解密分布式事务框架-Fescar
Posted 咖啡拿铁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解密分布式事务框架-Fescar相关的知识,希望对你有一定的参考价值。
1.分布式事务
在去年的时候我写过一篇关于分布式事务的文章再有人问你分布式事务,把这篇扔给他。再这篇文章中我叫大家能不用分布式事务就别用分布式事务,因为会引入很多的复杂度。当时说这个的时候其实还有一个原因,没有大厂的成熟开源解决方案,虽然再网上有很多开源的分布式事务框架,但是都不是太成熟,没有大量的业务验证。它不像其他的分布式中间件有大量的成熟的解决方案,比如分布式消息队列中间件:Apache Kafka,Apache RocketMQ,Apache Pulsar这三个均是Apache顶级项目;又比如分布式任务调度,也有很多的开源比如XXL-JOB,Elastic-Job都是有很多的公司在使用。
而我们的分布式事务框架,却一直没有一个经过大量业务验证的框架。通过我的一些了解,其实各大公司都是有自己的分布式事务的解决方案,但很多时候都和业务上强耦合了,不适于做一些通用的框架。但是阿里在今年年初的时候给了大家一个惊喜,Fescar开源!从而让大家再以后选择分布式事务的时候多了一个选择方案,而且是经过成熟业务验证的方案。
这篇文章我会带大家认识Fescar,以及他的一些设计。后续的文章还会陆续推出Fescar的核心源码解析篇。
2.初识Fescar
说Fescar之前这里先简单的介绍一下著名的2PC:XA Transactions。
在XA协议中分为两阶段:
第一阶段:事务管理器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
第二阶段:事务协调器要求每个数据库提交数据,或者回滚数据。
优点: 尽量保证了数据的强一致,实现成本较低,在各大主流数据库都有自己实现,对于mysql是从5.5开始支持。
缺点:
单点问题:事务管理器在整个流程中扮演的角色很关键,如果其宕机,比如在第一阶段已经完成,在第二阶段正准备提交的时候事务管理器宕机,资源管理器就会一直阻塞,导致数据库无法使用。
同步阻塞:在准备就绪之后,资源管理器中的资源一直处于阻塞,直到提交完成,释放资源。
