MySQL集群新技术——MGR
Posted 运维镖局
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL集群新技术——MGR相关的知识,希望对你有一定的参考价值。
有一种技术,让mysql复制不再是Change Master To,也不再让你手动Failover,而且还能多点写入,你听了会不会很兴奋?天下还有这样的复制技术么?
背景
确保数据库稳定运行是DBA核心价值之一。通过搭建灾备库,利用复制技术同步主库的数据更新,在主库不可用时,启用备库可以快速恢复数据库服务,减少对业务的影响,同时,备库也可用于负载均衡、数据备份、统计报表等场景。带来诸多好处的同时,自然也有其弊端:增加了额外的硬件、维护成本,以及复制中主从数据延迟或不一致等多种问题。MySQL在3.23.15版本中新增了复制功能,接下来是一系列的增强和优化:row based,半同步复制,GTID,多线程,多源复制,组复制等,本文重点讨论2016年底官方GA的Group Replicaion(下文简称MGR)。
复制技术
上图为事务提交过程中不同的复制技术的处理方式,分为异步复制,半同步复制,验证复制和集群复制。
异步复制。这是当前广泛使用的复制方式,事务在主库完成提交,binglog中记录事务数据,从库同步binlog并在本地应用binlog中的事务。这种方式对主库性能几乎没有影响,最大的问题是同步延迟,在主库发生故障时无法保证从库已经完成数据同步,从而造成数据丢失。
半同步复制。5.5推出的新功能,主库在事务提交时,保证至少收到一个从库已经收到该事务数据的确认信息之后完成事务提交,这对主从间的网络通信有一定要求,当然也减低了主从之间的复制延迟,减少切换过程中的数据丢失。
验证复制。MGR就是基于验证的复制技术,也是本文的主角。在半同步复制的基础之上,各个节点接受事务数据,并进行冲突验证,所有节点通过验证后再进行本地提交,反之回滚。这种方式以集群方式提供服务,可多节点写入,并确保数据的强一致性。当然,冲突检测、集群通信等额外的逻辑会带来整体的性能下降。
集群复制。这种机制下,各节点获得事务数据并进行本地提交,由仲裁者决定最终提交或回滚。分两种方式:事务源仲裁和集群选取仲裁者。
对比不同的复制机制,可以看出复制技术一直在复制节点(从库)对事务的响应策略上不断地优化,从异步复制中事务完成后通过binlog同步,到半同步中响应接收,验证复制中的冲突检测,到集群复制的本地应用。随着复制节点对事务的响应方式发生变化,数据一致性不断加强,复制延迟不断减低,而整体的性能也会随之降低。选择哪种复制技术是在数据一致性和性能两者之间的一个权衡,异步复制和半同步业内已经使用广泛,下面我们讨论MGR的原理和特性,为MySQL高可用选型提供一些参考。
MySQL Group Replication
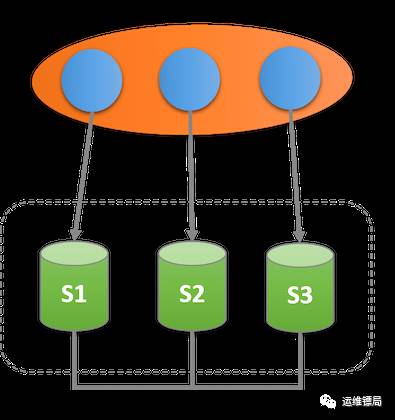
上图是3节点的MGR集群结构,对于应用来说,可以选择访问(读写)集群任何一个节点。对于MySQL Server来说,在事务提交之前和普通的MySQL Server没有差别,事务提交时,先将事务广播到集群,各节点进行冲突检测并返回结果,最后整个集群进行事务的提交或回滚。
MGR架构
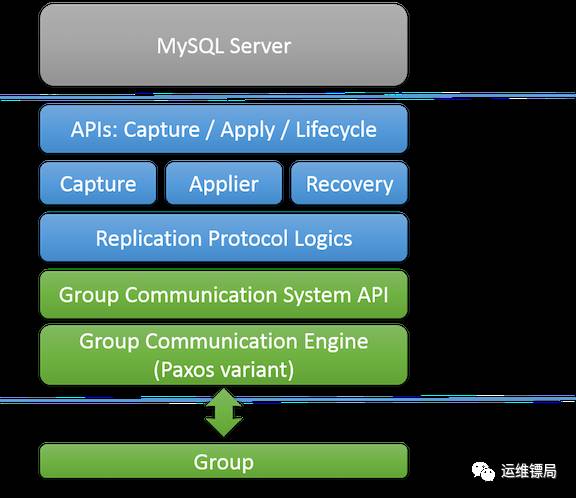
MGR中几个重要的组件:
API层。负责完成和MySQL Server的交互,获取server的状态,截获事务提交,干涉事务提交或者回滚。
组件层。特定功能的组件,Capture负责收集事务执行相关信息,Applier负责应用集群事务到本地,Recovery负责新节点的数据恢复
