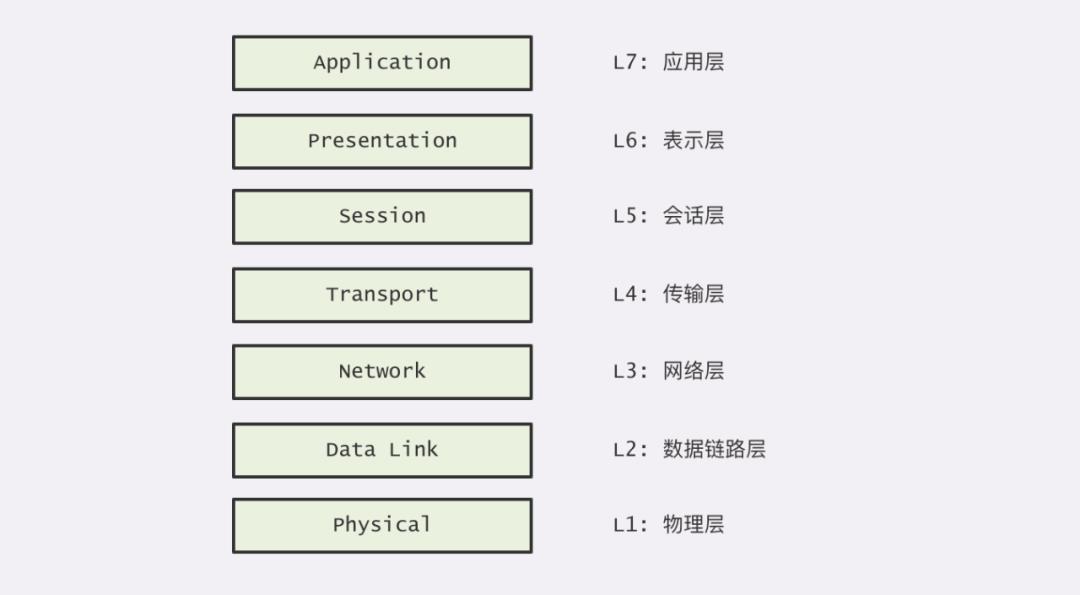
L7 应用层:解决业务问题,面向具体的应用传输数据;
L6 表示层:将消息转换为应用层可以读取的消息;
L5 会话层:建立会话、握手、维持网络的连接状态;
L4 传输层:包括我们熟悉的 TCP 与 UDP 等,解决进程与进程之间的通讯;
L3 网络层:主要包括 IP 协议,负责将报文从因特网上的一个主机发送到另一个主机上;
L1 物理层:电缆、光纤等。
TCP/IP 模型
OSI 只是一个概念模型,而平常工作我们最常用的还是 TCP/IP 模型。TCP/IP 模型其实就是 OSI 模型的简化版本,也就是我们平时所说的 4 层模型。
TCP/IP 的 4 层,由上至下分别是:
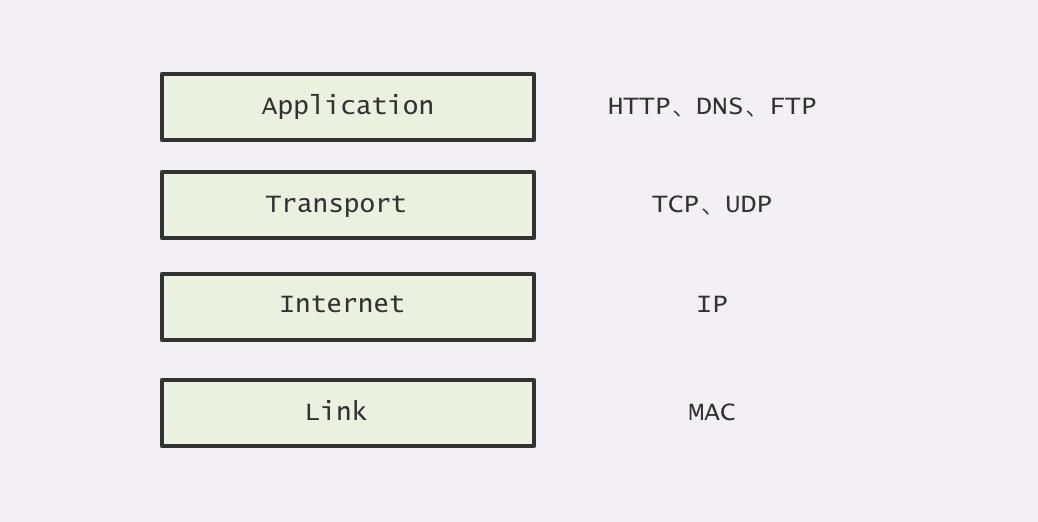
通过上图我们可以看出,其实 TCP/IP 模型与 OSI 模型十分相似,主要是省略了表示层、会话层与物理层的实现。这里每一层的功能实际上与对应的 OSI 模型十分类似,所以就不再罗列了。下面是一张 OSI 模型与 TCP/IP 模型的层级对照图,大家可以通过对照图来总结 TCP/IP 模型中各层的职责。
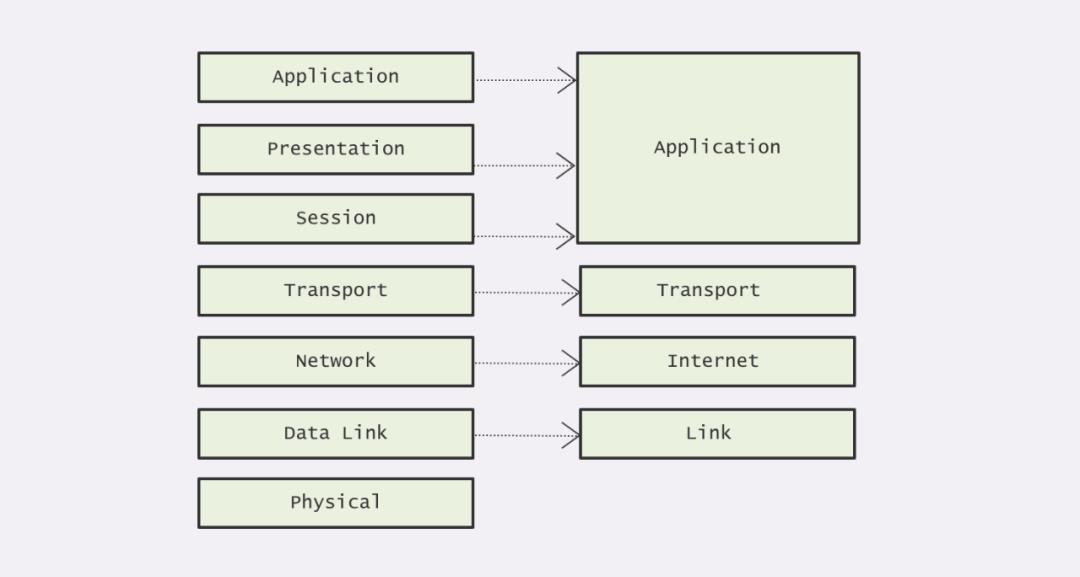
