React 单元测试策略及落地
Posted ThoughtWorks洞见
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了React 单元测试策略及落地相关的知识,希望对你有一定的参考价值。
单元测试是现代软件开发最基本,也普遍落地不力的实践。市面关于React单元测试的文章,普遍停留在“可以如何写”和介绍工具的层面,既未回答“为何必须做单元测试”,也未回答“单元测试的最佳实践”两个关键问题。本文正是要对这两个问题作出回答。
本文所用技术栈为前端React栈,测试框架与断言工具是jest。文章将略过对测试框架本身的语法介绍,着眼于“为何做”与“最佳实践”的部分。阅读第二部分的代码,需要读者对javascript与React语法有一定了解,但第一部分的原理并不对读者做任何语言上的假设。
目录
第一部分:为什么必须做单元测试
单元测试的上下文
测试策略——测试金字塔
TDD——单元测试的核心灵魂
第二部分:什么是好的单元测试
第三部分:React 单元测试策略
第四部分:React 单元测试落地
action 测试
reducer 测试
selector 测试
saga 测试
来自官方的错误姿势
正确姿势
component 测试
业务型组件-分支渲染
业务型组件-事件调用
功能型组件-
children型高阶组件util 测试
总结
未尽话题
参考
第一部分:为什么必须做单元测试
对于单元测试有保障质量之利益一事,业界已多有共识,但谈及其实施,则有种种“浪费时间”“很难写”“作用不大”顾及成本之声,他们板起一副编写单元测试将付出巨大成本的严肃脸。在“单元测试能保障质量”已成政治正确的今日,又有一种中庸的声音,说“单元测试固然有用,但也要根据项目情况进行裁剪,要写对开发者真正有用的测试”,一副放之四海皆准的样子,于是终于能够安心地根据项目情况将单元测试裁剪掉。
这种态度我一贯旗帜鲜明地反对:上来就谈裁剪,不是正确的导向。与产品代码一并交付高质量的测试代码,是每个开发者日常交付软件的基本职责。
单元测试的上下文
“为什么我们需要做单元测试”,这是一个关键的问题。往小了说,不做单元测试的代码无法保证后续不被破坏,无法重构,只能看着代码腐化;往大了说,不做单元测试的团队响应力不可能提高。
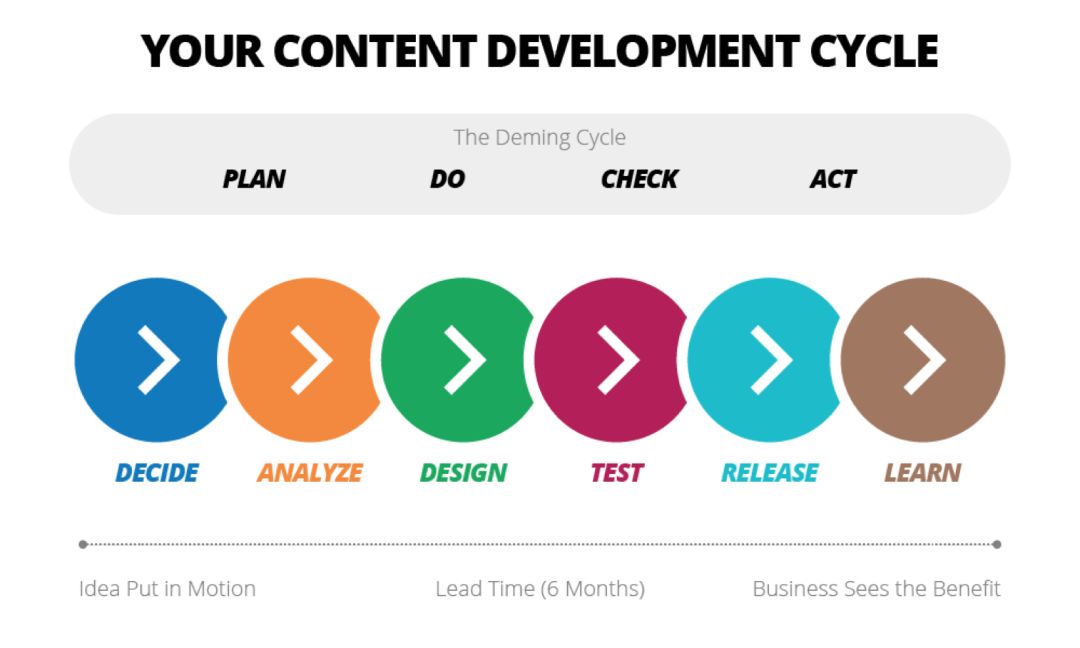
实际上,自动化测试是实现“敏捷”的基本保障。,业务端快速上线、快速验证、快速失败的思路对技术端的响应力提出了更高的要求:更快上线、持续上线。怎么样衡量这个“更快”呢?第一图给出了一个指标:lead time。它度量的是一个想法从提出并被验证,到最终上生产环境面对用户获取反馈的时间。显然,这个时间越短,软件就能越快获得反馈,对价值的验证就越快发生,软件对反馈的响应能力就越强。这个结论对我们写不写单元测试有什么影响呢?答案是,不写单元测试、不写好的单元测试,你就快不起来。为啥呢?因为每次发布,你都要投入人力来进行手工测试;因为没有自动化测试,你倾向于不敢随意重构,这又导致代码逐渐腐化,复杂度使得你的开发速度降低。
再考虑到以下两大事实:人员会流动,应用会变大。人员一定会流动,需求一定会增加,直至再也没有一个人能够了解应用的所有功能,那时对应用做出修改的成本将变得很高。因此,意图依赖人、依赖手工的方式来应对响应力的挑战首先是低效的,从时间维度上来讲也是不可能的。因此,为了服务于“高响应力”这个目标,随时重构整理代码是必须的,这就需要我们有一套自动化的测试套件,它能帮我们提供快速反馈,做质量的守卫者。唯解决了人工、质量的这一环,开发效率才能稳步提升,团队和企业的高响应力才可能达到。
在“响应力”和“随时重构”这个上下文中来谈要不要单元测试,我们就可以很有根据了,而不是含糊不清地回答“看项目的具体情况”了。显然,写出易于理解、易于修改、可以重构的代码,是每个开发者的本来职责,而单元测试正是达成此一目的的唯一途径。
测试策略——测试金字塔
上面我直接从高响应力谈到单元测试,可能有的同学会问,高响应力这个事情我认可,也认可快速开发的同时,质量也很重要。但是,为了达到“保障质量”的目的,不一定得通过测试呀,就算需要测试,也不一定得通过单元测试鸭。
这是个好的问题。为了达到保障质量这个目标,测试当然只是其中一个方式,稳定的自动化部署、集成流水线、良好的代码架构、甚至于团队架构的必要调整等,都是必须跟上的设施。自动化测试不是解决质量问题的银弹,多方共同提升才可能起到效果。
即便我们谈自动化测试,也未必全部都是单元测试。我们对自动化测试套件寄予的厚望是,它能帮我们安全重构已有代码、快速回归已有功能、保存业务上下文。测试种类多种多样,为什么我要重点谈单元测试呢?因为它写起来相对最容易、运行速度最快、反馈效果又最直接。下面这个图,想必大家都有所耳闻:
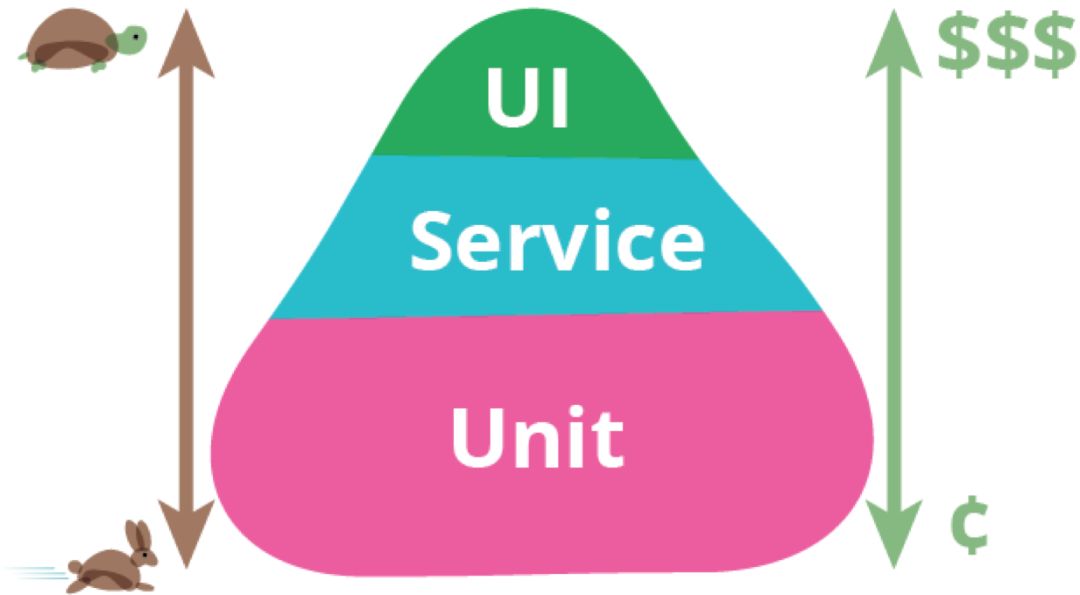
这就是有名的测试金字塔。对于一个自动化测试套件,应该包含种类不同、关注点不同的测试,比如关注单元的单元测试、关注集成和契约的集成测试和契约测试、关注业务验收点的端到端测试等。正常来说,我们会受到资源的限制,无法应用所有层级的测试,效果也未必最佳。因此,我们需要有策略性地根据收益-成本的原则,考虑项目的实际情况和痛点来定制测试策略:比如三方依赖多的项目可以多写些契约测试,业务场景多、复杂或经常回归的场景可以多写些端到端测试,等。但不论如何,整个测试金字塔体系中,你还是应该拥有更多低层次的单元测试,因为它们成本相对最低,运行速度最快(通常是毫秒级别),而对单元的保护价值相对更大。
TDD——单元测试的核心灵魂
以上回答了“为何要有单元测试”的问题,却没有回答“如何得到这些单元测试”。有同学可能问,你说要写单元测试,那么什么时候写这些单元测试呢?让谁来写呢(开发人员还是测试人员)?代码实现那么烂,我根本写不出强壮的测试,怎么办呢?
回答是,这些单元测试应该由开发者,在开发软件的同时编写对应的单元测试。它应该是内建的,而不是后补的:也即在编写实现的同时完成单元测试,而不是写完代码再一次性补足。测试先行,这正是TDD的做法。使用TDD开发方法是得到可靠单元测试的唯一途径。
