在Scrapy中如何使用aiohttp?
Posted 未闻Code
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在Scrapy中如何使用aiohttp?相关的知识,希望对你有一定的参考价值。
当我们从一些代理IP供应商购买代理IP时,他们可能是提供一个网址供我们查询当前可用的代理IP。我们周期性访问这个网址,拿到最新的IP,再分给爬虫使用。
最正确的做法,是单独有一个代理池程序,它负责请求这个网址,获取所有的代理IP,然后维护到一个池子里面。爬虫只需要从这个池子里面拿就可以了。
但有时候,因为某些原因,我们可能暂时无法或者暂时没有时间开发代理池程序,于是不得不直接让爬虫去请求代理IP供应商提供的网址获取代理IP。这个时候我们就面临了一个问题——爬虫应该怎么去请求代理网址?特别是当你使用的是Scrapy,那么这个问题变得尤为麻烦。
我们一般在Scrapy的下载器中间件里面设置爬虫的代理,但问题来了,在下载器中间件里面,你怎么发起网络请求?
于是很多人退而求其次,在下载器中间件里面,用requests来请求代理供应商的网址,例如:
import requestsimport jsonimport randomclass ProxyMiddleware:def process_request(self, request, spider):ip_info = requests.get('代理供应商的网址').json()ip_list = ip_info['proxy']ip = random.choice(ip_list)request.meta['proxy'] = ip
我们知道,Scrapy是一个异步爬虫框架,而requests是一个同步网络库。在Scrapy里面运行requests,会在requests等待请求的时候卡死整个Scrapy所有请求,从而拖慢整个爬虫的运行效率。
