美团 EasyReact 源码剖析:图论与响应式编程
Posted 知识小集
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了美团 EasyReact 源码剖析:图论与响应式编程相关的知识,希望对你有一定的参考价值。
前言
18 年 7 月美团开源了 EasyReact,告知 ios 工程师们响应式编程和函数式编程并非不可分离,似乎一出来就想将 ReactiveCocoa 踢出神坛。该框架使用图论来解决响应式编程确实是一个颠覆性的思想,由于 ReactiveCocoa 的各种弊端让很多团队望而却步,而 EasyReact 的出现无疑让很多人重拾对响应式编程的希望。
官方资料:
EasyReact GitHub (https://github.com/meituan/EasyReact)
只需要大致看一下官方的介绍,就很容易理解到图论在响应式编程中扮演的角色,不管如何复杂的响应链都能通过有向有环图来表示,而数据的流动依赖深搜或广搜。单从框架的理解难易程度来看,EasyReact 完胜。
本文介绍 EasyReact 的源码技术细节,由于框架代码量比较大,所以只会较为抽象的介绍比较核心和重要的部分,并且希望读者能优先阅读官方资料以降低理解本文的成本。
一、框架整体认识
首先,我们需要脱离具体的业务,从图论的要素来思考框架的构成。
既然是图,那必然有节点和边,框架有两种结点,一种是 EZRNode<T>泛型标准节点,一种是任意对象;框架也有两种边,一种 EZRTransform 可变换的边,一种是 EZRListen 监听边,当然边的衍生类很多并且实现了数个协议。
在控制器中写这样一段代码:
- (void)viewDidLoad {
[super viewDidLoad];
EZRMutableNode<NSNumber *> *nodeA = [EZRMutableNode new];
EZRMutableNode<NSNumber *> *nodeB = [EZRMutableNode new];
[nodeB linkTo:nodeA];
[[nodeB listenedBy:self] withBlock:^(NSNumber * _Nullable next) {
NSLog(@"nodeB 改变:%@", next);
}];
}
创建两个可变的节点,并且让 nodeB 连接到 nodeA,同时让 self作为 nodeB 的监听者。-linkTo: 和 -listenedBy: 都是语法糖暂时不用管具体含义,这段代码转换为一张图如下:

边有两个很重要的属性 from (强引用) 和 to (弱引用),from到 to 的方向就是数据流动的方向。图中的 an EZRTransform 和 an EZRListen 分别是可变边和监听边的一个实例,箭头的方向表示数据流动的方向。当执行了以下代码过后:
nodeA.value = @10;
打印:
nodeB 改变:10
@10 这个对象通过图中箭头的方向依次传递,最终由 self 捕获到并打印出来。这就是框架的一般逻辑,结构是易懂且清晰的,通过对边的各种逻辑处理来达到控制数据传递的目的。更具体的东西请看官方文档和源码。
二、内存管理策略
在一个响应链中,始终是数据的消费者持有数据的提供者。也就是说,数据流动的方向往往和强引用方向相反,前面那张图反过来就是强引用关系:
self --> an EZRListen --> nodeB --> an EZRTransform --> nodeA
