整体介绍分布式事务
Posted 架构师成长营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了整体介绍分布式事务相关的知识,希望对你有一定的参考价值。
分布式事务之一:整体介绍
分布式事务场景如何设计系统架构及解决数据一致性问题,个人理解最终方案把握以下原则就可以了,那就是:大事务=小事务(原子事务)+异步(消息通知),解决分布式事务的最好办法其实就是不考虑分布式事务,将一个大的业务进行拆分,整个大的业务流程,转化成若干个小的业务流程,然后通过设计补偿流程从而考虑最终一致性。
一、基本概念
原则
真正重要的是满足业务需求,而不是追求抽象、绝对的系统特性
帽子戏法
酸碱(ACID-BASE Balance)
模式
服务模式
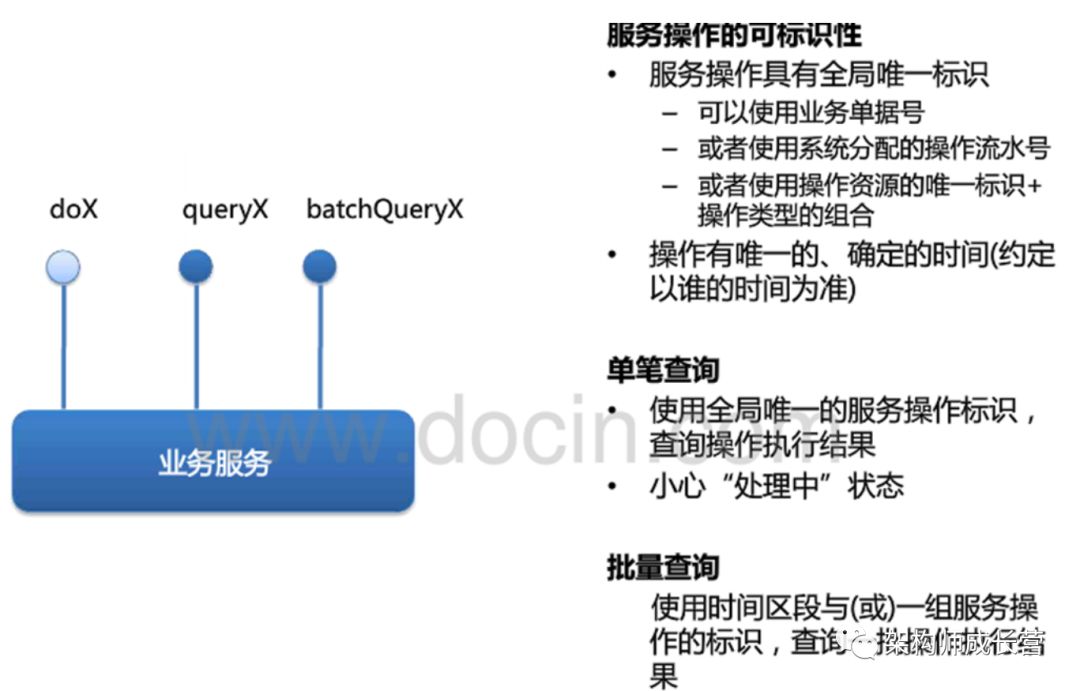
可查询操作
幂等操作
TCC操作
可补偿操作
复合模式
定期校对
可靠消息
TCC
补偿
1、事务(Transaction)及其ACID属性
事务是由一组SQL语句组成的逻辑处理单元,事务具有以下4个属性,通常简称为事务的ACID属性:
原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
隔离性(Isoation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
持久性(Durabe):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
2、事务分本地事务和分布式事务
2.1、本地事务
事务由资源管理器(如DBMS)本地管理
优点:严格的ACID
缺点:不具备分布事务处理能力