数据不一致:两阶段提交协议虽然为分布式数据强一致性所设计,但仍然存在数据不一致性的可能,比如在第二阶段中,假设协调者发出了事务commit的通知,但是因为网络问题该通知仅被一部分参与者所收到并执行了commit操作,其余的参与者则因为没有收到通知一直处于阻塞状态,这时候就产生了数据的不一致性。
只能用于单一类型数据库,跨数据库种类,其他缓存或者文件等资源不支持。
总的来说,XA协议比较简单,成本较低,但是其单点问题,以及不能支持高并发(由于同步阻塞)依然是其最大的弱点。
可以看见XA协议问题较多所以其作为分布式事务方案讨论的时候基本都会被无情的干掉,但是XA有个很好优点是对业务没有侵入(数据库层面),再业务上不需要编写额外的代码,更加关注业务。
在我的那篇文章中我又介绍了几种在应用层面上的分布式事务,但是或多或少的对业务都有一定的入侵。比如我们的TCC,常用的一些TCC框架都需要编写try,confirm,cancel等接口对于现成的业务需要进行转换。如果采用本地消息表模式那么又需要增加额外的表。如果采用事务性消息比如RocketMQ,会让一些没有使用该消息队列的业务需要更换消息队列。如果采用Saga模式,同样我们需要编写正向和反向接口。可以看见不论采用哪种分布式事务方案,都会有一定的业务改造,业务入侵成本。
而Fescar结合了XA的无侵入的优点和其他应用层事务协议高性能的优点,在应用层实现了二阶段协议的事务,同时对业务代码基本无侵入。
2.1 Fescar和XA
Fescar虽然是二阶段提交协议的分布式事务,但是其解决了上面XA的一些缺点:
单点问题:虽然目前Fescar(0.4.1)还是单server的,但是Fescar官方预计将会在0.5.x中推出HA-Cluster,到时候就可以解决单点问题。
同步阻塞:Fescar的二阶段,其再第一阶段的时候本地事务就已经提交释放资源了,不会像XA会再两个prepare和commit阶段资源都锁住,并且Fescar,commit是异步操作,也是提升性能的一大关键。
数据不一致:如果出现部分commit失败,那么fescar-server会根据当前的事务模式和分支事务的返回状态的结果来进行不同的重试策略。并且fescar的本地事务会在一阶段的时候进行提交,其实单看数据库来说在commit的时候数据库已经是一致的了。