因为在业务中,监听者节点往往关系到具体业务,没有监听者那么其它节点就没有了存在的意义,所以框架的思想是使用监听者来作为结点的最终强持有者。
下面通过节点与边的两种连接方式验证内存管理策略。
监听者连接实现
[[nodeB listenedBy:self] withBlock:^(NSNumber * _Nullable next) {}];
通过阅读源码得知强引用关系如图(箭头表示强引用):
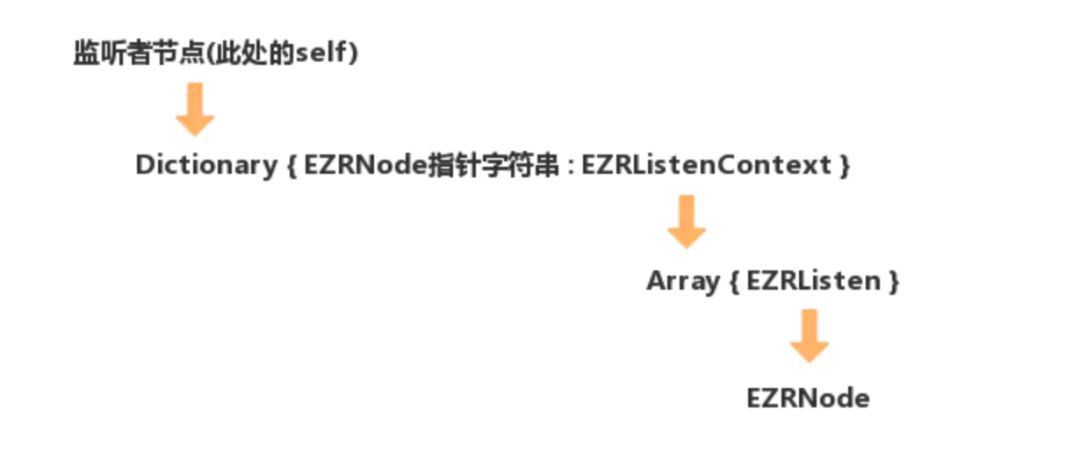
图中已经很明显了,只要监听者节点释放,其它的对象都将不复存在。而其中的引用关系恰好能表示实现监听的数据结构,使用Dictionary是为了让监听者能响应不同节点的监听,后面使用Array是为了让监听者能对同一节点进行多次监听,结合源码来看应该很容易就理解了。
同时,由于EZRNode的改变要传递到监听者节点,所以必然会有必要的反向弱引用,这里就不多说了。
节点连接实现
EZRMutableNode<NSNumber *> *nodeA = [EZRMutableNode new];
EZRMutableNode<NSNumber *> *nodeB = [EZRMutableNode new];
[nodeB linkTo:nodeA];
通过阅读源码得知强引用关系如图(箭头表示强引用):

实际上框架的图结构就是以上两种连接方式的组合,我们用强引用的关系来分析它们能清晰的理解框架的内存管理策略。
三、数据流动带来的问题
一般情况下的数据流动循环
有这样一种场景:
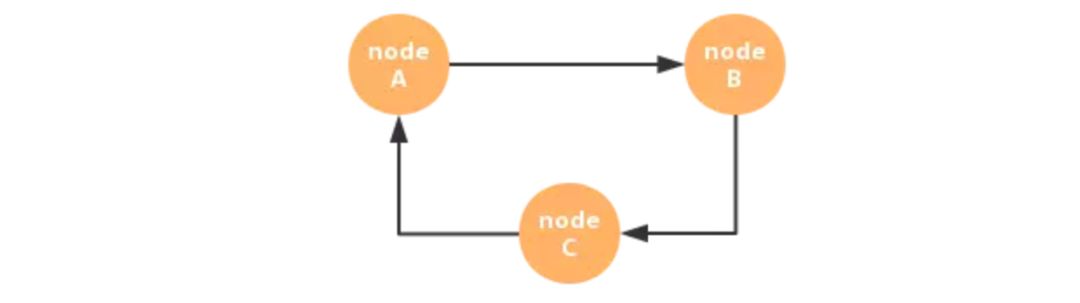
图中箭头的方向表示数据流动的方向,这就是比较典型的有向有环图,这种结构会带来两个问题:
形成引用环,无法自动释放内存。
数据流动会陷入无限循环。
第一个问题实际上很简单,如果业务中写了这种结构,只需要手动破除循环引用。把关注点放到第二问题上,数据流动无限循环将会栈溢出带来灾难性的后果,框架是如何避免的呢,官方文档只说了通过 EZRSenderList 来避免,下面看看源码中具体是如何实现的。
在 EZRMutableNode 节点中,数据传递必然会走的方法是:
- (void)next:(nullable id)value from:(EZRSenderList *)senderList context:(nullable id)context {
...
[self _next:value from:senderList context:context];
...
}
- (void)_next:(nullable id)value from:(EZRSenderList *)senderList context:(nullable id)context {
...
//赋值
_value = value;
...
//拼接当前节点
EZRSenderList *newQueue = [senderList appendNewSender:self];
//遍历监听边发送数据
for (... item in self.privateListenEdges) {
[item next:value from:newQueue context:context];
}
//遍历下游可变边发送数据
for (... item in self.privateDownstreamTransforms) {
if (![senderList contains:item.to]) {
[item next:value from:newQueue context:context];
}
}
...