2.2、全局事务(DTP模型)
TX协议:应用或应用服务器与事务管理器的接口
XA协议:全局事务管理器与资源管理器的接口
优点:严格的ACID
缺点:效率非常低
两阶段提交(2PC)
优点
准备后,仍可提交或回滚
准备时,一致性检查必须OK
准备后,事务结果仍然只在事务内可见
准备后,事务结果已经持久化
缺点:
潜在故障点多带来的脆弱性
准备后,提交前的故障引发一系列隔离与恢复难题
本地事务和分布式事务现在已经非常成熟,相关介绍很丰富,此处不多作讨论。见《DTP模型之一:(XA协议之一)XA协议、二阶段2PC、三阶段3PC提交》
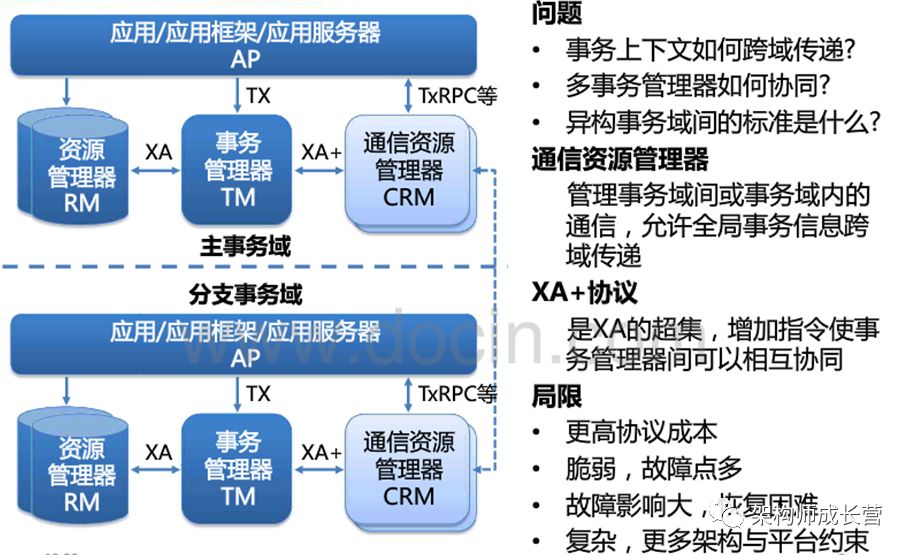
2.3、跨域的全局事务(DTP模型)
缺点
更高的协议成本
脆弱,故障点多
故障影响大,恢复困难
复杂,更多架构与平台约束
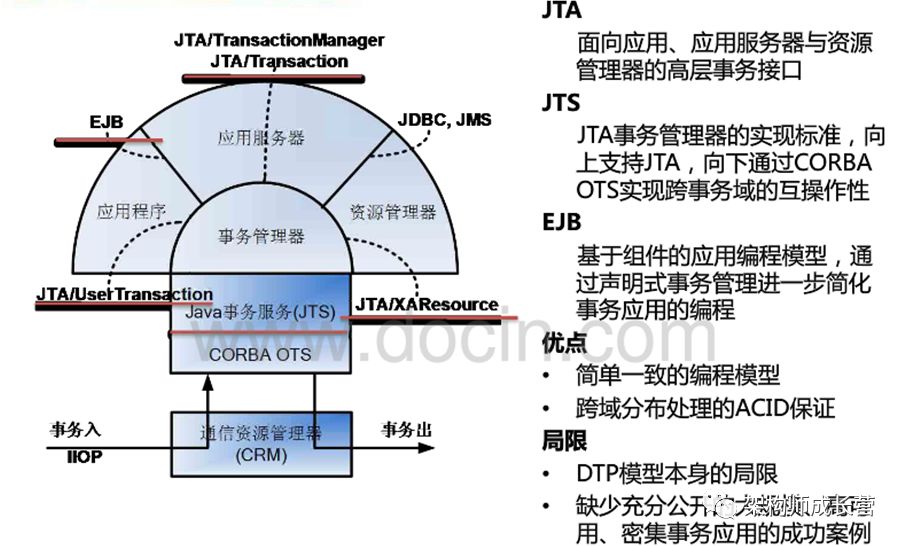
2.4、java企业平台中的分布式事务实现
JTA
面向应用、应用服务器与资源管理器的高层事务接口
JTS
JTA事务管理器的实现标准,向上支持JTA,向下通过CORBA OTS实现跨事务域的互操作性
EJB
基于组件的应用编程模型,通过申明式事务管理进一步简化事务应用的编程
优点
简单一致的编程模型
跨域分布处理的ACID保证
局限
DTP模型本身的局限
缺少充分公开的大规模、高可用、密集事务应用的成功案例
2.5、其它资源
ws-transaction标准
OASIS组织通过的Web Service事务标志,包含WS-Cordination、WS-AtomicTransaction、WS-BusinessActivity
jbossTransaction系统
开源的JTA、JTS、WS-Transaction标准的实现