只能用于单一数据库: Fescar提供了两种模式,AT和MT。在AT模式下事务资源可以是任何支持ACID的数据库,在MT模式下事务资源没有限制,可以是缓存,可以是文件,可以是其他的等等。当然这两个模式也可以混用。
同时Fescar也保留了接近0业务入侵的优点,只需要简单的配置Fescar的数据代理和加个注解,加一个Undolog表,就可以达到我们想要的目的。
3.Fescar总体设计
Fescar的设计核心就是他的角色分类。不论是数据库上的XA还是Fescar都有两个角色TM(事务管理器)和RM(资源管理器),同时Fescar还有一个TC(事务协调器)。我们先来看看如果没有TC,只有TM和RM会发生什么呢?这里我举个简单的例子,小明去网站上面购买了一个商品,如下图所示:
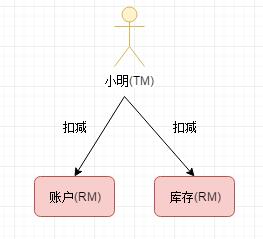
这里小明其实就是TM(事务管理器),而商品和账户其实就是我们的RM(资源管理器),正常情况下可能没问什么问题,账户和库存都能扣减成功。如果小明再扣减库存的时候成功但是在扣减账户的时候失败,这个时候就需要对我们的库存资源进行回滚。小明这个时候就会通知库存把上个阶段扣减的货物补回来。但是回滚库存的时候库存服务不稳定,这次回滚就失败了。一般来说小明会不断的去重试,直到成功。这样就有个问题小明就一直被阻塞,不能做任何事。这个也可以看做二阶段commit/rollback的时候一直会阻塞TM,网易DDB的XA协议针对这种情况会做一个异步线程的操作。但是在Fescar中一切都是由TC去做的,当然TC其实不仅仅会做二阶段失败的重试,他会做二阶段的所有RM的commit和rollback,让我们的TM做更少的事。
再Fescar中TM,RM,TC的关系如下面官方提供的图:
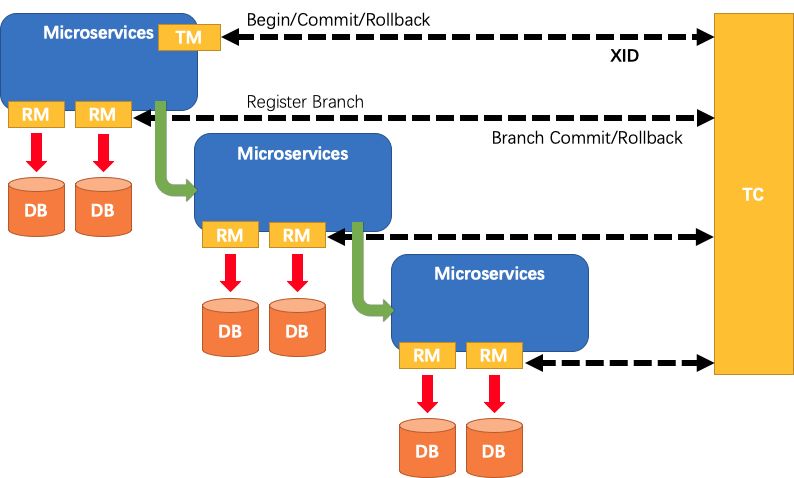
TM:事务的发起者。用来告诉TC,全局事务的开始,提交,回滚。
RM:具体的事务资源,每一个RM都会作为一个分支事务注册在TC。
TC:事务的协调者。也可以看做是Fescar-servr,用于接收我们的事务的注册,提交和回滚。