}
省去并修改了很多代码变成了伪代码,这和源码是不一致的,便于查看逻辑。可以看到执行了两个 for 循环,self.privateListenEdges是监听边集合,self.privateDownstreamTransforms 是下游的可变边集合,它们的元素在构建图的时候已经准备好了,通过遍历这两个集合实现递归深搜将数据传递下去。
EZRSenderList 是一个链表,可以注意到 [senderList appendNewSender:self] 代码,将当前节点拼接进链表,这个链表的生命周期是一次数据流动过程。在遍历下游可变边的时候有一个判断:if (![senderList contains:item.to]) {},实际上这就是阻止无限循环的核心操作,即若数据流动链表中包含了当前节点,就截断,避免无限循环。
nodeA --> nodeB --> nodeC |senderList里面有nodeA,截断| --> nodeA
另外一种情况的数据流动循环
思考这样一种场景:
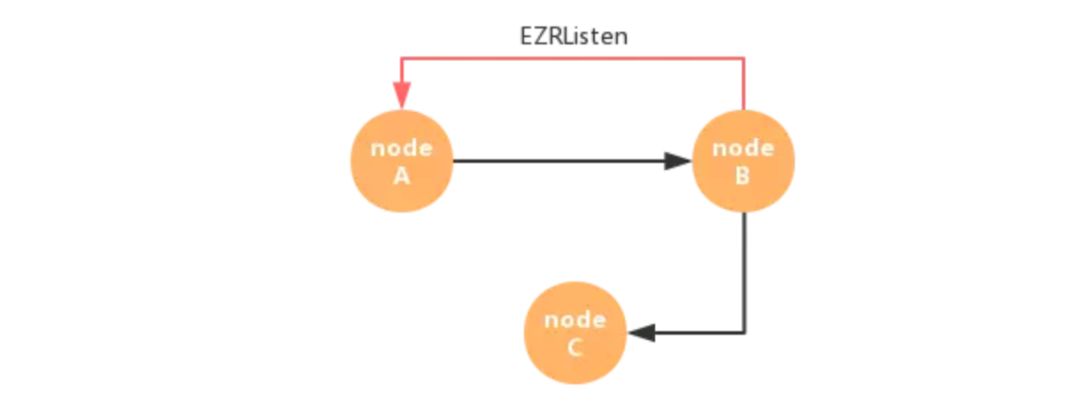
红色的边是监听边,黑色的边表示可变边,此处表示 nodeA 监听了 nodeB 的变化,当 nodeB 的值变化的时候,会遍历监听边发送数据,也就是会通知到 nodeA。
需要注意的是,节点只在遍历下游可变边时通过EZRSenderList截断循环,而在遍历监听边时未做处理,这是由于监听边不会让to对应的节点继续深搜传递数据,而是直接发送一个通知,所以每一个由业务工程师创建的监听都是有意义的。
若出现以下情况:
nodeA --> nodeB [nodeA监听到改变:nodeA --> nodeB] --> nodeC
也就是当nodeA监听到nodeB值变化值,又一次向nodeB发送数据nodeA --> nodeB,这样会导致无限入栈,直至栈溢出。监听回调的操作逻辑通常是业务工程师来写,在特定的业务场景下这种情况是可能出现的。
那么,如何来避免类似情况导致的栈溢出呢?
在EZRMutableNode.m中,先来看一个至关重要的类(EZTuple3是元祖,不用纠结其实现):
@interface EZRSettingQueue: NSObject
//是否是第一次使用该实例
@property (nonatomic, assign) BOOL firstSetting;
//队列
@property (nonatomic, strong) NSMutableArray<EZTuple3<id, EZRSenderList *, id> *> *queue;
//入队
- (void)enqueue:(EZTuple3<id, EZRSenderList *, id> *)tuple;
//出队
- (EZTuple3<id, EZRSenderList *, id> *)dequeue;
@end
从 API 看就一目了然,这个类的作用是封装了一个队列,然后有一个属性firstSetting来判断是否是第一次使用该实例,接下来看一个方法:
- (EZRSettingQueue *)currentSettingQueue {
EZRSettingQueue *settingQueue = [NSThread currentThread].threadDictionary[_settingQueueKey];
if (settingQueue == nil) {
settingQueue = [EZRSettingQueue new];
[NSThread currentThread].threadDictionary[_settingQueueKey] = settingQueue;
}
return settingQueue;
}
通过一个线程附带的 hash 容器,保存一个EZRSettingQueue对象,这个_settingQueueKey是当前节点唯一标识。然后接着看下一个方法:
- (void)checkSettingQueue {
EZRSettingQueue *settingQueue = self.currentSettingQueue;
if (settingQueue.queue.count) {
[self settingDequeue];
} else {
[NSThread currentThread].threadDictionary[_settingQueueKey] = nil;
}
}
这个方法判断了这个线程持有EZRSettingQueue队列是否为空,若为空将它从线程字典中剔除,否则执行下面方法:
- (void)settingDequeue {
EZTuple3<id, EZRSenderList *, id> *tuple = [self.currentSettingQueue dequeue];
[self _next:tuple.first from:tuple.second context:tuple.third];
}
取出队列中的元素,并且调用节点的数据传送方法-_next...,到这里其实就可以猜到EZRSettingQueue是用来存储数据流动相关数据的。那么,我们来看数据流动流程里面是如何调用这些方法的:
- (void)next:(nullable id)value from:(EZRSenderList *)senderList context:(nullable id)context {
EZRSettingQueue *settingQueue = self.currentSettingQueue;
if EZR_LikelyYES(settingQueue.firstSetting) {
settingQueue.firstSetting = NO;
[self _next:value from:senderList context:context];
} else {
[settingQueue enqueue:EZTuple(value, senderList, context)];
}
}
- (void)_next:(nullable id)value from:(EZRSenderList *)senderList context:(nullable id)context {
...lock {
_value = value;
}
...
