分布式事务?No, 最终一致性 Posted 2021-04-25 码农沉思录
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务?No, 最终一致性相关的知识,希望对你有一定的参考价值。
一个简单操作,在服务端非常可能是由多个服务和数据库实例协同完成的。
在互联网金融等一致性要求较高的场景下,多个独立操作之间的一致性问题显得格外棘手。
基于水平扩容能力和成本考虑,传统的强一致的解决方案(e.g.单机事务)纷纷被抛弃。
其理论依据就是响当当的CAP原理。
我们往往为了可用性和分区容错性,忍痛放弃强一致支持,转而追求最终一致性。
大部分业务场景下,我们是可以接受短暂的不一致的。
这个时候一般都会去举一个例子:
A给B转100元。
当然,A跟B很不幸的被分在了不同的数据库实例上。
甚者这两个人可能是在不同机构开的户。
下面讨论基本都是围绕这个场景的。
更复杂的场景需要各位客官发挥下超人的想象力和扩展能力了。
谈到最终一致性,人们首先想到的应该是2PC解决方案。
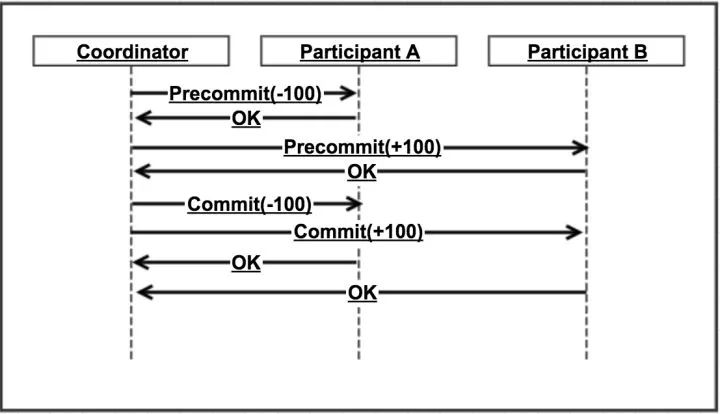
1. 两阶段提交
两阶段提交需要有一个协调者,来协调两个操作之间的操作流程。
当参与方为更多时,其逻辑其实就比较复杂了。
而参与者需要实现两阶段提交协议。
Pre commit 阶段需要锁住相关资源,
commit 或
rollback 时分别进行实际提交或释放资源。
看似还不错。
但是考虑到各种异常情况那就比较痛苦了。
举个例子:
如下图,执行到提交阶段,调用A的commit接口超时了,协调者该如何做?
我们一般会假设预提交成功后,提交或回滚肯定是成功的(由参与者保障)。
上述情况协调者只能选择继续重试。
这也就要求下游接口必须实现幂等(关于幂等的实现下面我们单独再讨论下)。
一般,下游出现故障,不是短时重试能解决的。
所以,我们一般也需要有定时去处理中间状态的逻辑。
这个地方,其实如果有个支持重试的MQ,可以扔到MQ。
在实践中,我们曾经也尝试自己实现了一个基于mysql
下面还会聊到这一点。
另外,我们也利用了一些外部重试机制。
比如支付场景,微信和支付宝都有非常可靠的通知机制。
我们在通知处理接口中做一些重试策略。
如果重试失败,就返回微信或支付宝失败。
这样第三方还会接着回调我们(怀疑他们可能发现了我厂回调成功率比其他商户要低^_^),不过作为小厂,利用一些大厂成熟的机制还是可取的。
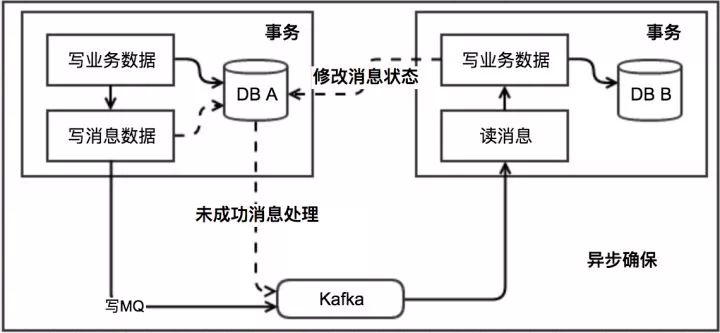
异步确保(没有事务消息)
“异步确保”这个词不一定是准确的,还没找到更合适的词,抱歉。
异步化不只是为了一致性,有时候更多的考虑响应时间,下游稳定性等因素。
本节只讨论通过异步方案,如何实现最终一致性。
该方案关键是要有个消息表。
另外,一般会有个队列,而且我们一般都会假设这个MQ不丢消息。
不过很不幸此MQ还不支持事务消息。
消息生产方,需要额外建一个消息表,并记录消息发送状态。
新增字段会跟业务强耦合,新增表处理起来不同交易数据可以通用处理。
不过因为消息表跟业务需要在一个事务里,所以存储耦合在所难免。
消息消费方,需要处理这个消息,并完成自己的业务逻辑。
此时如果本地事务处理成功,那发送给生产方一个
confirm 消息,表明已经处理成功了。
如果不支持,可以考虑把该消息放回队尾或另建一个队列特殊处理。
当然非要处理成功才能继续,那只能block在这条消息了(估计一般人不会这么做)。
Kafka lowlevel 接口是支持自己设置
offset 的,所以可以实现
block 。
生产方定时扫描本地消息表,把还没处理完成的消息由发送一遍。
如果有靠谱的自动对账补账逻辑,其实这一步也可以省略。
在实践中,丢消息或者下游处理失败这种场景还是非常少的。
这里要看业务上能不能容忍不一致到一个对账补账周期。
当然如果进一步简化,那么MQ也可以不要的。
直接用一个脚本处理,一些低频场景,也没啥大问题。
当然离线扫表这个事情,总让人不爽。
业务量不大且也出初期相信很多人干活儿这事儿。
另外,对一致性要求不高的或者有其他兜底方案的场景(比如较为频繁的对账补账机制),我们就不需要关心消息的
confirm 等情况,只要扔给消息,就认为万事大吉,一般也是可取的。
上面我们除了处理业务逻辑,还做了很多繁琐的事情。
把这些杂活儿都扔给一个中间件多好!