Paxos算法
分布式系统中就某个提议达成一致性的算法族
3、分布式原则
3.1、CAP(帽子戏法)

3.2、ACID-BASE Balance(酸碱平衡)
详见《CAP原则(CAP定理)、BASE理论》
4、模式
服务模式
可查询操作
幂等操作
TCC操作
可补偿操作
复合模式
定期校对
可靠消息
TCC
补偿
服务模式之一:可查询操作
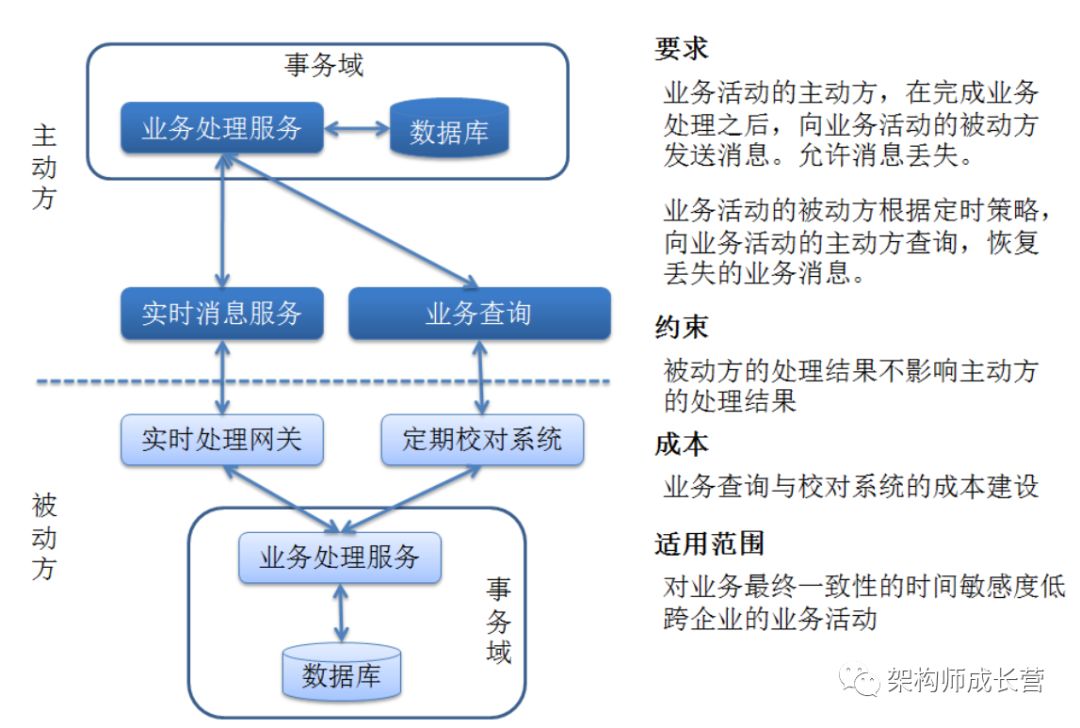
复合模式1:定期校对
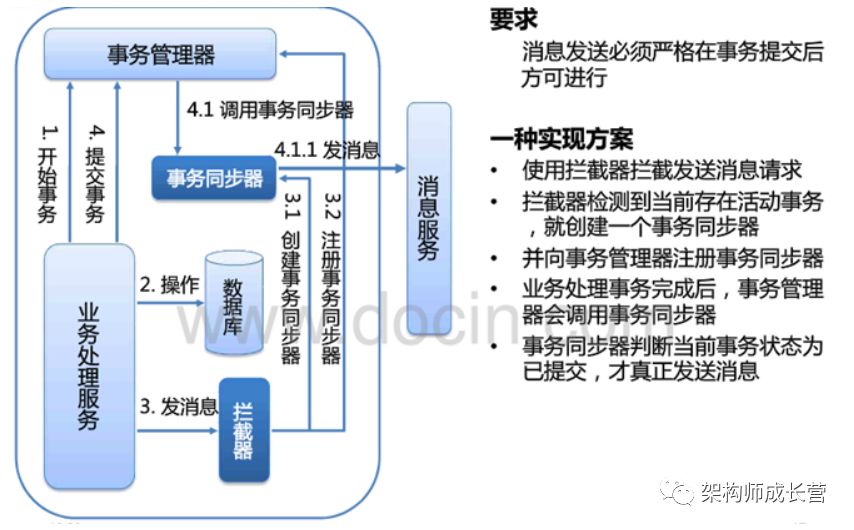
保证消息在事务提交后才发送
服务模式2:幂等操作

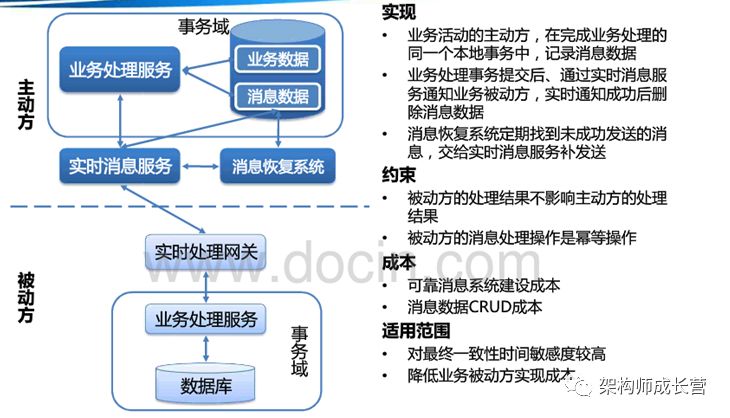
复合模式2:可靠消息
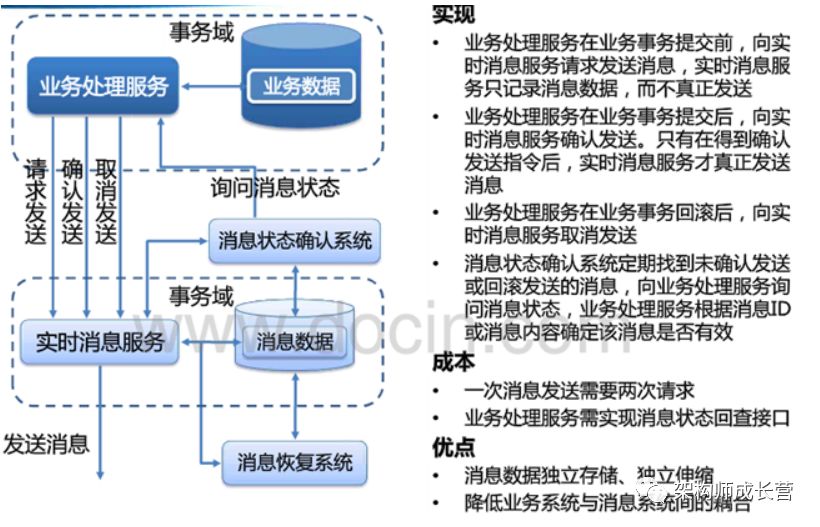
可靠消息的另一种实现
服务模式3:TCC模式
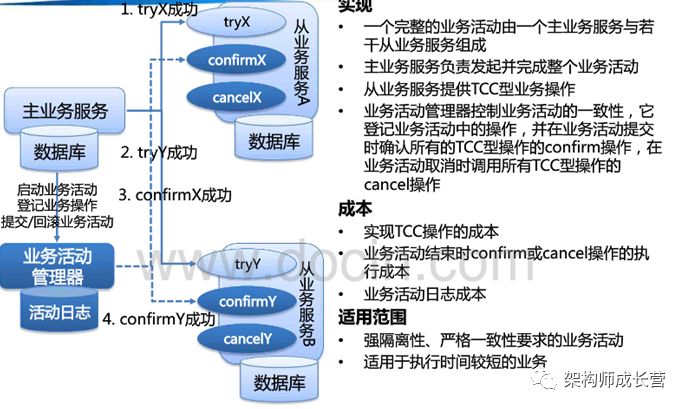
服务模式4:可补偿操作
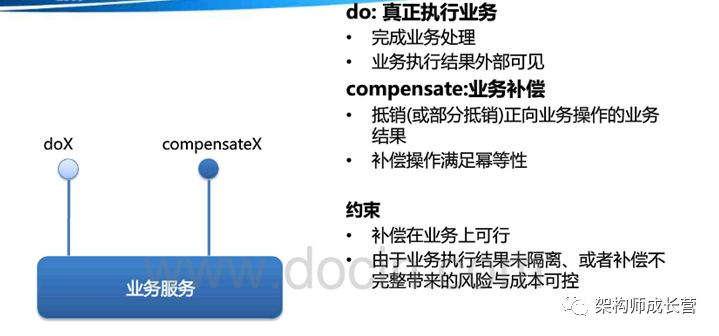
复合模式4:补偿模式
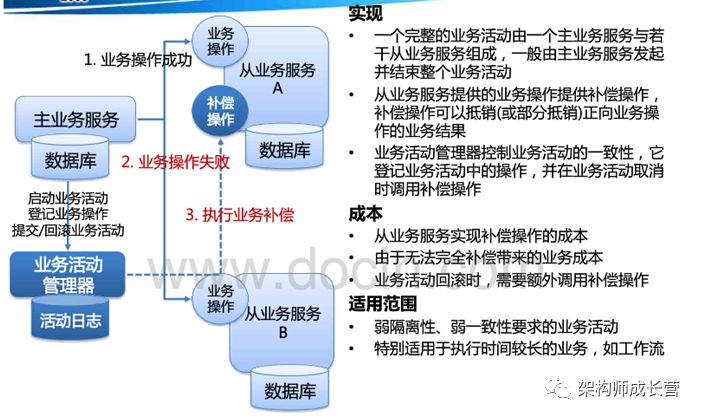
典型场景:银行转账业务
例如:李雷账户中有500块钱,韩梅梅账户有200块钱,李雷要从自己的账户中转100块钱给韩梅梅,转账(事务)成功执行完成后应该是李雷账户减100变为400,韩梅梅账户加100变为300,不能出现其他情况,即在事务开始和结束时数据都必须保持一致状态(一致性),事务结束时所有的数据及结构都必须是正确的。并且同样的转账操作(同一流水,即一次转账操作)无论执行多少次结果都相同(幂等性)。
电商场景:流量充值业务