网络分层的好处是,每一次层都只负责自己的任务,其他层的事情完全不需要考虑,层次之间交互的时候,只需要调用接口就可以了。当某一层需要修改的时候,也完全不影响其他的功能。当然,有优势就一定有劣势,每一次进行网络通信的时候,都需要由上至下,一层一层的传递信息,反过来,又要一层一层的向上传递,对于性能的影响是比较大的。
与 HTTP 相关的协议
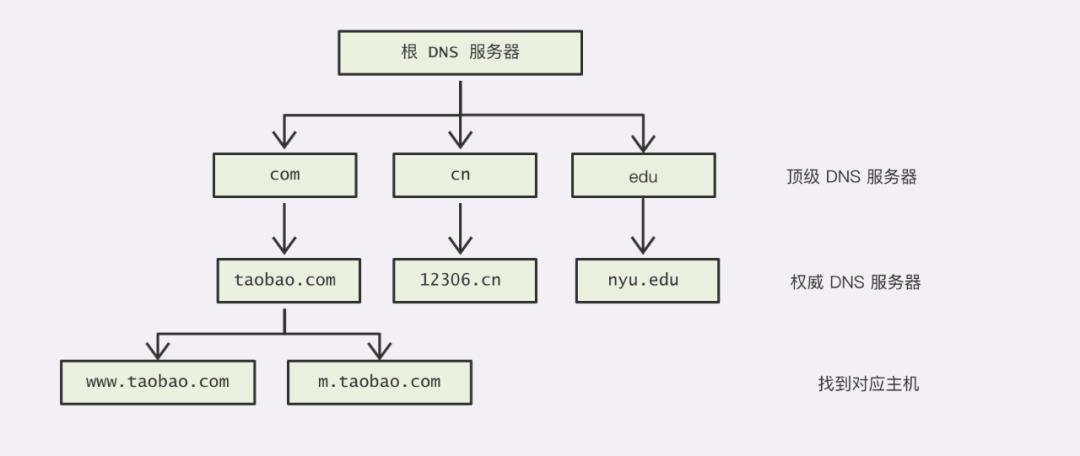
DNS
以 www.baidu.com 为例,从左到右层级逐渐升高,最右侧的 com 称为顶级 DNS 服务器,中间的 baidu.com 称为权威域名服务器,最左侧的 www 就是对应的主机。因为全世界互联网上的电脑实在太多了,所以 DNS 服务器必须要进行分布式管理,并且要承受高并发。因此,DNS 服务器被设计成了一种树状的层次结构,解析域名时逐层递归查询,而最顶端是 13 组根 DNS 服务器。
1. 浏览器缓存
2. 本地 hosts
3. 系统缓存
TCP
TCP 协议位于传输层,提供可靠的字节流服务,保证了数据的完整性以及不丢失。
为了确保数据完整的到达目标处,TCP 协议采用了三次握手的策略:
发送端首先发送一个带 SYN 标志的数据包给接收端;
接收端收到后,回传一个带有 SYN/ACK 标志的数据包,表示确认;
发送端再次回传一个带有 ACK 标志的数据包,表示“握手”结束。
如果传输过程出现异常,TCP 协议会启动重发机制。