这就是阿里等大厂做的事务消息中间件了(比如Notify,RockitMQ的事务消息,请看下节)
异步确保(事务消息)
理想是:
我们只要把消息扔到MQ,那么这个消息肯定会被消费成功。
生产方不用担心消息发送失败,也不用担心消息会丢失。
回到现实,消费方,如果消息处理失败了,还有机会继续消费,直到成功为止(消费方逻辑bug导致消费失败情况不在本文讨论范围内)。
但遗憾的是市面上大部分MQ都不支持事务消息,其中包括看起来可以一统江湖的kafka。
RocketMQ 号称支持,但是还没开源(事务消息相关部分没开源)。
阿里云据说免费提供,没玩过(羡慕下阿里等大厂内部猿类们)。
不过从网上公开的资料看,用起来还是有些不爽的地方。
这是后话了,毕竟解决了很多问题。
事务消息,关键一点是把上小节中繁琐的消息状态和重发等用中间件形式封装了。
我厂目前还没提供成熟的支持事务消息的MQ。
下面以网传RMQ为例,说明事务消息大概是怎么玩的:
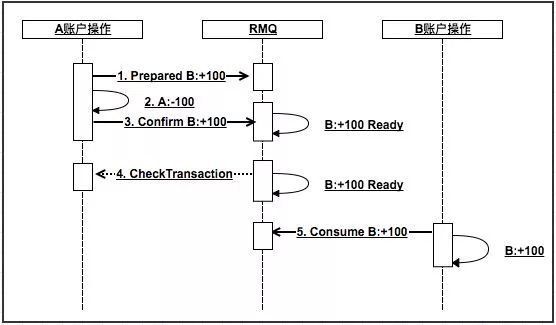
RMQ的事务消息相对于普通MQ,相当于提供了2PC的提交接口。
生产方需要先发送一个prepared消息给RMQ。
如果操作1失败,返回失败。
然后执行本地事务,如果成功了需要发送
Confirm 消息给RMQ。
2失败,则调用
RMQ cancel 接口。
别急,RMQ考虑到这个问题了。
RMQ会要求你实现一个check的接口。
生产方需要实现该接口,并告知RMQ自己本地事务是否执行成功(第4步)。
RMQ会定时轮训所有处于pre状态的消息,并调用对应的check接口,以决定此消息是否可以提交。
当然第5步也可能会失败。
这时候需要RMQ支持消息重试。
处理失败的消息果断时间再进行重试,直到成功为止(超过重试次数后会进死信队列,可能得人肉处理了,因为没用过所以细节不是很了解)。
支持消息重试,这一点也很重要。
消息重试机制也不仅仅在这里能用到,还有其他一些特殊的场景,我们会依赖他。
下一小节,我们简单探讨一下这个问题。
RMQ还是很强大的。
我们认为这个程度的一致性已经能够满足绝大部分互联网应用场景。
代价是生产方做了不少额外的事情,但相比没有事务消息情况,确实解放了不少劳动力。
P.S. 据说阿里内部因为历史原因,用
notify 比RMQ要多,他们俩基本原理类似。
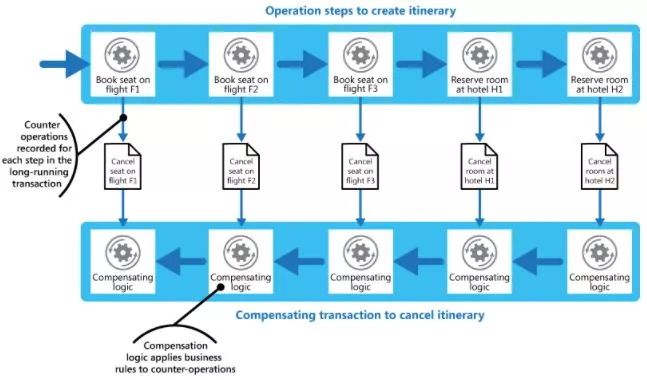
补偿交易(Compensating Transaction)
补偿交易,其核心思想是:针对每个操作,都要注册一个与其对应的补偿操作。
一般来说操作本身和其补偿(撤销)操作会在一个事务里完成。
当其后续操作失败后,需要按相反顺序完成前面注册的所有撤销操作。
跟2PC比,他的核心价值应该是少了锁资源的代价。
流程也相对简单一点。
但实际操作中,补偿操作不太好定义,其中间状态处理也会比较棘手。
比如A:-100(补偿为A:+100),
B:+100。
那么如果B:+100失败后就需要执行A:+100。
曾经有位大牛同事(也是我灰常崇拜的一位技术控)一直热衷于这个思路,相信有些场景用补偿交易模式也是个不错的选择。
他更多是不断思考如何让补偿看起来跟注册个单库事务一样简单。
做到业务无感知。
因为本人没有相关实战经验,所以留个链接在这里,供大家扩展阅读。
偷懒了,截个此文中的一张图。
消息重试
上面多次提到消息重试。
如果说事务消息重点解决了生产者和MQ之间的一致性问题,那么重试机制对于确保消费者和MQ之间的一致性是至关重要的。
重试可以是pull模式,也可以是push模式。
我厂目前已经提供push模式的消息重试,这个还是要赞一下的!