再说我们做的一个项目:中国移动-流量充值能力中心,核心业务流程为:
用户进入流量充值商品购买页面,选择流量商品;
购买流量充值商品,有库存限制则判断库存,生成流量购买订单;
选择对应的支付方式(和包、银联、支付宝、微信)进行支付操作;
支付成功后,近实时流量到账即可使用流量商品;
此业务流程看似不是很复杂对吧,不涉及到类似电商业务的实物购买,但是我认为其中的区别并不是很大,只是缺少电商中的物流发货流程,其他流程几乎是一样的,也有库存以及优惠折扣等业务存在。
整个系统交互如下图:
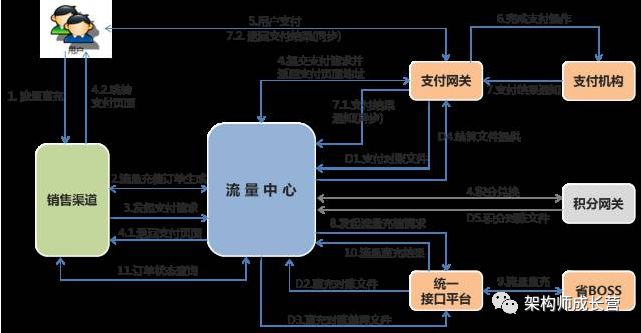
流量中心系统交互图流量中心系统交互图
分布式事务
上述两个场景的业务需求已经说完了,接着谈谈分布式事务,要说分布式事务那就先聊聊本地事务与分布式事务:
Ps:相同点:首先都是要保证数据正确(即ACID),本地事务与分布式事务还可以对应为:刚性事务与柔性事务,在我个人理解刚性事务与柔性事务的最大区别就是:一个完整的事务操作是否可以在同一物理介质(例如:内存)上同时完成;柔性事务就是一个完整事务需要跨物理介质或跨物理节点(网络通讯),那么排它锁、共享锁等等就没有用武之地了(这里并不是指大事务拆小事务【本地事务】后),无法保证原子性(Atomicity)完成事务。个人理解分布式(柔性)事务本质意义上就是-伪事务,柔性事务其实就是根据不同的业务场景使用不同的方法实现最终一致性,因为可以根据业务的特性做部分取舍,在业务过程中可以容忍一定时间内的数据不一致。
在知乎上面看过一篇文章,支付宝的柔性事务实现方式有四种分别针对不同的业务场景,如下图:
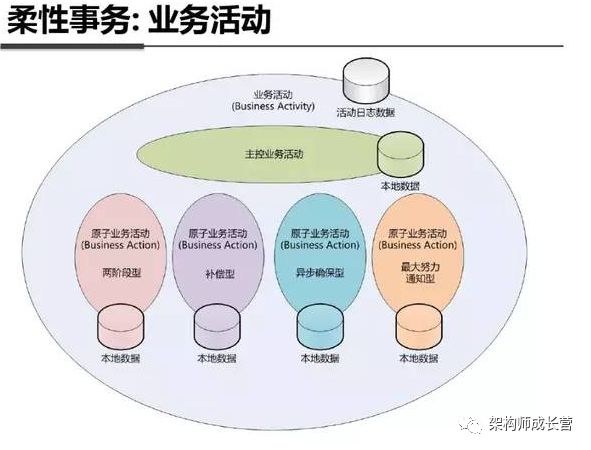
两阶段型
补偿型
异步确保型
最大努力通知型