长久以来,大家都认为单测是单测,TDD是TDD,说单测必须要有,但是否使用TDD(测试先行)应该尊重开发者的习惯爱好。但事实是,且不说测试很难补,补出来的测试也几乎不可能完整覆盖我们对重构和质量的要求。TDD和单元测试是全有或全无:不做TDD,难以得到好的单元测试;TDD是获得可靠的单元测试的的唯一途径。除此之外别无捷径,想抛开TDD而获得一个好的单元测试套件是迷思,难以成功。

第二部分:什么是好的单元测试
好,相信看到这里,你已经愿意为一套好的单元测试集而奋斗了。下一个摆在我们眼前的问题就是,“什么才是好的单元测试”,以及“如何写出这样的单元测试”了。开始之前,我们先来看个例子,即一个最简单的JavaScript单元测试长什么样:
// production code
const computeTotalAmount = (products) => {
return products.reduce((total, product) => total + product.price, 0);
}
// testing code
it('should return summed up total amount 1000 when there are three products priced 200, 300, 500', () => {
// given - 准备数据
const products = [
{ name: 'nike', price: 200 },
{ name: 'adidas', price: 300 },
{ name: 'lining', price: 500 },
]
// when - 调用被测函数
const result = computeTotalAmount(products)
// then - 断言结果
expect(result).toBe(1000)
})
这个例子虽小,五脏却基本齐全。遵循这个given-when-then的结构,可以让你写出比较清晰的测试结构,既易于阅读,也易于编写。此外,编写容易维护的单元测试还有一些原则,这些原则对于任何语言、任何层级的测试都适用。这些原则不是新东西,但总是需要时时温故知新,笔者总结于此,可以此为镜,时时检验你的单元测试套件是否高效:
只关注输入输出,不关注内部实现
只测一条分支
表达力极强
不包含逻辑
运行速度快
只关注输入输出,不关注内部实现
比如上面那个例子,你是如何完成“求总价格”的,测试本身不关注,因此你可以用reduce实现,也可以自己写for循环实现。只要测试输入没有变,输出就不应该变。这个特性,是测试支撑重构的基础。因为重构指的是,在不改变软件外部可观测行为的基础上,调整软件内部的实现。由此也可以看出,如果你是后补的测试,加之实现本身就写得细节横陈,就很难补出这种能够支撑重构、结构又清晰的测试代码。测试先行本身就会驱动你写出易于测试的代码。
另外,还有一些测试(比如下文要看到的 saga 官方推荐的测试),它需要测试实现代码的执行次序。这也是一种“关注内部实现”的测试,这就使得除了输入输出外,还有“执行次序”这个因素可能使测试挂掉。显然,这样的测试也不利于重构的开展。
此外,对外部依赖采取mock策略,同样是某种程度上的“关注内部实现”,因为mock的失败同样将导致测试的失败,而非真正业务场景的失败。对待mock的态度,我认为是谨慎使用,但本文未做展开。肖鹏有篇文章Mock的七宗罪对此展开了详细描述,我还没细看,这里只能先分享给读者。
只测一条分支
通常来说,一条分支就是一个业务场景,是你做任务分解过程的一个细粒度的task。为什么测试只测一条分支呢?很显然,如此你才能给它一个好的描述,这个测试才能保护这个特定的业务场景,挂了的时候能给你细致到输入输出级别的业务反馈。
常见的反模式是,实现本身就做了太多的事情,不符合SRP原则。
表达力极强
表达力强的测试,能在失败的时候给你非常迅速的反馈。它讲的是两方面:
看到测试时,你就知道它测的业务点是啥
测试挂掉时,能清楚地知道失败的业务场景、期望数据与实际输出的差异
总结起来,这些表达力主要体现在以下的方面:
测试描述。遵循上一条原则(一个单元测试只测一个分支)的情况下,描述通常能写出一个相当详细的业务场景。这为测试的读者提供了极佳的业务上下文
测试数据准备。无关的测试数据(比如对象中的很多无关字段)不应该写出来,应只准备能体现测试业务的最小数据
输出报告。选用断言工具时,应注意除了要提供测试结果,还要能准确提供“期望值”与“实际值”的差异
上述第三点有些反例,比如说chai和sinon提供的断言API就不如jest友好,体现在:
expect(array).to.eql(array)出错的时候,只能报告说expect [Array (42)] to equal [Array (42)],具体是哪个数据不匹配,根本没报告expect(sinonStub.calledWith(args)).to.be.true出错的时候,会报告说expect false to be true。废话,我还不知道挂了么,但是那个stub究竟被什么参数调用则没有报告
这些细节,在阅读本文后面的任意测试,以及您自己编写单元测试的时候应该时常对照和雕琢。
不包含逻辑
跟写声明式的代码一样的道理,测试需要都是简单的声明:准备数据、调用函数、断言,让人一眼就明白这个测试在测什么。如果含有逻辑,你读的时候就要多花时间理解;一旦测试挂掉,你咋知道是实现挂了还是测试本身就挂了呢?
运行速度快
单元测试只有在毫秒级别内完成,开发者才会愿意频繁地运行它,将其作为快速反馈的手段也才能成立。那么为了使单元测试更快,我们需要:
尽可能地避免依赖。除了恰当设计好对象,关于避免依赖我已知有两种不同的看法:
使用mock适当隔离掉三方的依赖(如数据库、网络、文件等)
避免mock,换用更快速的数据库、启动轻量级服务器、重点测试文件内容等来迂回