这三个角色的分工明确,正是我们Fescar真正的核心所在,下面我会通过如何使用Fescar带大家更加深刻的理解这三个角色。
4.快速开始Fescar
在Fescar的github上已经提供了一个简单的例子https://github.com/fescar-group/fescar-samples,这里我们需要将这个例子下载下来。
4.1搭建TC Fescar-server
首先我们搭建事务协调器,也可以叫做搭建Fescar-Server.官网的例子是使用Nacos加上fescar-server已经打好的Jar包运行的。这里为了方便我们直接下载fescar的代码https://github.com/alibaba/fescar。
找到我们的Server:
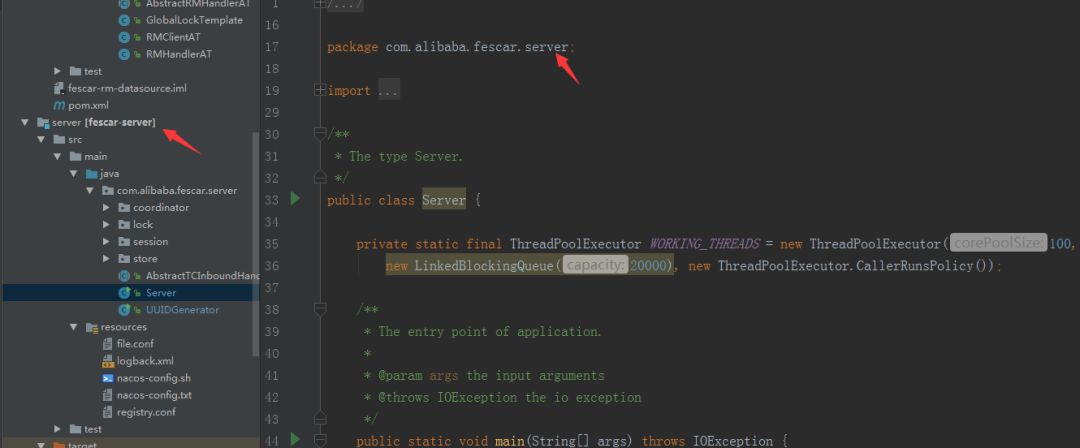
直接运行main方法,该方法会帮助我们在本地启动一个端口号为8091的fescar-server服务。如果我们想要进行服务注册,我们可以修改registry.conf下面的type
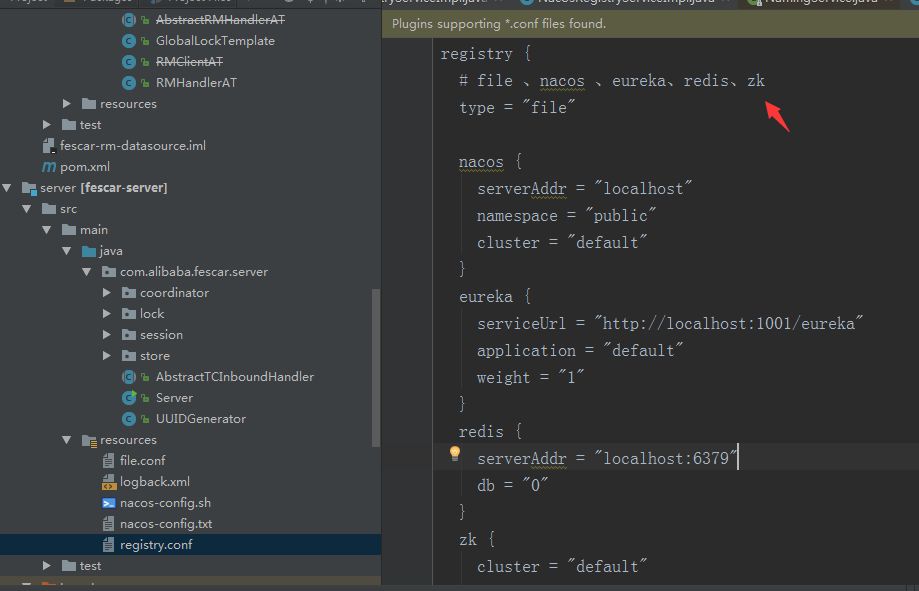
可以看见在0.4.1版本的时候支持四种服务注册,nacos,eureka,redis,zk。目前使用redis进行服务注册是有问题的,我也提了一个PR给官方进行修正。当然为了方便其实选择file,后续我们直连是最为便捷的。
再运行main方法之后,如果出现Server started日志,就代表我们的TC(事务协调器)成功启动。

4.2 认识TM
上面事务协调器已经搭建完成,我们接下来需要做的就是将TM和RM运行起来,将对应的操作交给我们的事务协调器去做。这个时候我们需要打开fescar-samples这个项目:由于这个项目使用的RPC是Dubbo,他默认配的服务注册中心是Nacos,需要我们再本地安装一个Nacos,具体安装可以自行搜索,这里不展开讲了。
这里官方例子中,业务关系如下图:
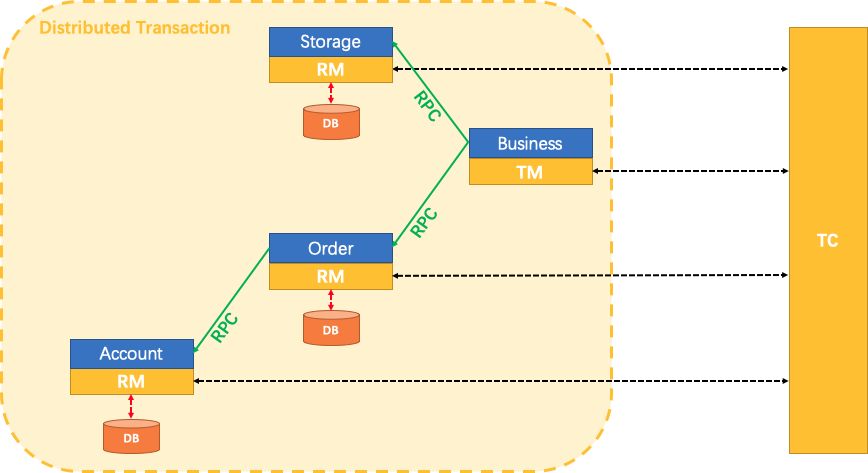
可以看见Business也就是我们的TM,找到对应的代码:
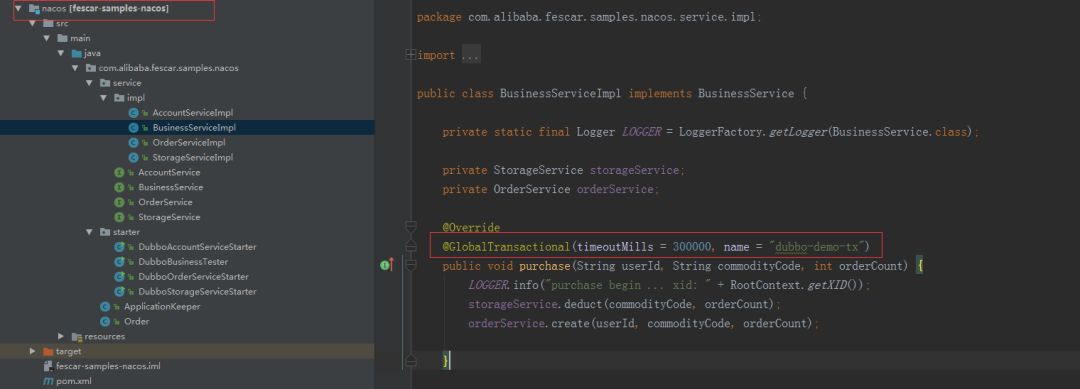
