ES中关于analyzer的再理解
Posted Ai踩坑王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES中关于analyzer的再理解相关的知识,希望对你有一定的参考价值。
ES中关于analyzer的再理解
内容:昨天写的,对analyzer理解不清,导致search结果与预想的有偏差,今日就es的index analyzer 和 search analyzer再做一次深入理解。
正文开始:
文章结构分成四大部分
数据-分词器
对比试验
总结
补充
文中有关analyzer的内容,不再赘述。这里谈到的analyzer会分别从index time 和 search time 两个角度出发
1. 数据-分词器
| Title | tokenizer_ik_max_word | tokenizer_ik_smart | tokenizer_standard |
|---|---|---|---|
| 快点吧 | 快点,吧 | 快点,吧 | 快,点,吧 |
| 我很快乐 | 我,很快,快乐 | 我,很,快乐 | 我,很,快,乐 |
| 乐起来了 | 乐,起来,来了 | 乐,起,来了 | 乐,起,来,了 |
2. 对比试验
2.1 movie1
# 修改默认PUT movies1{"settings": {"index": {"analysis.analyzer.default.type": "ik_max_word"}},"mappings": {"_doc": {"properties": {"title": {"type": "text"}}}}}
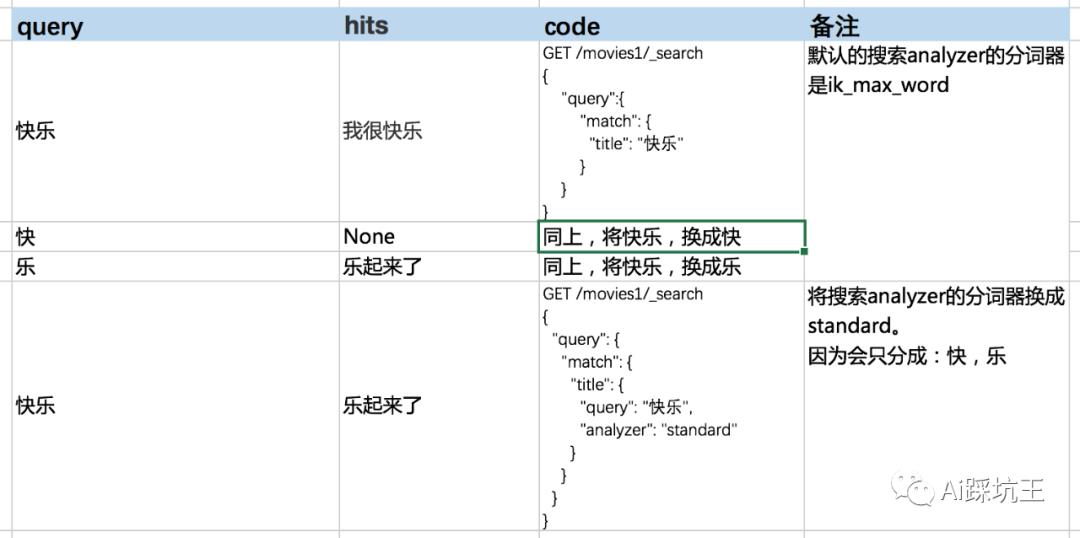
index_analyzer定义为默认 ik_max_word
search_analyzer定义为默认 ik_max_word
2.2 movie2
PUT movies2{"settings": {"analysis": {"analyzer": {"ik": {"tokenizer": "ik_max_word"}}}},"mappings": {"_doc": {"properties": {"title": {"type": "text"}}}}}

结论:
index_analyzer定义为默认standard
search_analyzer定义为默认standard
es中全局默认都是standard
这种是和我们引入自定义analyzer初衷不符的
2.3 movie3
PUT movies3{"settings": {"analysis": {"analyzer": {"ik": {"tokenizer": "ik_max_word"}}}},"mappings": {"_doc": {"properties": {"title": {"type": "text","analyzer":"ik"}}}}}
查询结果:

结论:
index_analyzer定义为ik_max_word
search_analyzer定义为ik_max_word
3. 总结

明确知道了index_analyzer、search_analyzer是什么时,方便我们根据查询结果快速定位问题,同时也可以省略很多不必要的参数设定
4. 补充
编辑好my.dic,里面是我们不希望被拆分的词
填到<entry key ="ext_dict">my.dic</entry>
重启服务生效
参考
感谢前辈指引
https://www.elastic.co/guide/en/elasticsearch/reference/6.4/analyzer.html
https://www.itcodemonkey.com/article/7418.html
https://blog.csdn.net/tclzsn7456/article/details/79957545
https://www.elastic.co/guide/en/elasticsearch/guide/current/_controlling_analysis.html
https://github.com/medcl/elasticsearch-analysis-ik
https://blog.csdn.net/qq_30581017/article/details/79583557
https://www.jianshu.com/p/f178e59ffaf2
推荐关注
也不必如此
长按识别左侧二维码
关注我哈
以上是关于ES中关于analyzer的再理解的主要内容,如果未能解决你的问题,请参考以下文章