分布式事务消息中心TMC
Posted 51NB技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务消息中心TMC相关的知识,希望对你有一定的参考价值。
系统原理
贷款和理财是51信用卡目前最主要的业务。金融相关的应用,往往对数据的一致性有着较高的要求,通常对DB的操作都是用事务来保障。但是在分布式的环境下,要保持事务的一致性从来都不是一件容易的事,传统通过两阶段、三阶段提交方式实现的XA事务由于代价太高,性能损失太大,在互联网公司中并不常用,而更常用的是实现最终一致性,即系统允许短暂的不一致,但是最终能达到一致的状态。
51信用卡金融研发团队之前对跨微服务的调用就有一些方法,在执行业务逻辑前先插一张状态日志表,在执行成功后更新日志表里的状态,如果有中途失败的交易,后续也可以通过扫描日志表进行更正。TMC做的事就是业务里做的逻辑抽象独立出来,让业务专注于业务开发,无需再自己维护状态。下面简述其原理:
两个事务运行在不同的进程上,为了平衡上下游系统压力差、削峰填谷都会使用MQ。但是直接使用MQ并不能实现分布式事务,下面举个例子说明:
假设两个独立账务系统A和B,A要向B转100块钱,直接使用MQ的如下图所示:
操作分四个步骤
1. 系统A更新DB,扣减100元
2. publish一条消息进MQ
3. MQ将消息发给系统B
4. 系统B更新DB,加100元
分布式系统,任何一个环节都有可能失败,下面一一分析:
① 步骤1A更新DB前挂了,无影响,因为还没扣钱
② 更新DB后投进MQ前挂掉,消息丢了,100块不知道去哪了
③ A成功写进MQ,但是MQ这时候挂了,同样消息丢了
④ MQ成功投递给B,但是B写进DB之前B挂掉,同样100块不知道去哪了
⑤ B成功写进DB,B系统加100块,这种情况正常
因此要实现分布式事务,就是要考虑消息在各个环节中都不丢,任一系统在挂掉的情况下,都能保证能够把消息找回来,并且流程还能够继续下去。
下面开始介绍我们的实现方案,为了记录状态,我们引入了一个中间人,即TMC(TransactionMessage Center),示意如下图:
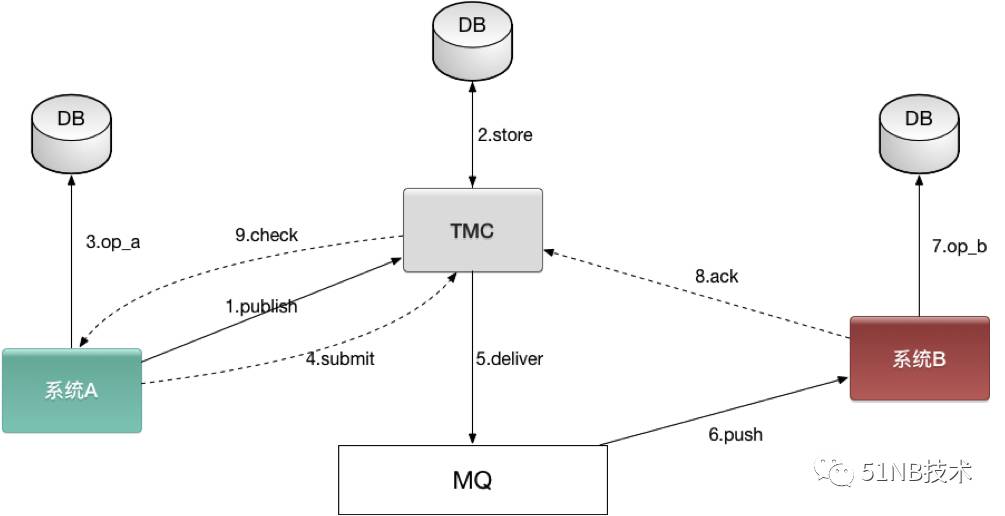
现在的步骤如下:
1. 系统A publish一条消息给TMC
2. TMC在DB中记录下这条消息
3. 系统A执行本地事务更新DB
4. 系统A如果本地事务执行成功,告诉TMC这条消息submit,如果本地事务执行失败,告诉TMC这条消息rollback
5. TMC对于成功submit的消息,开始往MQ进行投递,等待ack,如果一段时间没有收到ack,会继续投递该消息
6. MQ将消息push给消费者系统B
7. 系统B执行事务更新DB
8. 系统B给TMC做ack,告诉这条消息消费成功
正常的流程就是这样,下面分析下各个环节可能出现的异常,以及异常流程。
① 系统A publish消息给TMC之前挂了,无影响,因为啥都还没做
② 系统A执行本地事务之前或者之后挂了,这时候会涉及到9. check过程,因为TMC已经记录下这条消息,但是后面没有收到submit或者rollback,不知道这条消息的状态,只好过了一段时间去问系统A,这条消息到底是什么状态,如果A是执行事务之前挂的,会答复rollback,这时候TMC删除这条消息,如果是执行事务之后挂的,答复commit,这时候TMC将这条消息转变成可消费状态,开始向MQ投递
③ TMC将消息投递进MQ没有成功,或者MQ挂了,消息丢了。这时候消费者肯定收不到消息,也就不会进行ack,TMC会在一段时间后继续将该消息投递进MQ,这个过程会持续好几次,超过一定次数标记消费失败,给出报警