复制层。负责冲突验证,接收和应用集群事务。
集群通信层。 基于Paxos协议的集群通信引擎以及和上层组件的交互接口。
集群状态
在MGR中的节点状态迁移:
组成集群的所有节点的状态集合就是集群状态,若干个节点状态的变化带来整个集群的状态变化。节点在进行数据同步的同时,也需要同步集群状态,感知所属集群的状态变化,比如节点的加入,离开。
集群通信
作为MGR的核心,集群通信引擎完成集群成员之间的状态通信,集群状态决议,事务的 广播等,保证集群内成员执行同样的事务序列,并最终达成一致集群状态的变化。
Paxos协议
分布式系统中需要解决一个重要问题就是各节点对某一个状态或变化达成一致。在MGR 集群中,多个节点写入数据,如何保证集群内成员执行同样的事务序列,并最终达成一致,以及节点故障时主集群的选举。
Paxos算法用于解决上面这些问题。
故障探测
复制技术的出现就是为了解决单点问题。对于每一个节点来说,单点故障都有可能发生。MGR集群中,节点之间保持心跳检测,每个节点从自身出发感知集群中其他节点的变化。
正常运行时,任意2个节点都可以正常通信。如果节点A对节点B的检测失败,则发起一个对B节点状态的质疑,之后整个集群进行决议,如果其他节点均探测失败,则集群决定剔除节点B,并同步改信息到所有在线节点。对于节点B,他会发起对所有节点的质疑,但无节点与其达成一致,则为无效的质疑。
集群选举
选举的目的其实是确定主集群是否存在,按照多数服从少数的原则,选举过程中,多数达成一致的节点组成了主集群。
节点数为1,则为单点。
节点数为2,任何一个节点故障都无法进行选举-参与选举的节点总小于节点数。
节点数为3,在一个节点故障时,其余2个节点可以做出一致选举节点数为n,n = 2 x f + 1,则可以当有小于f个节点故障时,集群可以完成主集群选举。
这也是为什么MGR推荐至少3节点部署的原因,那是不是一定要奇数个节点呢,从选举 的角度看,只要大部分节点达成一致即可,和节点总数奇偶无关。
网络分区
如果一个集群由于网络原因,形成了2个或多个子集群,分2种情况:
子集群中存在一个节点数大于(n-f),则该集群成为主集群,选举可正常进行。
反之,则需要人为指定主集群成员。
事务验证
MGR中,当事务在某个节点提交时,该节点并不会马上提交,而是通过MGR插件将事务广播到集群中,在集群通信中,存在一个动态的全局事务队列,所有节点提交的事务都带有全局唯一标识,并以其进入队列的时间点确定先后顺序。对于这个全局的事务队列:
所有的节点都以此队列进行事务的提交,则所有节点总是以相同的顺序提交同样的一系列事务,保证了整个集群的数据强一致性。
事务进入队列后,所有节点都会进行冲突验证,对于在不同节点提交且有冲突的事务,总是先进入队列的事务通过验证,而其他的则失败。
此队列的维护以及通过此队列完成的事务验证过程既是验证复制的重要环节也是性能损耗点。
事务冲突的验证目标队列为队列中先于其进入队列的事务。
验证的原理就很清晰了,MGR要求所有表必须有主键,在全局事务队列中进行主键冲突检测,就可以验证正在验证的事务中,是否存在与队列中事务有相同的主键,存在则验证失败,反之通过。
节点恢复
此过程发生在新节点加入集群时,也就是节点状态中的RECOVERING。在成为一个在线节点之前,新加入节点需要完成数据的同步和追平。
备份导入。为减少对donor节点的影响,建议使用最近的备份初始化新节点,这样新节点和集群的数据延迟就相对较少,而且在后续步骤中,采用异步复制来同步数据,如果初始化的备份时间点之后的binlog已经删除,则会导致无法同步。
Donor节点选择。新节点会选择一个在线节点作为donor节点,donor节点提供新节点与它的延迟数据。同时,集群各节点写入一个view change 事件到binlog中,此事件用于新节点判断是否已经同步完延迟数据。