从代码中我们知道启动一个分布式事务是需要添加@GlobalTransactional注解的,当然Fescar也提供了API的方式让我们达到同样的效果。我们同时也需要修改registry.conf中的Type为file。
如果不是在例子中,而是在我们真正的业务上完全不需要修改业务代码,直接在我们分布式事务发起方添加上这个注解即可。
这个GloablTranscational注解到底做了什么呢?其实加了这个注解的都会走一个叫GlobalTransactionalInterceptor的切面,再这个切面中又会进入TrascationTemplate这个类中的excute方法,这个也是TM的核心方法:
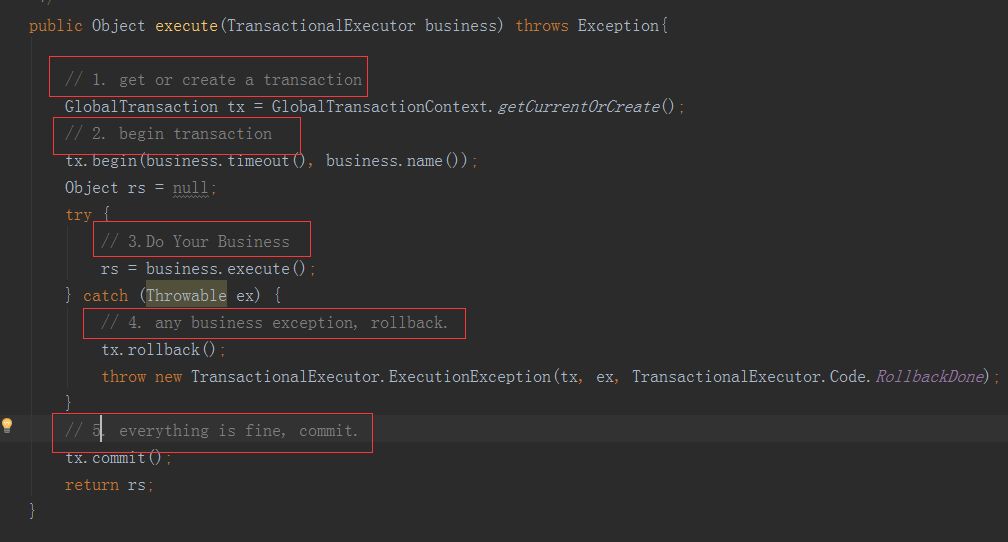
上面的代码有部分删减,只选取了核心的流程。TrascationTemplate其实也是Fescar提供给我们的API,如果不使用注解那么我们也可以模仿他的方式去做。可以看见主要分为五步:
获取当前上下文中是否已经有事务,这一步是通过ThreadLocal去实现的,如果有则获取当前的,如果没有则获取默认的。
开启事务,这一步是向TC(事务协调器)发出一个请求,注册一个GloabTranscation,这里的timeout是指超过这段时间没有rollback或者commit,TC会帮助我们做rollback。
做业务。
如果该方法抛出了异常,则回滚。这里要注意的时候抛出异常,很多时候我们会把异常给捕获,导致我们这里根本没有异常抛出,所以就不会出现回滚。这里的回滚也是向TC发起一个回滚请求,由他帮助我们对RM进行回滚。
如果没有异常则向TC发起commit,TC会帮助我们向RM异步发起提交请求。
TM的核心过程主要是这5步,其他详细的讲解会在后续的代码中体现。
4.3 认识RM
当我们上面的Business发起业务请求之后,就来到了我们RM的流程,我们的Storage和Order服务是怎么知道现在已经是处于分布式事务当中了呢?这个就需要借助RPC框架来完成了,这里我们使用的是Dubbo,fescar为dubbo提供了一个filter,如下图所示:
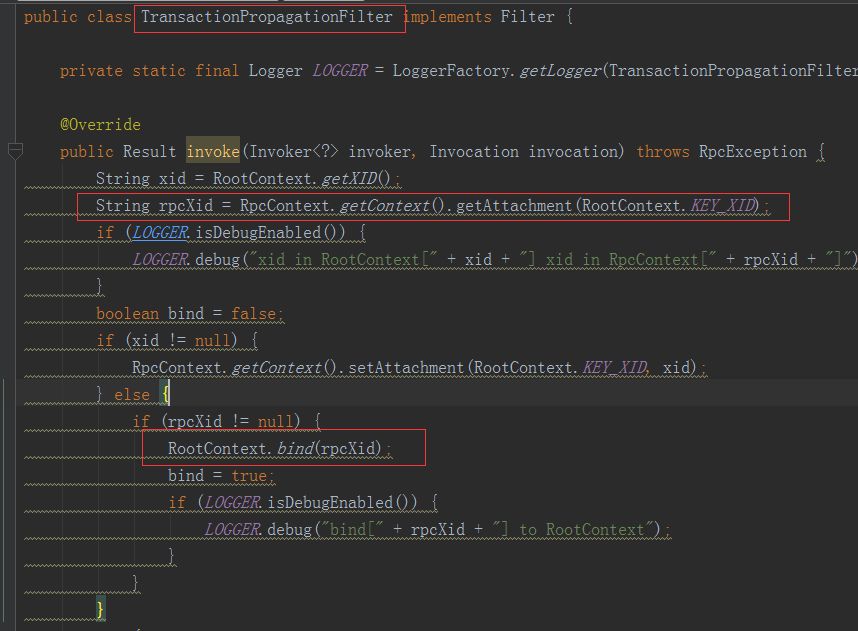