将依赖、集成等耗时、依赖三方返回的地方放到更高层级的测试中,有策略性地去做
在如何避免依赖的问题上,截止我下笔此文章时仍在采用第一种方案,如何才能“适当”隔离掉三方依赖也难以在此详细表述,好在并不影响本文行文;近期可能会考察下第二种方法。
在后面的介绍中,我会将这些原则落实到我们写的每个单元测试中去。大家可以时时翻到这个章节来对照,是不是遵循了我们说的这几点原则,不遵循是不是确实会带来问题。时时勤拂拭,莫使惹尘埃啊。
第三部分:React 单元测试策略
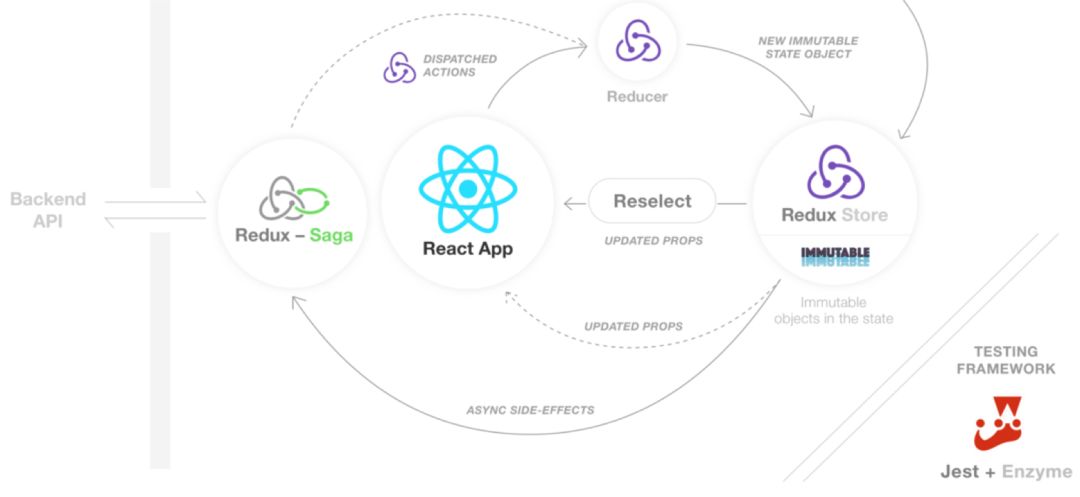
上个项目上的 React(-Native) 应用架构如上所述。它涉及一个常见 React 应用的几个层面:组件、数据管理、redux、副作用管理等,是一个常见的 React、Redux 应用架构,对于不同的项目应该有一定的适应性。架构中的不同元素有不同的特点,因此即便是单元测试,我们也有针对性的测试策略:
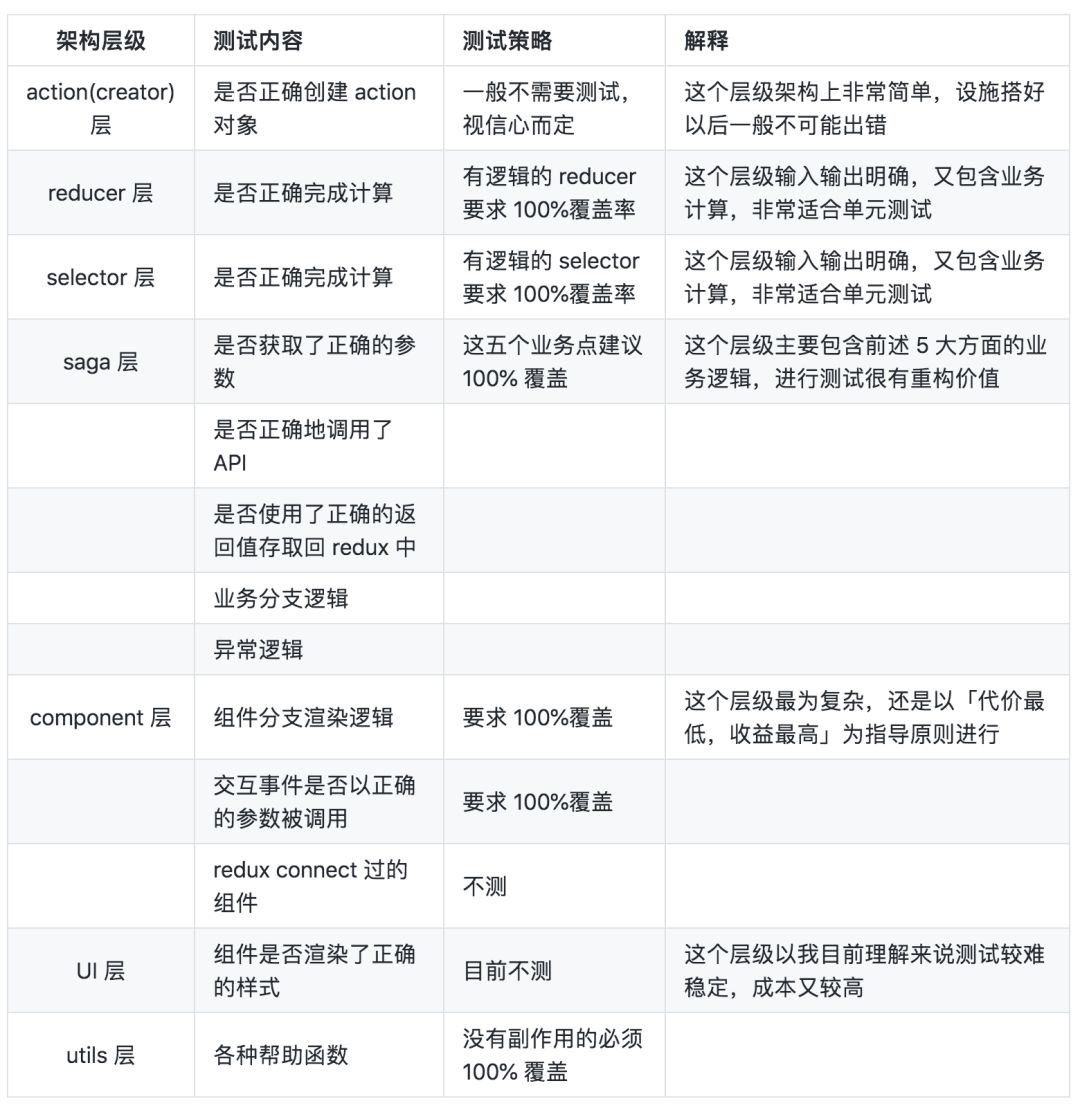
对于这个策略,这里做一些其他补充:
关于不测 redux connect 过的组件策略:理由是成本高于收益,得不偿失:
要配置依赖(配置 store、
<Provider />;如果是补测试还可能遇到@connect组件里套@connect组件的场景);牺牲了开发体验,搞起来没那么快了;
收益只是可能覆盖到了几个偶尔出现的场景(比如接入错误的字段、写字段时写错等);
关于 UI 测试策略:团队之前尝试过 snapshot 测试,对它寄予希望,主要理由是成本低,看起来又像万能药。实质上其整个机制的工作基础依赖于开发者在每次运行测试时耐心做好“确认比对”这个事情,这会打断日常的开发节奏(特别是依赖于TDD的红绿循环进行快速反馈的项目);其次还有些小的问题,比如其难以提供精确的快照比对,而只是代码层面的近似快照。我个人目前对此种测试类型持保留态度。
第四部分:React 单元测试落地
actions 测试
这一层获益于架构的简单性,甚至都可以不用测试。当然,如果有些经常出错的action,可以针对性地对这些action creator补充测试。其测试方法如下:
export const saveUserComments = (comments) => ({
type: 'saveUserComments',
payload: {
comments,
},
})
import * as actions from './actions'
test('should dispatch saveUserComments action with fetched user comments', () => {
const comments = []
const expected = {
type: 'saveUserComments',
payload: {
comments: [],
},
}
const result = actions.saveUserComments(comments)
expect(result).toEqual(expected)
})
reducer 测试
reducer 大概有两种:一种比较简单,仅一一保存对应的数据切片;一种复杂一些,里面具有一些计算逻辑。对于第一种 reducer,写起来非常简单,简单到甚至可以不需要用测试去覆盖,其正确性基本由简单的架构和逻辑去保证。下面是对一个简单 reducer 做测试的例子:
import Immutable from 'seamless-immutable'
const initialState = Immutable.from({
isLoadingProducts: false,
})
export default createReducer((on) => {
on(actions.isLoadingProducts, (state, action) => {
return state.merge({
isLoadingProducts: action.payload.isLoadingProducts,
})
})
}, initialState)
import reducers from './reducers'
import actions from './actions'
test('should save loading start indicator when action isLoadingProducts is dispatched given isLoadingProducts is true', () => {
const state = { isLoadingProducts: false }
const expected = { isLoadingProducts: true }
const result = reducers(state, actions.isLoadingProducts(true))
expect(result).toEqual(expected)
})
下面是一个较为复杂、更具备测试价值的 reducer 例子,它在保存数据的同时,还进行了合并、去重的操作:
import uniqBy from 'lodash/uniqBy'
export default createReducers((on) => {
on(actions.saveUserComments, (state, action) => {
return state.merge({
comments: uniqBy(
state.comments.concat(action.payload.comments),
'id',
),
})
})
})
import reducers from './reducers'
import actions from './actions'
test(`
should merge user comments and remove duplicated comments by comment id