当然,你可以在Scrapy的爬虫里面,每次发起待爬请求前,先yield scrapy.Request('代理供应商网址'),请求一次代理供应商的网址,并在对应的回调函数里面拿到代理IP再发正常的请求。但这样的写法,会让爬虫代码变得很混乱。
为了避免这种混乱,在下载器中间件里面获取代理IP当然是最好的,但又不能用requests,应该如何是好呢?
实际上,我们可以在Scrapy里面,使用aiohttp,这样既能拿到代理IP,又能不阻塞整个爬虫。
Scrapy现在官方已经部分支持asyncio异步框架了,所以我们可以直接使用async def重新定义下载器中间件,并在里面使用aiohttp发起网络请求。
为了说明如何编写代码,我们用Scrapy创建一个示例爬虫。正常情况下,这个爬虫使用5个并发,每个请求延迟1秒访问http://exercise.kingname.info/exercise_middleware_ip/<page>并打印网站返回的结果,如下图所示。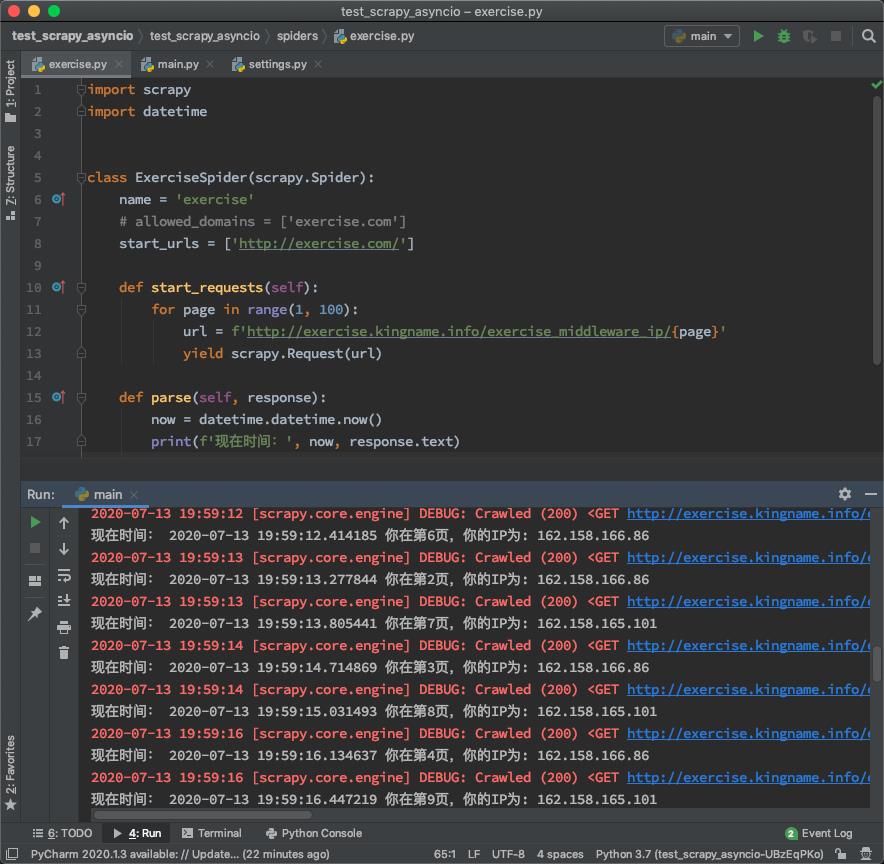
请求频率和延迟如下图所示:
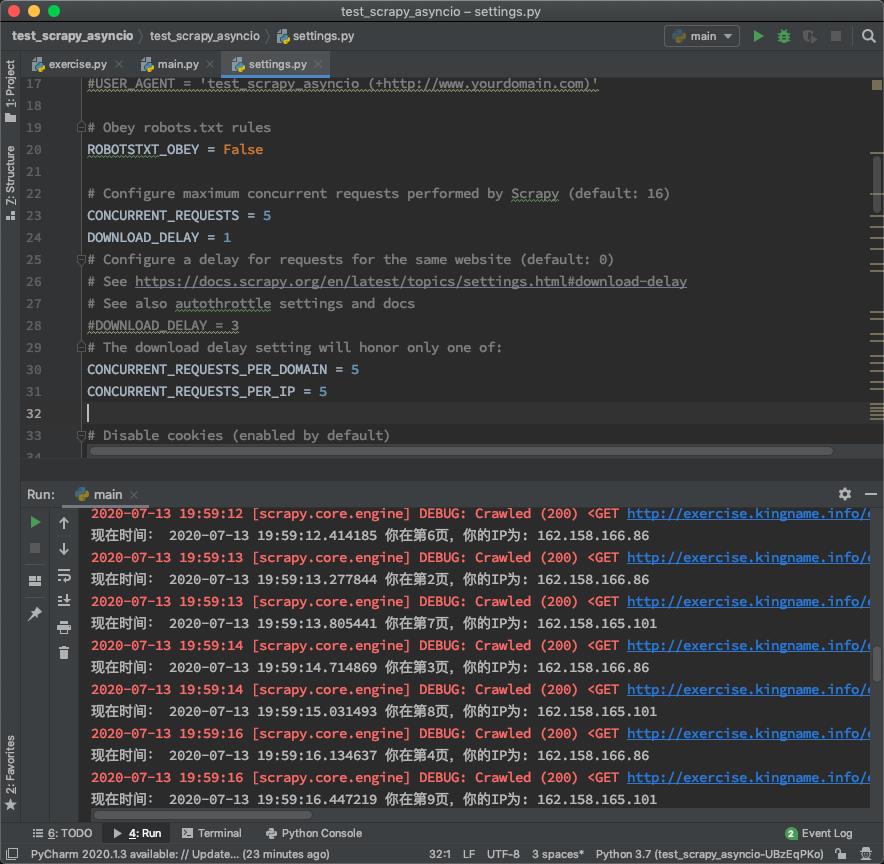
请求频率接近1秒钟一次。
现在,我们创建一个中间件,在这个中间件里面,使用requests请求一个需要延迟5秒钟才会返回的网址:
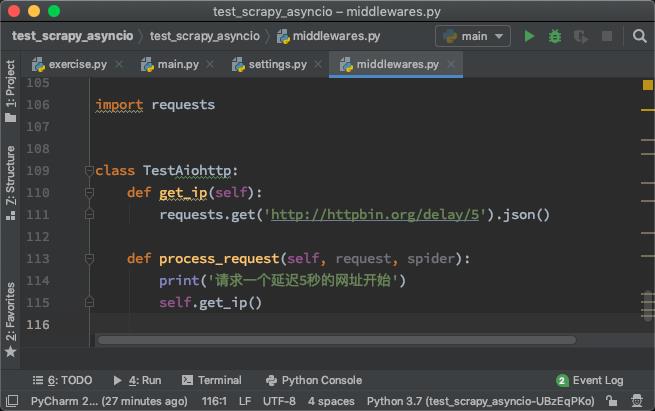
启动这个中间件,可以看到爬虫的速度明显变慢,几乎每5秒才能有一次返回,如下图所示:
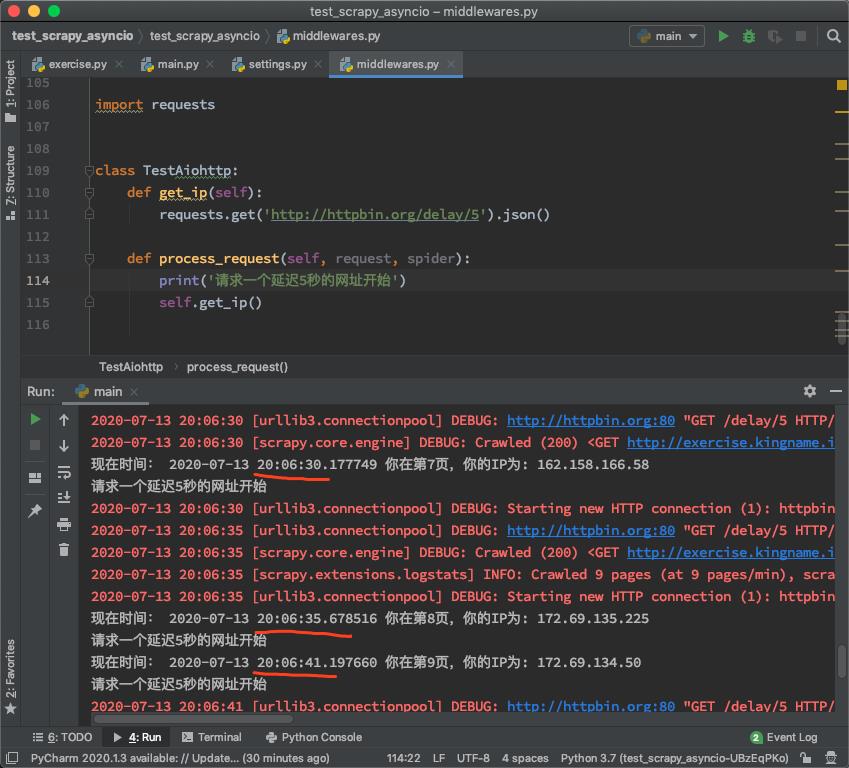
从图中可以知道,requests卡住了整个Scrapy。在请求这个延迟5秒的网址时,Scrapy无法发起其他的请求。
现在,我们把requests替换为aiohttp,看看效果。
