排序算法—— 希尔排序快速排序
Posted Java面经
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了排序算法—— 希尔排序快速排序相关的知识,希望对你有一定的参考价值。
今天还是给小伙伴们介绍两种排序算法
希尔排序又称缩小增量排序,是1959年由D.L.Shell提出来的。
算法描述:
1)先取定一个小于 n 的整数 gap1 作为第一个增量,把整个序列分成 gap1 组。所有距离为 gap1 的倍数的元素放在同一组中,在各组内分别进行排序(分组内采用直接插入排序或其它基本方式的排序)。
2)然后取第二个增量gap2<gap1,重复上述的分组和排序。
3)依此类推,直至增量gap=1,即所有元素放在同一组中进行排序为止。
简单来说:
就好像上体育课,大家乱糟糟的站在一起,老师让大家排成一排然后按照1~4 (gap1)报数,让数到同一个数字的同学按大小个排序,排完之后在按1~3报数,然后重复上面的排序规则~嗯~这样子解释是不是就好理解多了呢~
代码:
算法分析:
开始时 gap 的值较大, 子序列中的元素较少, 排序速度较快。
随着排序进展, gap 值逐渐变小, 子序列中元素个数逐渐变多,由于前面大多数元素已基本有序, 所以排序速度仍然很快。
分组后n值减小,n²更小,而T(n)=O(n²),所以T(n)从总体上看是减小了。
Gap的取法有多种。 shell 提出取 gap = n/2 ,gap = gap/2 ,…,直到gap = 1。gap若是奇,则gap=gap+1
当然希尔排序是一种优化的思想,要是小伙伴们理解不了也没关系~知道有这种方法了解一下就好~
算法特点:
以某个记录为界(该记录称为支点或枢轴),将待排序列分成两部分:
①一部分: 所有记录的关键字大于等于支点记录的关键字
②另一部分: 所有记录的关键字小于支点记录的关键字

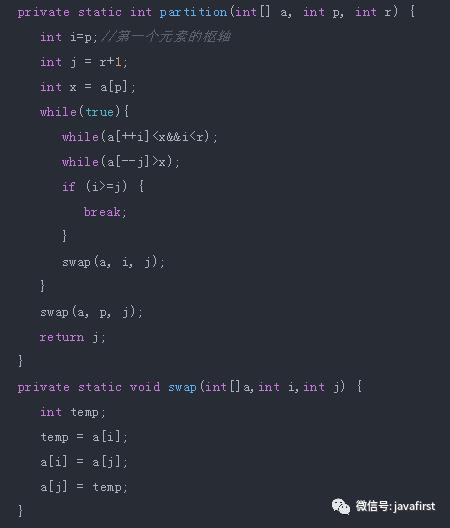
算法分析:
快速排序是一个递归过程,快速排序的趟数取决于递归树的高度。
如果每次划分对一个记录定位后, 该记录的左侧子序列与右侧子序列的长度相同, 则下一步将是对两个长度减半的子序列进行排序, 这是最理想的情况。
算法评价
时间复杂度:
最好情况(每次总是选到中间值作枢轴)T(n)=O(nlogn)
最坏情况(每次总是选到最小或最大元素作枢轴)T(n)=O(n²)
空间复杂度:需栈空间以实现递归
最坏情况:S(n)=O(n)
一般情况:S(n)=O(logn)
可以证明,快速排序算法在平均情况下的时间复杂性和最好情况下一样,也是O(nlogn),这在基于比较的算法类中算是快速的,快速排序也因此而得名。
快速排序算法的性能取决于划分的对称性。因此通过修改partition( )方法,可以设计出采用随机选择策略的快速排序算法,从而使期望划分更对称,更低概率出现最坏情况。
因此,可在原划分方法中加入如下代码进行优化:
要是一次看不懂代码也不要着急~
先试着理解一下算法的思想
再来看看代码
以上是关于排序算法—— 希尔排序快速排序的主要内容,如果未能解决你的问题,请参考以下文章