when action saveUserComments is dispatched with new fetched comments
`, () => {
const state = {
comments: [{ id: 1, content: 'comments-1' }],
}
const comments = [
{ id: 1, content: 'comments-1' },
{ id: 2, content: 'comments-2' },
]
const expected = {
comments: [
{ id: 1, content: 'comments-1' },
{ id: 2, content: 'comments-2' },
],
}
const result = reducers(state, actions.saveUserComments(comments))
expect(result).toEqual(expected)
})
reducer 作为纯函数,非常适合做单元测试,加之一般在 reducer 中做重逻辑处理,此处做单元测试保护的价值很大。请留意,上面所说的单元测试,是不是符合我们描述的单元测试基本原则:
只关注输入输出,不关注内部实现:在输入不变时,仅可能因为“合并去重”的业务操作不符预期时才会挂测试
表达力极强:测试描述已经写得清楚“当使用新获取到的留言数据分发 action
saveUserComments时,应该与已有留言合并并去除重复的部分”;此外,测试数据只准备了足够体现“合并”这个操作的两条 id 的数据,而没有放很多的数据,形成杂音;不包含逻辑:测试代码不包含准备数据、调用、断言外的任何逻辑
运行速度快:没有任何依赖
selector 测试
selector 同样是重逻辑的地方,可以认为是 reducer 到组件的延伸。它也是一个纯函数,测起来与 reducer 一样方便、价值不菲,也是应该重点照顾的部分。况且,稍微大型一点的项目,应该说必然会用到 selector。原因我讲在这里(http://t.cn/Ai0SFInI)。下面看一个 selector 的测试用例:
import { createSelector } from 'reselect'
// for performant access/filtering in React component
export const labelArrayToObjectSelector = createSelector(
[(store, ownProps) => store.products[ownProps.id].labels],
(labels) => {
return labels.reduce(
(result, { code, active }) => ({
...result,
[code]: active,
}),
{}
)
}
)
import { labelArrayToObjectSelector } from './selector'
test('should transform label array to object', () => {
const store = {
products: {
10085: {
labels: [
{ code: 'canvas', name: '帆布鞋', active: false },
{ code: 'casual', name: '休闲鞋', active: false },
{ code: 'oxford', name: '牛津鞋', active: false },
{ code: 'bullock', name: '布洛克', active: true },
{ code: 'ankle', name: '高帮鞋', active: true },
],
},
},
}
const expectedActiveness = {
canvas: false,
casual: false,
oxford: false,
bullock: true,
ankle: false,
}
const productLabels = labelArrayToObjectSelector(store, { id: 10085 })
expect(productLabels).toEqual(expectedActiveness)
})
saga 测试
saga 是负责调用 API、处理副作用的一层。在实际的项目上副作用还有其他的中间层进行处理,比如 redux-thunk、redux-promise 等,本质是一样的,只不过 saga 在测试性上要好一些。这一层副作用怎么测试呢?首先为了保证单元测试的速度和稳定性,像 API 调用这种不确定性的依赖我们一定是要 mock 掉的。经过仔细总结,我认为这一层主要的测试内容有五点:
是否使用正确的参数(通常是从 action payload 或 redux 中来),调用了正确的 API
对于 mock 的 API 返回,是否保存了正确的数据(通常是通过 action 保存到 redux 中去)
主要的业务逻辑(比如仅当用户满足某些权限时才调用 API 等分支逻辑)
异常逻辑(比如找不到用户等异常逻辑)
其他副作用是否发生(比如有时有需要 Emit 的事件、需要保存到 IndexDB 中去的数据等)
来自官方的错误姿势
redux-saga 官方提供了一个 util: CloneableGenerator用以帮我们写 saga 的测试。这是我们项目使用的第一种测法,大概会写出来的测试如下:
import chunk from 'lodash/chunk'
export function* onEnterProductDetailPage(action) {
yield put(actions.notImportantAction1('loading-stuff'))
yield put(actions.notImportantAction2('analytics-stuff'))