import asyncioimport aiohttpclass TestAiohttp:async def get_ip(self):async with aiohttp.ClientSession() as client:resp = await client.get('http://httpbin.org/delay/5')result = await resp.json()print(result)async def process_request(self, request, spider):print('请求一个延迟5秒的网址开始')await asyncio.create_task(self.get_ip())
如下图所示:
现在,我们直接运行这个爬虫,理论上应该会遇到一个报错,如下图所示:
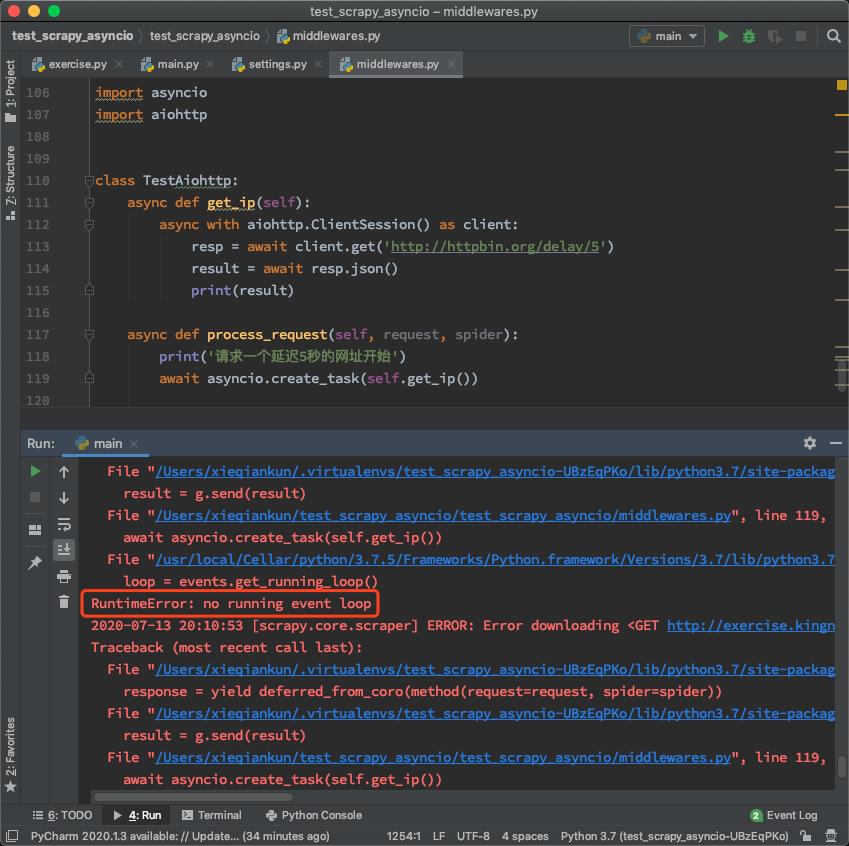
这是正常现象,要在Scrapy里面启用asyncio,需要额外在settings.py文件中,添加一行配置:
TWISTED_REACTOR = 'twisted.internet.asyncioreactor.AsyncioselectorReactor'添加了这一行配置以后,再次运行爬虫,可以看到效果如下图所示:
刚刚启动的时候,爬虫会瞬间启动5个并发,所以会同时打印出请求一个延迟5秒的网址开始5次。然后稍稍停5秒,这5个请求几乎同时完成,于是同时打印出这个延迟网址的返回信息。接下来,后面的请求就是每秒一个。
这说明,Scrapy的异步机制成功启动了。首先第一个请求延迟网址发起以后,由于当前请求数还没有达到最大并发5,所以立刻就会利用这个等待时间发起第二个请求。由于现在请求数还不够5个,于是马上又会发起第三个请求,直到凑够5个并发请求为止。
当第一个请求延迟网站返回以后,Scrapy去请求正式的第一页。在等待第一页返回的过程中,第二个延迟请求完成并返回,于是Scrapy去请求正式网址的第二页……
总之,从Scrapy打印出的信息可以看出,现在Scrapy与aiohttp协同工作,异步机制正常运转。
以上是关于在Scrapy中如何使用aiohttp?的主要内容,如果未能解决你的问题,请参考以下文章