//深搜发送数据
...
[self checkSettingQueue];
}
可以看到,在深搜发送数据完毕之后,会调用-checkSettingQueue方法。
情况一:深搜完成之前不会再次进入-next:...方法,那么-checkSettingQueue会将线程字典里面的队列清空,那么 if (settingQueue.firstSetting)这个判断将始终为true,这种情况下发现EZRSettingQueue并没有起到作用。
情况二:深搜的过程中,再次进入了当前节点的-next:...方法(方法不断重入导致栈溢出),这时if (settingQueue.firstSetting)判断就为false了,那么就会将发送数据必备的参数入队到EZRSettingQueue队列中。当深搜发送数据完成过后,调用-checkSettingQueue方法执行在队列中的任务。如此,通过避免同一个节点的-next:...重入来规避可能的栈溢出。当然,有可能数据流动会无限循环,但这属于业务工程师“指定”的逻辑。
值得注意的是,情况二的分析是建立在同一线程的。延迟执行队列EZRSettingQueue是放在线程字典中的,意味着-next:...方法只是对同一线程的重入做处理,而不同线程的重入不做处理(因为不同线程拥有不同的栈空间,不会相互影响)。而对于多线程情况,-_next:...方法中对_value = value就行了加锁操作,保证全局变量的安全,同时避免同一线程的重入也恰巧避免了重复获取锁导致的死锁。
这确实是一个非常巧妙且令人兴奋的技巧。
四、边的变换
EZRTransform有很多衍生类,每一个都对应一种变换。什么叫变换呢?也就是在数据传到EZRTransform的时候,EZRTransform对数据进行处理,然后再按照特定的逻辑继续发送。

EasyReact 自带有非常多的变换处理,比如map、filter、scan、merge等,可以到 GitHub 查看其使用,也可以直接查看源码,大多数的变换的实现都是很简单易懂的,笔者这里只列举并解析几个稍微比较复杂的实现(主要是通过结构图来解析,最好是对照源码理解)。
combine
响应式编程经常会使用 a := b + c 来举例,意图是当 b 或者 c 的值发生变化的时候,a 会保持两者的加和。那么在响应式库 EasyReact 中,我们是怎样体现的呢?就是通过 EZRCombine-mapEach 操作:
EZRMutableNode<NSNumber *> *nodeA = [EZRMutableNode value:@1];
EZRMutableNode<NSNumber *> *nodeB = [EZRMutableNode value:@2];
EZRNode<NSNumber *> *nodeC = [EZRCombine(nodeA, nodeB) mapEach:^NSNumber *(NSNumber *a, NSNumber *b) {
return @(a.integerValue + b.integerValue);
}];
nodeC.value; // <- 1 + 2 = 3
nodeA.value = @4;
nodeC.value; // <- 4 + 2 = 6
nodeB.value = @6;
nodeC.value; // <- 4 + 6 = 10
上面是官方的描述和例子,实际上 combine 操作就是nodeC的值始终等于nodeA + nodeB。
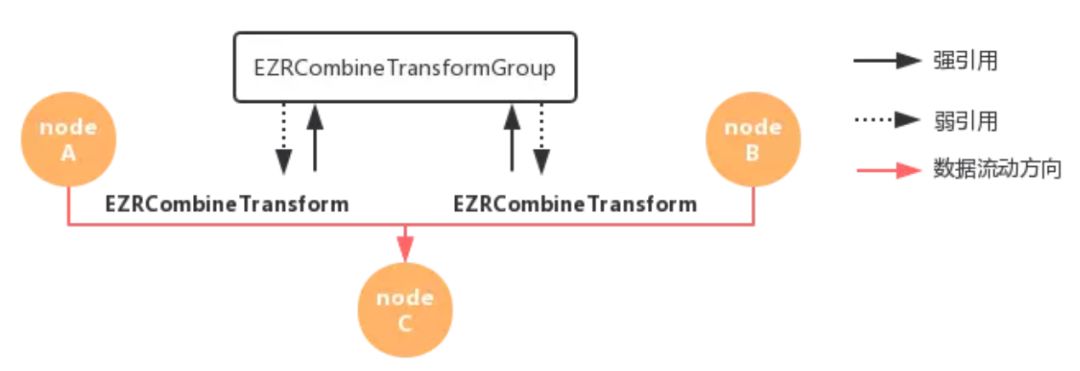
实现 combine 的边叫做EZRCombineTransform,同时有一个EZRCombineTransformGroup作为处理器,它持有了所有相关的边,当数据经过EZRCombineTransform时,交由处理器将所有边的值相加,然后继续发送。
zip