yield put(actions.notImportantAction3('http-stuff'))
yield put(actions.notImportantAction4('other-stuff'))
const recommendations = yield call(Api.get, 'products/recommended')
const MAX_RECOMMENDATIONS = 3
const [products = []] = chunk(recommendations, MAX_RECOMMENDATIONS)
yield put(actions.importantActionToSaveRecommendedProducts(products))
const { payload: { userId } } = action
const { vipList } = yield select((store) => store.credentails)
if (!vipList.includes(userId)) {
yield put(actions.importantActionToFetchAds())
}
}
import { put, call } from 'saga-effects'
import { cloneableGenerator } from 'redux-saga/utils'
import { Api } from 'src/utils/axios'
import { onEnterProductDetailPage } from './saga'
const product = (productId) => ({ productId })
test(`
should only save the three recommended products and show ads
when user enters the product detail page
given the user is not a VIP
`, () => {
const action = { payload: { userId: 233 } }
const credentials = { vipList: [2333] }
const recommendedProducts = [product(1), product(2), product(3), product(4)]
const firstThreeRecommendations = [product(1), product(2), product(3)]
const generator = cloneableGenerator(onEnterProductDetailPage)(action)
expect(generator.next().value).toEqual(
actions.notImportantAction1('loading-stuff')
)
expect(generator.next().value).toEqual(
actions.notImportantAction2('analytics-stuff')
)
expect(generator.next().value).toEqual(
actions.notImportantAction3('http-stuff')
)
expect(generator.next().value).toEqual(
actions.notImportantAction4('other-stuff')
)
expect(generator.next().value).toEqual(call(Api.get, 'products/recommended'))
expect(generator.next(recommendedProducts).value).toEqual(
firstThreeRecommendations
)
generator.next()
expect(generator.next(credentials).value).toEqual(
put(actions.importantActionToFetchAds())
)
})
这个方案写多了,大家开始感受到了痛点,明显违背我们前面提到的一些原则:
测试分明就是把实现抄了一遍。这违反上述所说“不关注内部实现”的原则:action的分发顺序也是一种内部实现,改变实现次序也将使测试挂掉
当在实现中某个部分加入新的语句时,该语句后续所有的测试都会挂掉,并且出错信息非常难以描述原因,导致常常要陷入“调试测试”的境地,这也是依赖于实现次序带来的恶果,根本无法支持重构这种改变内部实现但不改变业务行为的代码清理行为
为了测试两个重要的业务“只保存获取回来的前三个推荐产品”、“对非 VIP 用户推送广告”,不得不在前面先按次序断言许多个不重要的实现
测试没有重点,随便改点什么都会挂测试
正确姿势
针对以上痛点,我们认为真正能够保障质量、重构和开发者体验的 saga 测试应该是这样:
不依赖实现次序;
允许仅对真正关心的、有价值的业务进行测试;
支持不改动业务行为的重构;
于是,我们发现官方提供了这么一个跑测试的工具,刚好可以用来完美满足我们的需求:runSaga。我们可以用它将 saga 全部执行一遍,搜集所有发布出去的 action,由开发者自由断言其感兴趣的 action!基于这个发现,我们推出了我们的第二版 saga 测试方案:runSaga + 自定义拓展 jest 的 expect 断言。最终,使用这个工具写出来的 saga 测试,几近完美:
import { put, call } from 'saga-effects'
import { Api } from 'src/utils/axios'
import { testSaga } from '../../../testing-utils'
