MySQL集群数据问题修复小记
Posted 杨建荣的学习笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL集群数据问题修复小记相关的知识,希望对你有一定的参考价值。
这是学习笔记的第 2249 篇文章
读完需要
速读仅需7分钟
最近有一套集群有数据不一致的报警,最开始没有引起注意,整体的拓扑结构如下,这是一个偏日志型写入业务,上层是使用中间件来做分库分表,数据分片层做了跨机房容灾,一主两从,而且基于Consul域名管理,也算是跨机房高可用。
因为近期需要把这一套集群跨机房迁移到新机房,整体的方案和设计都算是高大上的,根据之前的切换都是秒级(2-3秒左右)闪断完成,业务初期是不需要做任何调整的,整体来说对业务是平滑无感知的。
在迁移前在处理主从数据不一致的情况时,发现问题有些蹊跷,总是有个别的数据在从库会出现自增列冲突的情况,设置了从库slave_exec_mode为idempotent幂等后,能够临时解决问题,但是总归是不严谨的,所以和团队讨论了一番,决定重构从库。
我们认为当前的拓扑架构是这样的,打算是基于物理备份的模式来做。
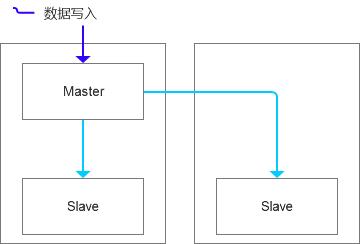
没想到这个过程中因为数据量较大,备份中基于虚拟环境,IO负载很高,导致MHA的ping insert检查超时失败,所以我们看到的一个数据分片的拓扑结构是这样的。(MHA目前不允许跨机房自动切换)。
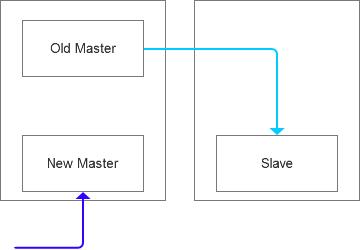
碰到这个问题,着实让我有些抓狂,而因为Consul健康检查不严谨的原因,有一部分的数据其实是写入到原来的两个Master上面了。这种混写持续了一段时间,而雪上加霜的时,这个过程的报警有不好使了,确实比较尴尬,所以我们需要立刻采取有效措施来修复数据。
分析了整体的数据情况,如果保留已有的拓扑结构,建立反向复制关系,应该是比较合理的,但是New Master到Old Master的反向复制关系建立失败(因为binlog保留时间短,有缺失,雪上加霜2.0),我们决定先把数据源切换到原主库Old Master,这个时候新主库上面的数据势必会比主库上要多,但是我们在这个时候还有一些缓和的余地。
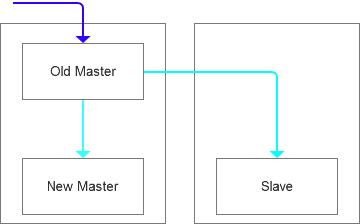
这个时候搭建从库的过程是很关键的,因为整个环境没有一个基准了,需要快速修复,我们开始基于时间范围做两端数据的比对工作,整个工作比想象的扼要快一些。
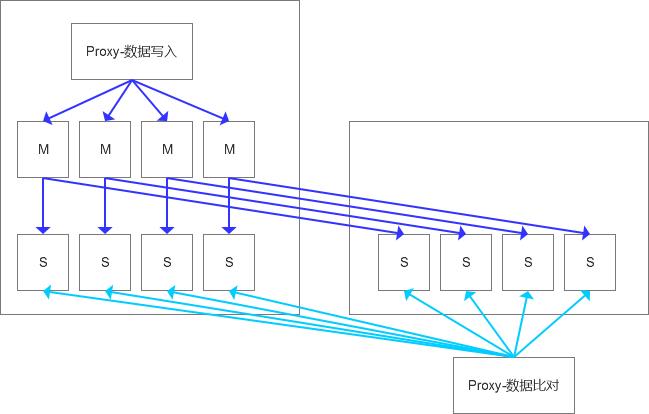
大体的思路就是在新机房搭建一个新的中间件,配置两套schema环境,这样就可以比对两个数据库中的数据情况了,我从数据量小的一些表开始逐步排查,经过一些比对,排除了这个过程中数据混写的状态。
数据状态整体是这样的:
| old master | new master |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
| 8 | 8 |
| 9 | |
| 10 | |
| 11 | |
| 15 | 15 |
| 16 | 16 |
| 17 | 17 |
所以在确认之后,我们开始快速搭建从库,停止了MHA之后,我们直接停止了New Master实例,,然后直接拷贝整个数据目录到跨机房的环境中,这种方式简单粗暴,但是确实有效。有的朋友肯定会说这个过程不严谨,一定会丢数据,确实是,但是我们打算很快把数据源切回来。
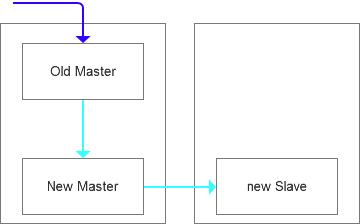
因为数据比对的过程是比较敏感的,基本都是全表扫描,而且在当时的情况下,能够完成数据比对我们才能够真正放心数据不是我们理解中的“随机写”,所以这个过程是确保要做验证的,验证完后有细微的数据修复,可以直接修复,整体还是可控的。所以在完成从库之后,我们把数据源切回了New Master,毕竟这是经过稽核确认的一个准确的数据源。
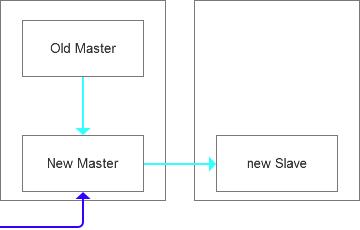
在这个基础上,我们继续完成第二阶段的从库部署,即把跨机房的从库停掉,然后直接复制文件到原来Old Master中,整个过程对于业务都是影响最低的。
当然在这个过程中着实发现了很多低级错误,我们需要对整个问题复盘,继续修正。
我在做运维操作的时候,经常给同事提到两件事情:
1)怎么证明你的操作是正确的
2)怎么保证你的操作是可控的
如果能够做到以上两点,别人也基本挑不出一些硬性问题。
以上是关于MySQL集群数据问题修复小记的主要内容,如果未能解决你的问题,请参考以下文章