数据同步。新节点开始同步donor节点,并开始参与集群通信,缓存集群事务。
数据追平。当和dornor节点完成同步后,新节点开始应用步骤3中缓存的集群事务,当缓存数据全部应用,整个恢复过程完成。
Flow Control
由于各节点在本地完成事务应用,如果各节点的吞吐量(集中在IO上)不一样甚至差距较大,则会导致在一个时间点上各节点的数据不一致(脏读)。因而需要对整个集群的压力进行控制,尽可能使集群在保证一致性的基础上以最大吞吐量运行。流控制主要做两件事情:监控和控制。
监控 。周期性(1秒)收集节点队列长度和事务信息并同步到集群。
控制。在一个监控周期内,根据统计监控数据来决定下一个周期整个集群的事务数。这个事务数由集群中性能最差的节点的性能数据决定。
如果启用流控制,节点上验证队列,应用队列的堆积长度达到相应的配置值就会触发流控制,相关参数:
group_replication_flow_control_mode 是否开启流控制 group_replication_flow_control_certifier_threshold 验证队列堆积上线 group_replication_flow_control_applier_threshold 应用队列堆积上线
建议
稳定且良好的网络环境。MGR集群中节点中会频繁地通信,状态同步,事务同步都直接影响整个集群的性能。稳定的网络环境可以减少集群状态的变化,良好的网络性能可提高集群吞吐量。
节点硬件配置一致。性能最差的节点决定集群的性能,各节点的硬件差异带来节点性能的差异,则集群在处理事务时受限于最差性能的节点。
节点数3到9个。同时一个节点故障不影响集群通信要求集群节点数为3。节点数越多,整体的性能下降越多,官方限制了节点数最大不超过9个。
InnoDB。MGR只支持事务性存储引擎,InnoDB 5.7已经是默认存储引擎
Primary key。验证过程需要通过主键来检测冲突,为innodb表指定主键也是InnoDB表的优化。
Performance Schema。集群状态,节点性能等信息都会写入这个schema的相应表中。
GTID。用于生成事务的全局唯一标识,以及恢复过程中确定延迟数据。
应用感知提交失败。验证复制的机制决定了事务的提交会因为验证失败进行回滚,所以应用程序需要获取事务的执行结构,并对失败的事务做对应处理
限制
不支持binlog checksum
不支持savepoint
不支持gap locks
不支持lock tables, unlock tables
多主模式不支持多节点同时对一个表进行DDL vs DDL/DML
多主模式不支持SERIALIZABLE隔离级别
多主模式不支持多级关联外键
最后,祝各位:
需要的备份总是有效的
账号授权总是恰到好处的
SQL总是在索引上的工单都是被驳回的
慢查询都是只跑一次的
研发眼中你是万能的
参考
[MGR]
[Gorda]
[Paxos])
[Flow_control]
[Database_state_machine_and_group_communication_issues]
[Paxos]
[Integrity_Dangers_in_Certification_Based_Replication_Protocols]
以上是关于MySQL集群新技术——MGR的主要内容,如果未能解决你的问题,请参考以下文章
Mysql 8 group replication组复制集群单主配置图解
技术分享 | 利用GreatSQL部署MGR集群,并完成添加新节点 滚动升级切主(超详细)...