引入日志和补偿机制:类似传统数据库,柔性事务的原子性主要由日志保证。事务日志记录事务的开始、结束状态,可能还包括事务参与者信息。参与者节点也需要根据重做或回滚需求记录REDO/UNDO日志。当事务重试、回滚时,可以根据这些日志最终将数据恢复到一致状态。为了避免单点,事务日志记录在分布式节点上的,通常柔性事务能通过日志记录找回事务的当前执行状态,并根据状态决定是重试异常步骤(正向补偿),还是回滚前序步骤(反向补偿)。
可靠消息传递:
两阶段型
上面有介绍
补偿型
如上面的TCC
异步确保型
通过将一系列同步的事务操作变为基于消息执行的异步操作, 避免了分布式事务中的同步阻塞操作的影响.这个方案真正实现了两个服务的解耦, 解耦的关键就是异步消息和补偿性事务。由于消息可能会重复投递,这 就要求消息处理程序必须实现幂等(幂等=同一操作反复执行多次结果不变),这一要求跟传统应用开发相比是非常具有互联网特征的一种模式。
幂等
每种业务场景不同,实现幂等的方法也会有所不同,最简单的幂等实现方式是根据业务流水号写日志,这种日志也叫做排重表。
实现无锁
数据库性能和吞吐率瓶颈往往是因为强事务带来的资源锁。如何很好地解决数据库锁问题时实现高性能的关键所在。所以选择放弃锁是一个解决问题的思路,但是放弃锁并不意味着放弃隔离性,如果隔离性没有保障,则必然带来大量的数据脏读、幻读等问题,最终导致业务不可控地不一致。
实现事务隔离的方法有很多,在实际的业务场景中可灵活选择以下几种典型的实现方式。
避免事务进入回滚。如果事务出现异常时,可以不回滚也能满足业务的要求,也就是要求业务不管出现任何情况,只能继续朝事务处理流程的顺向继续处理,这样中间状态即使对外可见,由于事务不会回滚,也不会导致脏读。