拉链操作是这样的一种操作:它将多个节点作为上游,所有的节点的第一个值放在一个元组里,所有的节点的第二个值放在一个元组里……以此类推,以这些元组作为值的就是下游。它就好像拉链一样一个扣着一个:
EZRMutableNode<NSNumber *> *nodeA = [EZRMutableNode value:@1];
EZRMutableNode<NSNumber *> *nodeB = [EZRMutableNode value:@2];
EZRNode<EZTuple2<NSNumber *, NSNumber *> *> *nodeC = [nodeA zip:nodeB];
[[nodeC listenedBy:self] withBlock:^(EZTuple2<NSNumber *, NSNumber *> *tuple) {
NSLog(@"接收到 %@", tuple);
}];
nodeA.value = @3;
nodeA.value = @4;
nodeB.value = @5;
nodeA.value = @6;
nodeB.value = @7;
/* 打印如下:
接收到 <EZTuple2: 0x60800002b140>(
first = 1;
second = 2;
last = 2;)
接收到 <EZTuple2: 0x60800002ac40>(
first = 3;
second = 5;
last = 5;
)
接收到 <EZTuple2: 0x600000231ee0>(
first = 4;
second = 7;
last = 7;
)
*/
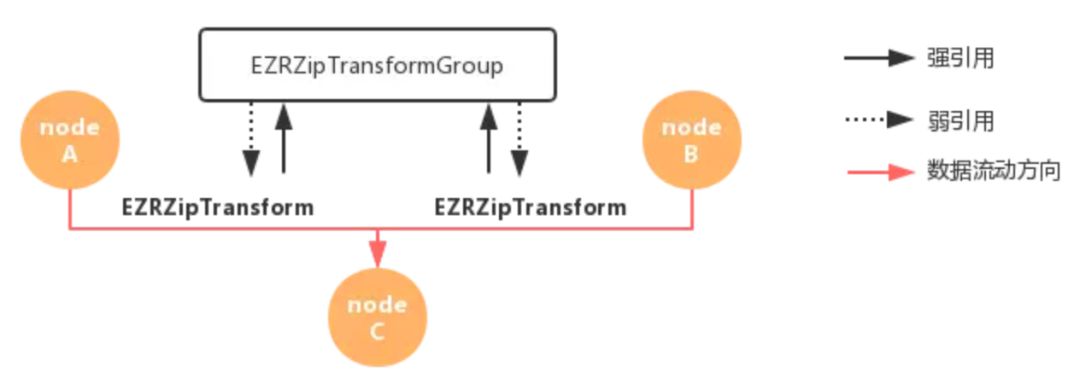
zip 的数据结构实现和 combine 如出一辙,不同的是,每一个EZRZipTransform都维护了一个新值的队列,当数据流动时,EZRZipTransformGroup会读取每一个边对应队列的顶部元素(同时出队),若某一个边的队列未读取到新值则停止数据传播。
switch
switch-case-default 变换是通过给出的 block 将每个上游的值代入,求出唯一标识符,再分离这些标识符的一种操作。我们举例一个分离剧本的例子:
EZRMutableNode<NSString *> *node = [EZRMutableNode new];
EZRNode<EZRSwitchedNodeTuple<NSString *> *> *nodes = [node switch:^id<NSCopying> _Nonnull(NSString * _Nullable next) {
NSArray<NSString *> *components = [next componentsSeparatedByString:@":"];
return components.count > 1 ? components.firstObject: nil;
}];
EZRNode<NSString *> *liLeiSaid = [nodes case:@"李雷"];
EZRNode<NSString *> *hanMeimeiSaid = [nodes case:@"韩梅梅"];
EZRNode<NSString *> *aside = [nodes default];
[[liLeiSaid listenedBy:self] withBlock:^(NSString *next) {
NSLog(@"李雷节点接到台词: %@", next);
}];
[[hanMeimeiSaid listenedBy:self] withBlock:^(NSString *next) {
NSLog(@"韩梅梅节点接到台词: %@", next);
}];
[[aside listenedBy:self] withBlock:^(NSString *next) {