import { onEnterProductDetailPage } from './saga'
const product = (productId) => ({ productId })
test(`
should only save the three recommended products and show ads
when user enters the product detail page
given the user is not a VIP
`, async () => {
const action = { payload: { userId: 233 } }
const store = { credentials: { vipList: [2333] } }
const recommendedProducts = [product(1), product(2), product(3), product(4)]
const firstThreeRecommendations = [product(1), product(2), product(3)]
Api.get = jest.fn().mockImplementations(() => recommendedProducts)
await testSaga(onEnterProductDetailPage, action, store)
expect(Api.get).toHaveBeenCalledWith('products/recommended')
expect(
actions.importantActionToSaveRecommendedProducts
).toHaveBeenDispatchedWith(firstThreeRecommendations)
expect(actions.importantActionToFetchAds).toHaveBeenDispatched()
})
这个测试已经简短了许多,没有了无关断言的杂音,依然遵循 given-when-then 的结构,并且同样是测试“只保存获取回来的前三个推荐产品”、“对非 VIP 用户推送广告”两个关心的业务点:
当输入不变时,无论你怎么优化内部实现、调整内部次序,这个测试关心的业务场景都不会挂,真正做到了测试保护重构、支持重构的作用
可以仅断言你关心的点,忽略不重要或不关心的中间过程(比如上例中,我们就没有断言其他
notImportant的 action 是否被 dispatch 出去),消除无关断言的杂音,提升了表达力使用了
product这样的测试数据创建套件(fixtures),精简测试数据,消除无关数据的杂音,提升了表达力自定义的
expect(action).toHaveBeenDispatchedWith(payload)matcher 很有表达力,且出错信息友好
这个自定义的 matcher 是通过 jest 的 expect.extend 扩展实现的:
expect.extend({
toHaveBeenDispatched(action) { ... },
toHaveBeenDispatchedWith(action, payload) { ... },
})
上面是我们认为比较好的副作用测试工具、测试策略和测试方案。使用时,需要牢记你真正关心的业务价值点(也即本节开始提到的 5 点),以及做到在较为复杂的单元测试中始终坚守几条基本原则。唯如此,单元测试才能真正提升开发速度、支持重构、充当业务上下文的文档。
作者注:本文成文后,社区又有一些简化测试的方案出来。读者也可带着这些测试原则去考察一番:
https://github.com/jfairbank/redux-saga-test-plan
https://github.com/testing-library/react-testing-library
component 测试
组件测试其实是实践最多、测试实践看法和分歧也最多的地方。React 组件是一个高度自治的单元,从分类上来看,它大概有这么几类:
展示型业务组件
容器型业务组件
通用 UI 组件
功能型组件
先把这个分类放在这里,待会回过头来谈。对于 React 组件测什么不测什么,我有一些思考,也有一些判断标准:除去功能型组件,其他类型的组件一般是以渲染出一个语法树为终点的,它描述了页面的 UI 内容、结构、样式和一些逻辑 component(props) => UI。内容、结构和样式,比起测试,直接在页面上调试反馈效果更好。测也不是不行,但都难免有不稳定的成本在;逻辑这块,有一测的价值,但需要控制好依赖。综合上面提到的测试原则进行考虑,我的建议是:两测两不测。
组件分支渲染逻辑必须测
事件调用和参数传递一般要测
连接 redux 的高阶组件不测
渲染出来的 UI 不在单元测试层级测
组件的分支逻辑,往往也是有业务含义和业务价值的分支,添加单元测试既能保障重构,还可顺便做文档用;事件调用同样也有业务价值和文档作用,而事件调用的参数调用有时可起到保护重构的作用。
纯 UI 不在单元测试级别测试的原因,纯粹就是因为不好断言。所谓快照测试有意义的前提在于两个:必须是视觉级别的比对、必须开发者每次都认真检查。jest 有个 snapshot 测试的概念,但那个 UI 测试是代码级的比对,不是视觉级的比对,最终还是绕了一圈,去除了杂音还不如看 Git 的 commit diff。每次要求开发者自觉检查,既打乱工作流,也难以坚持。考虑到这些成本,我不推荐在单元测试的级别来做 UI 类型的测试。对于我们之前中等规模的项目,诉诸手工还是有一定的可控性。
连接 redux 的高阶组件不测。原因是,connect 过的组件从测试的角度看无非几个测试点:
mapStateToProps中是否从store中取得了正确的参数mapDispatchToProps中是否地从actions中取得了正确的参数map 过的
props是否正确地被传递给了组件redux 对应的数据切片更新时,是否会使用新的