这里会从rpcContext中获取我们的xid,也就是我们的分布式事务ID,如果有的话就证明本次请求处于分布式事务中,那么就会把XID种入我们的RootContext(fescar的本地上下文)。如果你不是Dubbo,那么也可以根据此方法适配你的RPC。
在RM中我们应该做什么呢?只需要做下面两步:
将数据源换成Fescar代理

在当前数据库中添加一个Undolog的表,用于记录日志回滚。
再Fescar中不仅仅是对dataSource进行代理,也会对connection和statement进行代理,如下图:
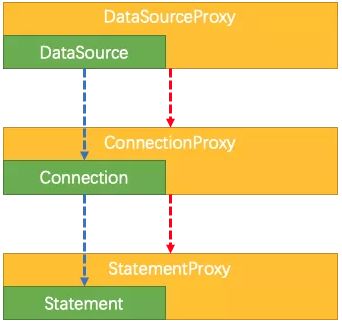
大家都知道我们的SQL的具体执行需要依赖Statement,在Fescar的StatementProxy中有如下代码:
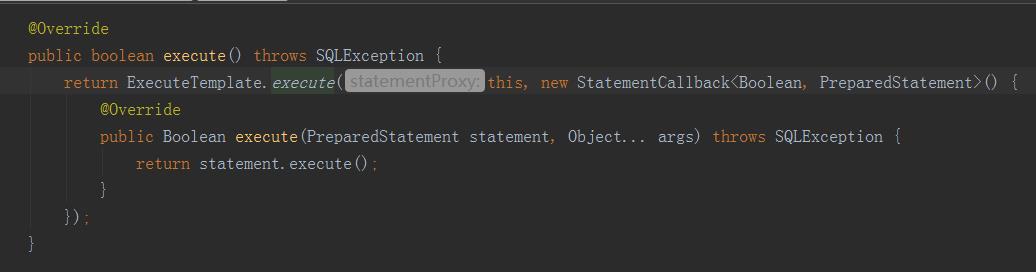
可以看见运行的方法是ExecuteTemplate.execute,在execute方法中会根据我们执行语句的类型记录我们的Undolog,具体的执行流程参考下面官方的一张图片:
总的来说我们的RM核心流程主要有两个:一个是如何识别分布式事务,另外一个是通过我们数据源代理让我们原本简单的执行SQL流程做了更多的事。
5.总结
写这篇文章的目的,不仅仅是让大家知道Fescar,也是让更多的人知道一个优秀分布式事务框架到底应该怎样去做。目前Fescar的版本号是0.4.1,还有很多功能比如HA-Cluster,SpringCloud集成还没有发布。所以目前再线上使用的话可能会遇到Fescar单点的问题,所以目前还不是太推荐线上使用。Fescar的目前规划会在0.5.x版本推出HA-Cluster,到时候其单点问题就会被解决。
这篇文章的原理目前介绍的比较粗浅,后面会陆续推出三篇文章详细介绍分析:TC,TM,RM,敬请期待。
如果大家觉得这篇文章对你有帮助,你的关注和转发是对我最大的支持,O(∩_∩)O:
参考文章
阿里开源分布式事务解决方案Fescar: https://mp.weixin.qq.com/s/TFGRcHV6EgeLB45OEJPRXw
以上是关于解密分布式事务框架-Fescar的主要内容,如果未能解决你的问题,请参考以下文章