IP
HTTP 到底是如何访问 Web 的?
以上的 HTTP、DNS 都属于应用层协议,数据经过封装后,浏览器将应用层的包交给下一层传输层处理。
传输层通常包含两种常用的协议,面向连接的TCP 协议和无连接的 UDP 协议。这里以最常用的 TCP 协议为例。TCP 协议通常处理进程与进程间的通信,所以 TCP 通常带有两个端口,一个是浏览器的端口号,另一个是目标服务器的端口号。这样,操作系统就可以给指定的端口发送包了。
在链路层会添加上 MAC 头部,然后包就可以漂洋过海了。
当服务端的链路层拿到数据后,会逐层向上发送,每到一层拿掉相应的头部,直到传输到应用层,才算真正接收到了浏览器发送过来的 HTTP 请求。
@ Web 页面是怎么呈现的
小结
本文是《搞定 HTTP 协议》的第一篇,主要介绍了 HTTP 协议的相关历史、概念、与 HTTP 相关的协议、网络分层模型等,以帮助大家对 HTTP 形成一个总体上的直观概念。下一篇,我会介绍 HTTP 协议的总体结构,敬请期待。
参考资料
[1] RFC7230
[2] 《图解 HTTP》
[3] 极客时间 - 《透视 HTTP 协议》
[4] 极客时间 - 《趣谈网络协议》
[5] 极客时间 - 《Web 协议详解与抓包实战》
以上是关于搞定 HTTP 协议:HTTP 与网络基础的主要内容,如果未能解决你的问题,请参考以下文章