消息重试,重试顾名思义是要解决消息一次性传递过程中的失败场景。
举个例子,支付宝回调商户,然后商户系统挂了,怎么办?
答案是重试!
一般来说,消息如果消费失败,就会被放到重试队列。
如果是延迟时间固定(比如每次延迟2s),那么只需要按失败的顺序进队列就好了,然后对队首的消息,只有当延迟时间到达才能被消费。
这里会有个水位的概念。
如果按时间作为水位,那么期望执行时间大于当前时间的消息才是高于水位以上的。
其他消息对consumer不可见。
如果要实现每个消息延迟时间不一样,之前想过一种基于队列的方案是,按秒的维度建多个队列。
按执行时间入到不同的队列,一天86400个队列(一般丑陋)。
然后cosumer按时间消费不同队列。
之前做支付时候,做了个基于DB的延时队列。
每次消息进去时候,都会把下次执行时间设置一下。
再对这个时间做个索引....
略土,but it works。
毕竟失败的消息不该很多,所以DB容量也不用太在意。
很多时候,能跑起来的,简单的架构会得到更多人喜爱。
我厂提供了一种基于redis的延时队列,可以支持消息重试。
用到的主要数据结构是redis的zset,按消息处理时间排序。
当然实现起来也没说的那么简单。
MQ遇到的持久化问题,内存数据丢失问题,重试次数控制,消息追溯等等都需要有一些额外的开发量。
综上,如果MQ能够提供消息重试特性,那就不要自己折腾了。
这里还是有不少坑的。
幂等(接口支持重入)
即使没有MQ,重试也是无处不在的。
所以幂等问题不是因为用到MQ后引入的,而是老问题。
如果是单条insert操作,我们一般会依赖唯一键。
如果一个事务里包含一个单条insert,那也可以依赖这条insert做幂等,当insert抛异常就回滚事务。
如果是update操作,那么状态机控制和版本控制异常重要。
这里要多加小心。
再复杂点的,可以考虑引入一个log表。
该log对操作id(消息id?
)进行唯一键控制。
然后整个操作用事务控制。
当插入log失败时整个事务回滚就好了。
有人会说先查log表或者利用redis等缓存,加锁。
我想说的是这个基本上都不work。
除非在事务里进行查寻。
所以建议,所幸让代码简单点,直接插入,依赖数据库唯一键冲突回滚掉就好了。
用唯一键挡重入是目前为止个人觉得最有安全感的方式。
当然对数据库会有一些额外性能损耗。
问题就变成了有多大的并发,其中又有多大是需要重试的?
我相信Fasion IO卡+分库分表之后,想达到数据库性能瓶颈还是有点难度的(主要是针对金融类场景)
本文略虚,当然目前最终一致性没有一个放之四海而皆准的成功实践。
需要大家根据不同的业务特性和发展阶段,选则适当的方式来实现。
纠结最终一致性问题,其实万恶之源是因为RPC本身会失败,会有结果不确定的情况。
隐约感觉本人职业生涯大部分时间都会跟各种失败和timeout搏斗了。
本文重点讨论利用MQ实现最终一致性。
主要原因有:
1. 目前市面上的MQ都相对非常强大,几乎都号称可以做到不丢数据。
相信未来对事务消息应该也会更加普及。
2. 异步化几乎是不同处理能力(响应时间、吞吐量)和稳定性(99.99%的服务依赖99.9%的服务)的服务之间解耦的毕竟之路。
当然前面的讨论还很浅显。
能力有限,希望能够不断完善此文,请各位看到的客观不吝赐教。
以上是关于分布式事务?No, 最终一致性的主要内容,如果未能解决你的问题,请参考以下文章