分布式事务--消息补偿的最终一致
Posted 架构师前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务--消息补偿的最终一致相关的知识,希望对你有一定的参考价值。
大规模业务数据的方案一般都是分库分表,而且一些场景会同时跨多个库发生业务。在 ""一文中,我们讲到事务消息的MQ补偿方案是目前公认的较为理想的分布式
事务解决方案,实施成本也较高,今天我们即讲述这种补偿方案的最终一致性落地细节。
一、消息补偿流程
回顾之前我们提到,消息中间件在分布式系统中的主要作用:异步通讯、解耦、并发缓冲。基于MQ实现分布式事务一致性是一种异步确保型的实现方案,将同步阻塞的事务变成异步的,避免对数据库事务的争用。大致流程如下:
基于消息补偿的分布式事务方案往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。
二、事务补偿应用
2.1 假设业务场景
"假设用户a从自己的余额中向用户c余额中转100元钱。用户a余额存放在A库中,用户c余额存在C库中",如下图:
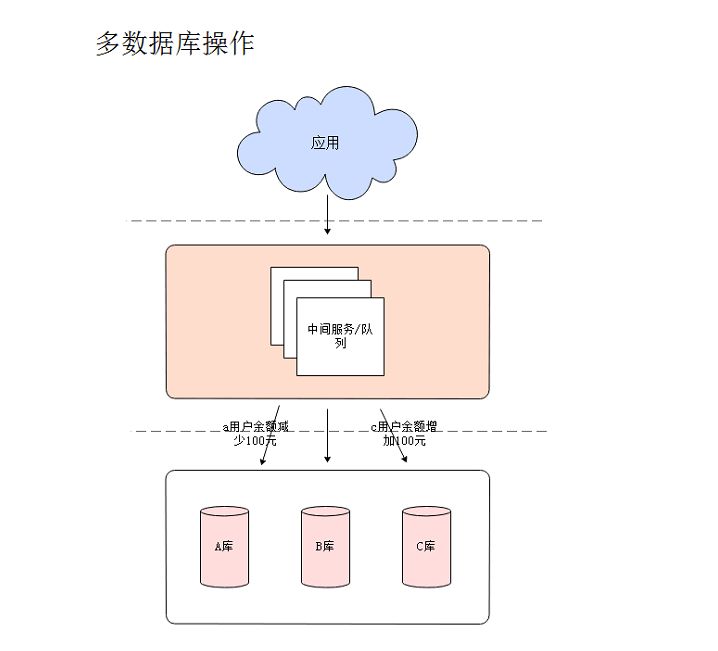
由于分库的存在,破坏了事务的原子性,如果没有分布式事务,转账过程可能会出现如下的问题:
问题:
1. 应用写队列超时导致重发了消息.那么结果是a本来向c转账100元.结果却转账了200元.
2. 应用将消息成功写入队列,但是队列服务器挂了.结果是a向c转账失败.
3. 中间层(队列的消费者)将消息取出,修改a的账户余额,但是用户a的库挂了,导致事务失败.结果是a向c转账失败.
4. 中间层已经成功修改了用户a的账户余额,但是在修改c用户余额的时候,用户c的数据库挂了。结果是用户a的钱扣了,但是用户c的钱没有增加.
5. 中间层从队列拿到了消息,但是还未及处理,中间层本身挂了.
2.2 基于队列事务的最终一致性解决方法
需要的前置工具或表:
1. 分布式ID生成器。
2. transaction_log(tran_id,a,c,money),事务业务日志表
3. message_log(tran_id,account,money),消息日志表
结合"消息补偿流程"中的流程图,总体步骤如下:
补偿方案:
1. 应用通过ID生成器生成事务id,将本次事务日志写入事务业务日志表,暂不提交。
2. 向队列发送两个消息.一个消息是用户a -100元,另一消息是用户c +100元,两个消息需要带上第一步得到的tran_id。确保两个消息都成功入队列,则提交业务日志的事务。一旦有任何异常,回滚事务。提交了事务,应用则可以直接返回.提示用户交易完成。
3. 中间层获取消息。先连接用户a的数据库.查询transaction_log表,如果没有该全局事务ID,则不予处理.(确认有这个全局事务,才处理),查询message_log表,如果存在记录,则不予处理.(防止消息超时重发)。开始消费端本地事务.update用户a余额,减100元.再写message_log表,记录本次处理,最后本地提交事务。
4. 中间层连接用户c的数据库,做相同的操作。
5. 一个定时任务,每隔5分钟,检查transaction_log和message_log中是否存在不一致的tran_id.如果有不一致的情况,则进行事务补偿或人工处理。
6. 完成完成转账。
三、潜在问题
3.1 . 从上述流程来看,将本地事务和发消息放在了一个分布式事务里,需要保证要么本地操作成功并且对外发消息成功,要么两者都失败。实际中,支持这个原子操作的消息中间件并不多(rabbitMq、kafkaMq等都不支持),阿里开源的RocketMQ支持这一特性。
3.2. 随着业务增多,transaction_log、message_log表会比较大,这2张表也需要考虑分库。否则瓶颈会特别大。
3.3. 其他一些性能问题,如消费端检查message_log时,怎样防止消费重复消息等。
相关文章
以上是关于分布式事务--消息补偿的最终一致的主要内容,如果未能解决你的问题,请参考以下文章