辅助业务变化明细表。比如对资金或商品库存进行增减处理时,可采用记录这些增减变化的明细表的方式,避免所有事务均对同一数据表进行更新操作,造成数据访问热点,同时使得不同事务中处理的数据互不干扰,实现对资金或库存信息处理的隔离。

乐观锁。数据库的悲观锁对数据访问具有极强的排他性,也是产生数据库处理瓶颈的重要原因,采用乐观锁则在一定程度上解决了这个问题。乐观锁大多是基于数据版本记录机制实现。
这里以一个例子作为讲解:
执行步骤如下:
MQ发送方发送远程事务消息到MQ Server;
MQ Server给予响应, 表明事务消息已成功到达MQ Server.
MQ发送方Commit本地事务.
若本地事务Commit成功, 则通知MQ Server允许对应事务消息被消费; 若本地事务失败, 则通知MQ Server对应事务消息应被丢弃.
若MQ发送方超时未对MQ Server作出本地事务执行状态的反馈, 那么需要MQ Servfer向MQ发送方主动回查事务状态, 以决定事务消息是否能被消费.
当得知本地事务执行成功时, MQ Server允许MQ订阅方消费本条事务消息.
需要额外说明的一点, 就是事务消息投递到MQ订阅方后, 并不一定能够成功执行. 需要MQ订阅方主动给予消费反馈(ack)
如果MQ订阅方执行远程事务成功, 则给予消费成功的ack, 那么MQ Server可以安全将事务消息移除;
如果执行失败, MQ Server需要对消息重新投递, 直至消费成功.
注意事项
消息中间件在系统中扮演一个重要的角色, 所有的事务消息都需要通过它来传达, 所以消息中间件也需要支持 HAC 来确保事务消息不丢失.
根据业务逻辑的具体实现不同,还可能需要对消息中间件增加消息不重复, 不乱序等其它要求.
适用场景
执行周期较长
实时性要求不高
例如:
跨行转账/汇款业务(两个服务分别在不同的银行中)
退货/退款业务
财务, 账单统计业务(先发送到消息中间件, 然后进行批量记账)
最大努力通知型
这是分布式事务中要求最低的一种, 也可以通过消息中间件实现, 与前面异步确保型操作不同的一点是, 在消息由MQ Server投递到消费者之后, 允许在达到最大重试次数之后正常结束事务.
适用场景
交易结果消息的通知等.
参考
大规模SOA系统中的分布事务处事_程立.pdf
用消息队列和消息应用状态表来消除分布式事务 http://techv5.com/topic/1380/
用消息队列来解决数据一致性问题 http://rfwiki.diandian.com/post/2013-01-08/40047419557
用Spring和RabbitMQ技术应对消息传送挑战 http://www.infoq.com/cn/presentations/Spring-RabbitMQ-technology
Base: An Acid Alternative In partitioned databases, trading some consistency for availability can lead to dramatic improvements in scalability. http://queue.acm.org/detail.cfm?id=1394128
案例分析:基于消息的分布式架构 http://www.infoq.com/cn/articles/message-based-distributed-architecture
中间件技术及双十一实践·消息中间件篇 http://jm-blog.aliapp.com/?p=3483
以上是关于整体介绍分布式事务的主要内容,如果未能解决你的问题,请参考以下文章