④ 消费者系统B受到消息,更新DB后挂了,ack没有给到TMC,这就像上一条所说,TMC会继续投递该消息,因此消费者一定要实现幂等应对重复消息
系统设计
TMC的设计和51信用卡公司内部在用的系统紧密结合,使用了mysql、Base框架(51信用卡内部的一个微服务框架,最主要功能是RPC和服务发现)、Consul、RabbitMQ,这里做一个详细一点的介绍,帮助大家理解系统,在测试环境能够更好的调试。系统结构图如下:
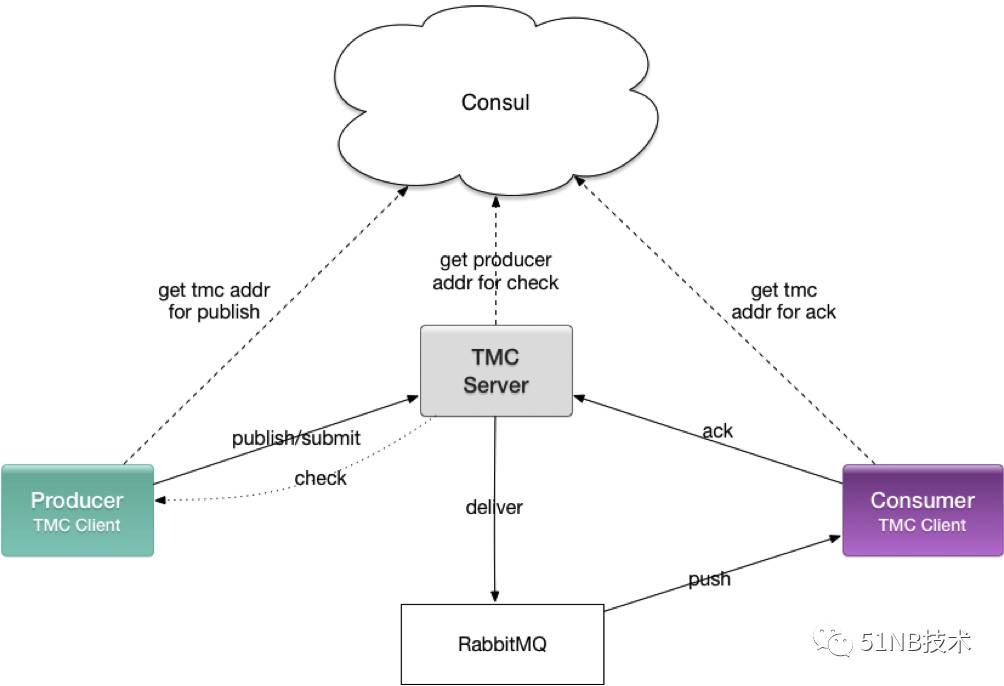
• TMC Server是一个标准的基于Base的微服务
• TMC Client是一个基于Base的Client,通过maven分发,包含Producer和Consumer功能
系统之间的交互可以描述为以下几点:
- TMC Server会将成功submit的消息投递进RabbitMQ
数据库表结构
表结构很简单,主要包括应用表(T_Tmc_PubSub)、Topic表(T_Tmc_Topic)、订阅表(T_Tmc_Topic_Sub)、消息表(T_Tmc_Msg)、消费表(T_Tmc_Msg_Sub),关系如下图
• 应用表,AppId即对应客户端clientId,AppKey对应clientKey,AppName即是微服务名,另外还有报警人邮箱和手机号信息
• Topic表,每个topic都需要指定tag,这个表里的tag应该和客户端的clientTag对应,Mode表示topic模式,0是单队列,1是多队列,另外还有最大重试次数和重试间隔配置,这两个是针对check生产者的重试
• 订阅表,即表示哪个消费者订阅了哪个topic,也有最大重试次数和重试间隔配置,这两个是针对消费者ack的重试
• 消息表,消息分表存放,目前32张,将来不够很容易扩容,消息存放在哪张分表由topic表的TableIndex指定,MsgId是在消息落库时候生成,里面包含里topicId和生产者Id,MsgKey是生产者指定,推荐存放一个具有一定业务意义的,用于做幂等控制,消息内容通过base64编码后存放在body字段,由于mysql限制,消息内容不能超过10K,Delay是延迟消息时候需要设置延迟的时间,Retry和NextRetryTime是check生产者的次数和下次的时间,大多数消息都是生产者主动submit上来,所以这两个字段不常用
• 消费表,在生产者submit消息之后,有几个消费者订阅了该topic,就会在该表中生成几条数据,同时消费表也是分表,分表规则和消息表一样。消费表并不复制消息的内容,只是记录每条消息每个消费者消费的状态,该表的Retry和NextRetryTime是已经向RabbitMQ投递的次数,和下次再投递的时间
单队列 or 多队列
TMC刚上线的时候只有单队列模式,后来有业务提出问题,单队列可能造成低优先级消息阻塞高优先级消息的情况,因此又加了多队列模式,如上面的图。
单队列是指每个消费者,会订阅不同的TMC topic,他所的所有TMC消息,会放在同一个RabbitMQ队列里,队列的命名规则是tmc.sub.{clientId}.{clientTag}。有些消息,可能时效性要求比较高,量比较小,而有些消息,时效性要求比较低,但量比较大,放在同一个队列里就会影响后面重要消息的消费时效性。
而多队列每一个消费者,每一个TMC topic都会放在一个单独的RabbitMQ队列里,命名规则是tmc.sub.{clientId}.{clientTag}.{topic},这样就不会造成高优先级消息被低优先级消息阻塞的问题。