NSLog(@"旁白节点接到台词: %@", next);
}];
node.value = @"在一个宁静的下午";
node.value = @"李雷:大家好,我叫李雷。";
node.value = @"韩梅梅:大家好,我叫韩梅梅。";
node.value = @"李雷:你好韩梅梅。";
node.value = @"韩梅梅:你好李雷。";
node.value = @"于是他们幸福的在一起了";/* 打印如下:
旁白节点接到台词: 在一个宁静的下午
李雷节点接到台词: 李雷:大家好,我叫李雷。
韩梅梅节点接到台词: 韩梅梅:大家好,我叫韩梅梅。
李雷节点接到台词: 李雷:你好韩梅梅。
韩梅梅节点接到台词: 韩梅梅:你好李雷。
旁白节点接到台词: 于是他们幸福的在一起了
*/
分支的实现几乎是最复杂的了,node首先通过EZRSwitchMapTransform边连接一个nodes下游节点,并且初始化一个分支划分规则 (block);然后nodes节点分别通过EZRCaseTransform边连接liLeiSaid、hanMeimeiSaid、aside下游节点,并且每一个下游节点存储了一个匹配分支的key(也就是例子中的“李雷”、“韩梅梅”等)。
当node发送数据过来时,由EZRSwitchMapTransform通过分支划分规则处理数据,然后将每一个分支节点通过 hash 容器装起来,也就是图中的蓝色节点case node,这个例子发送的数个消息最终会创建三个分支;在创建分支完成过后,EZRSwitchMapTransform向下游继续发送数据,在数据到达EZRCaseTransform时,该边会监听对应的case node(当然前提是匹配)而不会继续向下游发送数据;然后EZRSwitchMapTransform会继续改变对应case node的值,由此EZRCaseTransform就接收到了数据改变的通知,最终发送给下游节点,即这里的liLeiSaid、hanMeimeiSaid或aside。
笔者思考了一番,并没有找到必须使用case node节点的充分理由,可能是疏漏了某些细节,希望理解深刻的读者在文末留言。
五、代码细节及优化
在源码的阅读中,发现了几个有意思的代码技巧。
自动解锁
- (void)_next:(nullable id)value from:(EZRSenderList *)senderList context:(nullable id)context {
{
EZR_SCOPELOCK(_valueLock);
_value = value;
}
...
}
EZR_SCOPELOCK()宏的出场率相当高,直接查看实现:
#define EZR_SCOPELOCK(LOCK) /
EZR_LOCK(LOCK); /
EZR_LOCK_TYPE EZR_CONCAT(auto_lock_, __LINE__) /
__attribute__((cleanup(EZR_unlock), unused)) = LOCK
可以看到先是对传进来的锁进行加锁操作,后面关键的有句代码:
__attribute__((cleanup(AnyFUNC), unused))
这句代码加在局部变量后面,将会在局部变量作用域结束之前调用AnyFUNC方法。那么此处的目的很简单,看一眼这里的EZR_unlock干了什么:
static inline void EZR_unlock(EZR_LOCK_TYPE *lock) {
EZR_UNLOCK(*lock);
}
具体的宏可以看源码,此处只是做了一个解锁操作,由此就实现了自动解锁功能。这就是为什么要用大括号把加锁的代码包起来,可以理解为限定加锁的临界区。
虽然少写句代码的意义不大,但是却比较炫 以上是关于美团 EasyReact 源码剖析:图论与响应式编程的主要内容,如果未能解决你的问题,请参考以下文章