从Reactor到WebFlux
Posted 春哥叨叨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Reactor到WebFlux相关的知识,希望对你有一定的参考价值。
写在前面
为了应对高并发场景下到服务端编程需求,微软最先提出了一种异步编程到方案Reactive Programming,也就是反应式编程。
之后在Java社区就出现了RxJava和Akka Stream等技术方案,让Java平台在反应式编程上有了多种选择。
反应式编程
函数式编程
反应式编程一般是基于函数式编程实现的,函数式编程有如下特点:
惰性计算
函数是第一公民
只使用表达式而不是用语句
反应式编程是一种基于数据流,传递变化,声明式的编程范式。
事件驱动
思想是组件之间交互通过松耦合的生产者和消费者来实现的,并且事件以异步,非阻塞方式进行发送和接收。
事件驱动是系统通过推模式实现的,也就是生产者在消息产生时推送数据给消费者进行处理,而不是让消费者不断轮询或等待数据实现的。
响应及时
由于反应式是异步的,比如进行数据处理的话,在交出任务之后就快速返回,而不是阻塞的等待任务执行完毕再返回。任务的执行给到后台线程执行,等任务处理完成之后返回,比如Java8的CompletableFuture。
事件弹性
事件驱动系统是松耦合的,上下游之间不是直接依赖,但是在Debug时成本更高一些。
Spring Reactor
Spring Reactor是Pivotal基于反应式编程实现的一种方案。是一种非阻塞,事件驱动的编程方案,使用函数式编程实现。
观察者模式
反应式编程和命令式编程在迭代器上的实现:
事件 Iterable (pull) Observable (push)
获取数据 T next() onNext(T)
发现异常 throws Exception onError(Exception)
处理完成 hasNext() onCompleted()
Publisher推送数据给Subscriber,触发onNext()方法,在处理完成或发生异常时触发onCompleted()和onError()方法。
Publisher发生异常时,触发Subscriber的onError()方法,进行异常捕获处理。
Publisher每次推送都会触发一次onNext()方法,所有推送完成时,最后触发onCompleted()方法。
背压
如果Publisher发布消息太快,超过Subscriber处理速度该怎么办?响应式编程引入了背压概念,使得Subscriber能够控制消费消息的速度。
Reactive Stream
在Java生态中,Netflix的RxJava,TypeSafe的Scala,Akaka,pivatol的Sping,Reactor都是反应式编程的框架。
Stream不是集合元素,不是数据结构,也不保存数据,只是关于算法和计算,更像一种可以编程的迭代器。
Stream可以并行操作,迭代器只能命令式的,串型操作。并行操作是将数据分成多段,每一个在不同线程中处理,最后将结果一起输出。这样可以大大利用硬件资源。
Reactor主要模块基于Netty实现:
reactor-core:包含核心API
reactor-ipc:复杂高性能网络通信
核心类:
Mono:代表0到1个元素发布者
Flux:代表0到N个元素发布者
Scheduler:代表事件驱动的反应流调度器,通常由各种线程池实现。
反应式编程概念总结:
ReactiveStreams 是一套反应式编程 标准 和 规范;
Reactor 是基于 ReactiveStreams 一套 反应式编程框架;
WebFlux 以 Reactor 为基础,实现 Web 领域的 反应式编程框架。
Reactor开发
Reactor使用方式上基本分为三步:
开始阶段创建
中间阶段处理
最终阶段消费
创建阶段

Reactor编程需要先创建出Mono或Flux。
同步调用结果创建对象
Mono<String> helloWorld = Mono.just("Hello World"); // 可以指定序列中包含的全部元素
Flux<String> fewWords = Flux.just("Hello","World");
Flux<String> manyWords = Flux.fromIterable(words);
这种方式一般用在经过一系列非IO型操作后,得到一个对应的对象,当需要将这个对象交给IO操作时,可以通过这种方式转换成Mono或Flux。
异步调用结果创建
如果异步得到结果,比如CompletableFuture可以创建一个Mono:
Mono.fromFuture(completableFuture);
如果这个异步调用不返回CompletableFuture,而有自己的回调方法,那么可以使用:
static<T>Mono<T>create(Consumer<MonoSink<T>>callback)
Mono.create(sink ->{
ListenableFuture<ResponseEntity<String>> entity = asyncRestTemplate.getForEntity(url,String.class);
entity.addCallback(new ListenableFutureCallback<ResponseEntity<String>>(){
@Override
public void onSuccess(ResponseEntity<String> result){
sink.success(result.getBody());
}
@Override
public void onFailure(Throwable ex)
{
sink.error(ex);
}
});
});
处理阶段
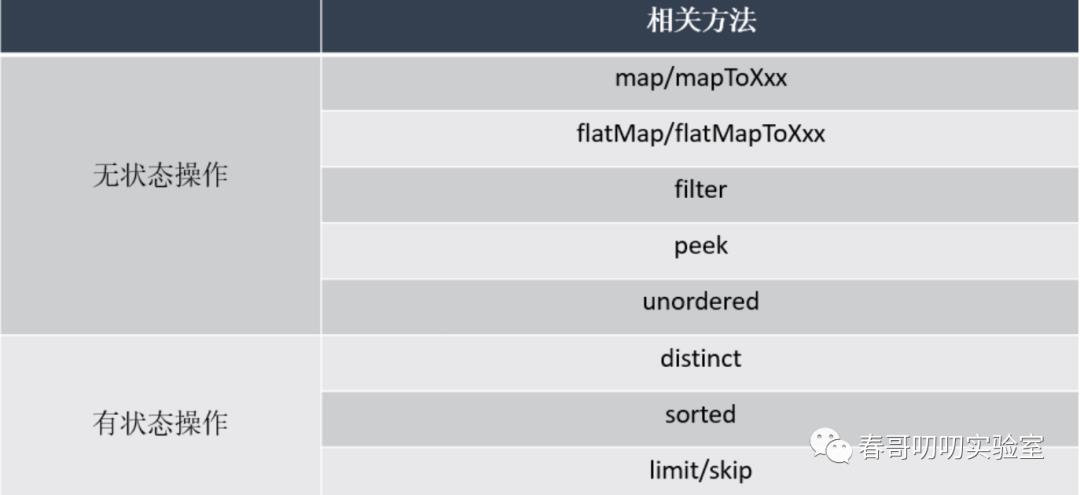
在进行Mono和Flux处理阶段,一般使用filter,map,flatMap,then,zip,reduce等。