由于单/多队列的命名规则不同,因此在client端消息入口不同,单队列通过实现MessageConsumer接口,而多队列通过打@TmcListener标注。
失败和重试
事务消息的事务,主要体现在生产者和Server之间,因为只有生产者本地事务失败是可以回滚消息的,而只要生产者事务成功提交,消费者是一定要消费掉的,超过一定时间没有消费掉,会给出报警,让人工介入处理。
重试主要用在两个地方
1. 生产者没有主动submit/rollback,Server存在未知状态消息,需要不断去生产者那边check改消息的状态
2. 消息已经成功被submit,Server已经投进MQ,但是消费者一直没有ack,需要继续投递,直到被ack
重试的程序实现是,每个分表都有一个扫表线程,这个扫表线程落在哪台机器上,通过Base里的分布式锁抢占,即抢到分表的分布式锁的机器负责扫该表。那每次扫出哪些消息?取决于Status和NextRetryTime,只有Status等于正在进行的并且NextRetryTime小于当前时间的会被扫出来。
而NextRetryTime的更新规则是now + Retry *RetryInterval,Retry是已经重试的次数,这样的重试时间是被逐渐拉长的,举个例子,如果起始时间是0,RetryInterval是10s,那一次重试是在10s,第二次重试是在30s,第三次重试是在60s,第四次重试是在100s。这样设计是考虑到,当前无法消费成功的消息,短期内立即重试大概率仍然不能消费成功,所以逐渐拉长重试的时间。
凡是投递超过MaxRetryTimes的消息,更新状态为失败,不在继续重试,并且发送报警给登记的业务负责人。
消息查询和重新激活
在控制后台支持通过MsgId、MsgKey以及状态和时间范围查询消息的状态,并且对于失败的消息,可以一键重新激活,重新开始check或者投递。控制后台拥有的功能消息查询,消费查询,消息重试,投递重试,很容易搞混,下面来说明一下。
- 消息查询,是查询消息表的数据,查询消息是否入库,是否被submit,以及消息的内容(原始base64和解码过的字符串格式都能看到),check的次数,下次check时间
- 消费查询,是查询消费表的数据,是否生成消费记录(如果没有说明生产者还没submit),是否被ack,投递的次数,下次投递的时间
- 消息重试,是生产者还没有提交,超过check重试的失败消息,进行重新激活,重新开始check生产者消息的状态
- 投递重试,是超过投递次数,消费者还没有ack的失败消息,进行重新激活,重新开始往MQ投递
额外的小功能
业务在使用过程中,提出了一些特殊的小需求,TMC也试着满足他们的需求,列举如下:
- 测试环境支持生产、消费不同tag,由于公司测试有好几个环境dev、stable、k8stest等等,为方便开发和测试同学,生产和消费都支持指定tag
- 延迟消息,生产者可以指定delay参数,Server在submit后到达delay的时间才会开始投递
- 顺序消息(未上线),之前有业务提过,想要支持顺序消息,就尝试把RabbitMQ换成支持顺序消息的MQ,如RocketMQ,但后来业务改了方案不需要了,这份代码就暂时没合入主分支,没有上线
英雄帖
51信用卡技术团队正在招聘,技术岗位全线开放。如果你也想助力金融、码出NB未来,欢迎投递简历或询问:JSYF_HRBP@u51.com
以上是关于分布式事务消息中心TMC的主要内容,如果未能解决你的问题,请参考以下文章