props触发组件进行一次更新
这四个点,react-redux 已经都帮你测过了,已经证明 work 了,开发者没有必要进行测试。当然,不测这个东西的话,还是有这么一种可能,就是你 export 的纯组件测试都是过的,但是代码实际运行出错。穷尽下来主要可能是这几种问题:
你在
mapStateToProps中打错了字或打错了变量名你写了
mapStateToProps但没有 connect 上去你在
mapStateToProps中取的路径是错的,在 redux 中已经被改过
第一、二种可能,如果是小步前进其实发现起来很快。如果某段数据获取的逻辑多处重复,则可以考虑将该逻辑抽取到 selector 中并进行单独测试;第三种可能,确实是问题,但由于在我所在项目发生频率较低(部分因为上个项目没有类型系统我们不会随意改 redux 的数据结构…),所以针对这些少量出现的场景,不必要采取错杀一千的方式进行完全覆盖。默认不测,出了问题或者经常可能出问题的部分,再策略性地补上测试进行固定即可。
综上,@connect 组件默认不测,因为框架本身已做了大部分测试,剩下的场景出 bug 频率不高,而施加测试的话提高成本(准备依赖和数据),降低开发体验,性价比不大,所以建议省了这份心。不测 @connect 过的组件,其实也是 官方文档 推荐的做法。
然后,基于上面第 1、2 个结论,映射回四类组件的结构当中去,我们可以得到下面的表格,然后发现…每种组件都要测渲染分支和事件调用,跟组件类型根本没必然的关联…不过,功能型组件有可能会涉及一些其他的模式,因此又大致分出一小节来谈。
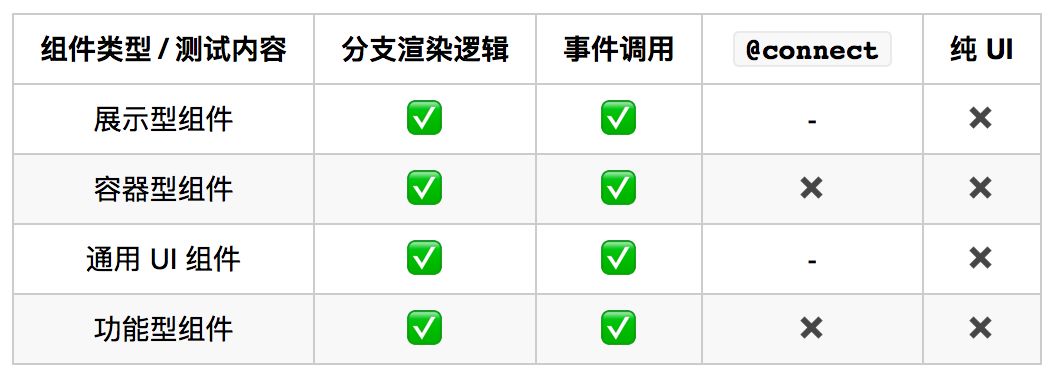
业务型组件 - 分支渲染
export const CommentsSection = ({ comments }) => (
<div>
{comments.length > 0 && (
<h2>Comments</h2>
)}
{comments.map((comment) => (
<Comment content={comment} key={comment.id} />
)}
</div>
)
对应的测试如下,测试的是不同的分支渲染逻辑:没有评论时,则不渲染 Comments header。
import { CommentsSection } from './index'
import { Comment } from './Comment'
test('should not render a header and any comment sections when there is no comments', () => {
const component = shallow(<CommentsSection comments={[]} />)
const header = component.find('h2')
const comments = component.find(Comment)
expect(header).toHaveLength(0)
expect(comments).toHaveLength(0)
})
test('should render a comments section and a header when there are comments', () => {
const contents = [
{ id: 1, author: '男***8', comment: '价廉物美,相信奥康旗舰店' },
{ id: 2, author: '雨***成', comment: '所以一双合脚的鞋子...' },
]
const component = shallow(<CommentsSection comments={contents} />)
const header = component.find('h2')
const comments = component.find(Comment)
expect(header.html()).toBe('Comments')
expect(comments).toHaveLength(2)
})
业务型组件 - 事件调用
测试事件的一个场景如下:当某条产品被点击时,应该将产品相关的信息发送给埋点系统进行埋点。
export const ProductItem = ({
id,
productName,
introduction,
trackPressEvent,
}) => (
<TouchableWithoutFeedback onPress={() => trackPressEvent(id, productName)}>
<View>
<Title name={productName} />
<Introduction introduction={introduction} />
</View>
</TouchableWithoutFeedback>
)
import { ProductItem } from './index'
test(`
should send product id and name to analytics system
when user press the product item
`, () => {
const trackPressEvent = jest.fn()
const component = shallow(
<ProductItem
id={100832}
introduction="iMac Pro - Power to the pro."
trackPressEvent={trackPressEvent}
/>
)
component.find(TouchableWithoutFeedback).simulate('press')
expect(trackPressEvent).toHaveBeenCalledWith(
100832,
'iMac Pro - Power to the pro.'