map,flatMap,then 三个频率使用比较高。
数据处理方式
then
是下一步意思,代表执行顺序的下一步,不表示下一步依赖于上一步。then方法参数只是一个Mono,入参不是上一步的执行结果。
flatMap和map的参数是Function,是上一步执行的结果。
flatMap和map
传统的命令式编程
Object result1 = doStep1(params);
Object result2 = doStep2(result1);
Object result3 = doStep3(result2);
对应的反应式编程
Mono.just(params) .flatMap(v -> doStep1(v)) .flatMap(v -> doStep2(v)) .flatMap(v -> doStep3(v));
flatMap入参Function的返回值要求是Mono对象。map的入参Function只要求返回一个普通对象。对于一些返回值是Mono的方法,想将调用串联起链式调用,必须使用flatMap,而不是map。
并发处理方式
一般使用Mono.zip,Tuple2等。
传统编程方式并发执行是通过线程池+Future方式实现的。但是在做Future.get时是阻塞的。Reactor中使用Mono和Flux中的zip方法如下:
Mono<CustomType1> item1Mono = ...;
Mono<CustomType2> item2Mono = ...;
Mono.zip(items -> {
CustomType1 item1 = CustomType1.class.cast(items[0]);
CustomType2 item2 = CustomType2.class.cast(items[1]);
// Do merge
return mergeResult;
}, item1Mono, item2Mono);
这样item1Mono 和 item2Mono 过程是并行执行的。
使用zip方法时需要做类型强转换,类型强转换是不安全的
数据循环处理
一般使用:Flux.fromIterable(),Flux.reduce()方法。
比如:
Data initData = ...;
List<SubData> list = ...;
Flux.fromIterable(list)
.reduce(initData,(data,itemInList) -> {
// Do something on data and itemInList
return data;
});
结束阶段
直接消费的Mono和Flux就是调用subscriber方法,其他的WebFlux接口可以直接返回框架的Response输出就可以了。
WebFlux
Serverlet3.1支持了异步处理方式,Servlet线程不需要一直阻塞的等待任务执行。Servlet在接收到请求后,将请求委托给业务线程完成,自己则直接返回继续接收新的请求。
所以Servlet3.1适用于那些业务处理非常耗时场景,这样可以减少服务器资源占用,可以提高并发处理速度,但是对于本身响应较为迅速的应用来说收益不大。
WebFlux的异步处理是基于Reactor实现的,是将输入流适配成Mono或Flux进行统一处理。
在最新的Spring Cloud Gateway中也是基于Netty和WebFlux实现的。
Flux和Mono
Flux和Mono属于事件发布者,类似于生产者,为消费者提供订阅接口。在实现发生时,Flux和Mono会回调消费者对应的方法通知消费者处理事件。Flux可以触发多个事件,Mono只触发一个事件。
Flux.fromIterable(getSomeLongList())
.mergeWith(Flux.interval(100))
.doOnNext(serviceA::someObserver)
.map(d -> d * 2)
.take(3)
.onErrorResumeWith(errorHandler::fallback)
.doAfterTerminate(serviceM::incrementTerminate)
.subscribe(System.out::println
);
Mono.fromCallable(System::currentTimeMillis)
.flatMap(time -> Mono.first(serviceA.findRecent(time), serviceB.findRecent(time)))
.timeout(Duration.ofSeconds(3), errorHandler::fallback)
.doOnSuccess(r -> serviceM.incrementSuccess())
.subscribe(System.out::println);
选型注意
如果在框架中使用了WebFlux,他依赖的安全认证,数据访问都必须使用Reactive API,在存储层目前Reactive只支持MongoDB,Redis和Couchbase等几种不支持事务管理的NoSql,需要注意。
WebFlux并不能将接口耗时减少,只是可以减少线程扩展,提升系统的吞吐和伸缩能力。由于其为异步非阻塞Web框架,所以适用于IO密集型服务,比如我们交易网关这种。
WebFlux支持两种编程模式:
基于注解@Controller和其他的类Spring MVC的注解
函数式,Java8 lambda风格的路由处理
可以通过Reactive Streams实现背压控制。
ServerRequest和ServerResponse是JDK8友好访问底层HTTP消息的不可变接口。完全是响应式的。
实践建议
在使用lambda写处理函数时,如果多个处理函数可能缺乏可读性且不易于维护。可以将相关处理函数分组到一个处理程序或控制器类中。
以上是关于从Reactor到WebFlux的主要内容,如果未能解决你的问题,请参考以下文章