)
})
简单得很吧。这里的几个测试,在你改动了样式相关的东西时,不会挂掉;但是如果你改动了分支逻辑或函数调用的内容时,它就会挂掉了。而分支逻辑或函数调用,恰好是我觉得接近业务的地方,所以它们对保护代码逻辑、保护重构是有价值的。当然,它们多少还是依赖了组件内部的实现细节,比如说 find(TouchableWithoutFeedback),还是做了“组件内部使用了 TouchableWithoutFeedback 组件”这样的假设,而这个假设很可能是会变的。也就是说,如果我换了一个组件来接受点击事件,尽管点击时的行为依然发生,但这个测试仍然会挂掉。这就违反了我们所说了“不关注内部实现”原则,这对于组件测试来说,确实是不够完美的地方。
但这个问题无法避免。因为组件本质是渲染组件树,那么测试中要与组件树关联,必然要通过组件名、id这样的 selector,这些 selector 的关联本身就是一些“内部实现”的细节。但对组件的分支、事件进行测试又有一定的价值,无法避免。所以,我认为这个部分还是要用,只不过同时需要一些限制,以控制这些假设为维护测试带来的额外成本:
不要断言组件内部结构。像那些
expect(component.find('div > div > p').html().toBe('Content')的真的就算了吧正确拆分组件树。一个组件尽量只负责一个(或一组高度相关的)功能,不允许堆叠太多的函数和功能
也就是说,如果你发现你很难快速地准备对组件的测试,那么有可能是你的组件太复杂了,这也是一个坏味道。多数情况下是组件承担了太多的职责,你应该将它们拆成更小的组件,使其符合单一职责原则。
如果你的每个组件都十分清晰直观、逻辑分明,那么像上面这样的组件测起来也就很轻松,一般就遵循 shallow -> find(Component) -> 断言的三段式,哪怕是了解了一些组件的内部细节,通常也在可控的范围内,维护起来成本并不高。这是目前我觉得平衡了表达力、重构意义和测试成本的实践。
功能型组件 - children 型高阶组件
功能型组件,指的是跟业务无关的另一类组件:它是功能型的,更像是底层支撑着业务组件运作的基础组件,比如路由组件、分页组件等。这些组件一般偏重逻辑多一点,关心 UI 少一些。其本质测法跟业务组件是一致的:不关心 UI 具体渲染,只测分支渲染和事件调用。但由于它偏功能型的特性,使得它在设计上常会出现一些业务型组件不常出现的设计模式,如高阶组件、以函数为子组件等。下面分别针对这几种进行分述。
export const FeatureToggle = ({ features, featureName, children }) => {
if (!features[featureName]) {
return null
}
return children
}
export default connect(
(store) => ({ features: store.global.features })
)(FeatureToggle)
import React from 'react'
import { shallow } from 'enzyme'
import { View } from 'react-native'
import FeatureToggles from './featureToggleStatus'
import { FeatureToggle } from './index'
const DummyComponent = () => <View />
test('should not render children component when remote toggle does not exist', () => {
const component = shallow(
<FeatureToggle features={{}} featureName="promotion618">
<DummyComponent />
</FeatureToggle>
)
expect(component.find(DummyComponent)).toHaveLength(0)
})
test('should render children component when remote toggle is present and is on', () => {
const features = {
promotion618: FeatureToggles.on,
}
const component = shallow(
<FeatureToggle features={features} featureName="promotion618">
<DummyComponent />
</FeatureToggle>
)
expect(component.find(DummyComponent)).toHaveLength(1)
})
test('should not render children component when remote toggle is present but is off', () => {
const features = {
promotion618: FeatureToggles.off,
}
const component = shallow(
<FeatureToggle features={features} featureName="promotion618">
<DummyComponent />
</FeatureToggle>
)
expect(component.find(DummyComponent)).toHaveLength(0)
})
utils 测试
每个项目都会有 utils。一般来说,我们期望 util 都是纯函数,即是不依赖外部状态、不改变参数值、不维护内部状态的函数。这样的函数测试效率也非常高。测试原则跟前面所说的也并没什么不同,不再赘述。不过值得一提的是,因为 util 函数多是数据驱动,一个输入对应一个输出,并且不需要准备任何依赖,这使得它多了一种测试的选择,也即是参数化测试的方式。参数化测试可以提升数据准备效率,同时依然能保持详细的用例信息、错误提示等优点。jest 从 23 后就内置了对参数化测试的支持,如下:
test.each([
[['0', '99'], 0.99, '(整数部分为0时也应返回)'],
[['5', '00'], 5, '(小数部分不足时应该补0)'],
[['5', '10'], 5.1, '(小数部分不足时应该补0)'],
[['4', '38'], 4.38, '(小数部分不足时应该补0)'],
[['4', '99'], 4.994, '(超过默认2位的小数的直接截断,不四舍五入)'],
[['4', '99'], 4.995, '(超过默认2位的小数的直接截断,不四舍五入)'],
[['4', '99'], 4.996, '(超过默认2位的小数的直接截断,不四舍五入)'],
[['-0', '50'], -0.5, '(整数部分为负数时应该保留负号)'],
])(
'should return %s when number is %s (%s)',
(expected, input, description) => {
expect(truncateAndPadTrailingZeros(input)).toEqual(expected)
}
)
当然,对纯数据驱动的测试,也有一些不同的看法,认为这样可能丢失一些描述业务场景的测试描述。所以这种方式还主要看项目组的接受度。
总结
好,到此为止,本文的主要内容也就讲完了。总结下来,本文主要覆盖到的内容如下:
单元测试对于任何 React 项目(及其他任何项目)来说都是必须的
我们需要自动化的测试套件,根本目标是支持随时随地的代码调整、持续改进,从而提升团队响应力
使用TDD开发是得到好的单元测试的唯一途径
好的单元测试具备几大特征:不关注内部实现、只测一条分支、表达力极强、不包含逻辑、运行速度快
单元测试也有测试策略:在 React 的典型架构下,一个典型的测试策略为:
reducer、selector 层的逻辑代码要求 100% 覆盖
saga(副作用)层:是否拿到了正确的参数、是否调用了正确的 API、是否保存了正确的数据、业务逻辑、异常逻辑五个层面要求100%覆盖
action 层选择性覆盖:可不测
utils 层的纯函数要求 100% 覆盖
组件层:
分支渲染逻辑必测、事件、交互调用要求100%覆盖;
@connect过的高阶组件不测纯 UI 一般不测
其他高级技巧:定制测试工具(
jest.extend)、参数化测试等
未尽话题
诚然,关于构建一个完整的前端测试体系,有一些点是本文没有涉及到的,或因为没有涉猎,或因为尚未尝试,或因为未有结论,一并罗列于下。有兴趣的读者可来电交流。
其他层级的测试:前端典型的其他层级测试如契约测试、端到端测试等
CSS的测试
HTML的测试与重构
参考
为什么TDD是敏捷的核心实践
测试金字塔实战
Mock的七宗罪
- 相关阅读 -
点击【阅读原文】可至洞见网站查看原文&绿色字体部分的相关链接。
本文版权属ThoughtWorks公司所有,如需转载请在后台留言联系。
以上是关于React 单元测试策略及落地的主要内容,如果未能解决你的问题,请参考以下文章