(算法三)高级排序(希尔排序和归并排序 )
Posted Android架构师成长之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(算法三)高级排序(希尔排序和归并排序 )相关的知识,希望对你有一定的参考价值。
高级排序
之前我们学习过基础排序,包括冒泡排序,选择排序还有插入排序,并且对他们在最坏情况下的时间复杂度做了分析,发现都是O(N^2),而平方阶通过我们之前学习算法分析我们知道,随着输入规模的增大,时间成本将急剧上升,所以这些基本排序方法不能处理更大规模的问题,接下来我们学习一些高级的排序算法,争取降低算法的时间复杂度最高阶次幂。
1.希尔排序
希尔排序是插入排序的一种,又称“缩小增量排序”,是插入排序算法的一种更高效的改进版本。
前面学习插入排序的时候,我们会发现一个很不友好的事儿,如果已排序的分组元素为{2,5,7,9,10},未排序的分组元素为{1,8},那么下一个待插入元素为1,我们需要拿着1从后往前,依次和10,9,7,5,2进行交换位置,才能完成真正的插入,每次交换只能和相邻的元素交换位置。那如果我们要提高效率,直观的想法就是一次交换,能把1放到更前面的位置,比如一次交换就能把1插到2和5之间,这样一次交换1就向前走了5个位置,可以减少交换的次数,这样的需求如何实现呢?接下来我们来看看希尔排序的原理。
需求:
排序前:{9,1,2,5,7,4,8,6,3,5}
排序后:{1,2,3,4,5,5,6,7,8,9}
排序原理:
1.选定一个增长量h,按照增长量h作为数据分组的依据,对数据进行分组;
2.对分好组的每一组数据完成插入排序;
3.减小增长量,最小减为1,重复第二步操作。
增长量h的确定:增长量h的值每一固定的规则,我们这里采用以下规则:
int h=1
while(h<5){
h=2h+1;//3,7
}
//循环结束后我们就可以确定h的最大值;
h的减小规则为:
h=h/2



希尔排序的时间复杂度分析
在希尔排序中,增长量h并没有固定的规则,有很多论文研究了各种不同的递增序列,但都无法证明某个序列是最好的,对于希尔排序的时间复杂度分析,已经超出了我们课程设计的范畴,所以在这里就不做分析了。
我们可以使用事后分析法对希尔排序和插入排序做性能比较。
在资料的测试数据文件夹下有一个reverse_shell_insertion.txt文件,里面存放的是从100000到1的逆向数据,我们可以根据这个批量数据完成测试。测试的思想:在执行排序前前记录一个时间,在排序完成后记录一个时间,两个时间的时间差就是排序的耗时。

2.2 归并排序
2.2.1 递归
正式学习归并排序之前,我们得先学习一下递归算法。
定义:
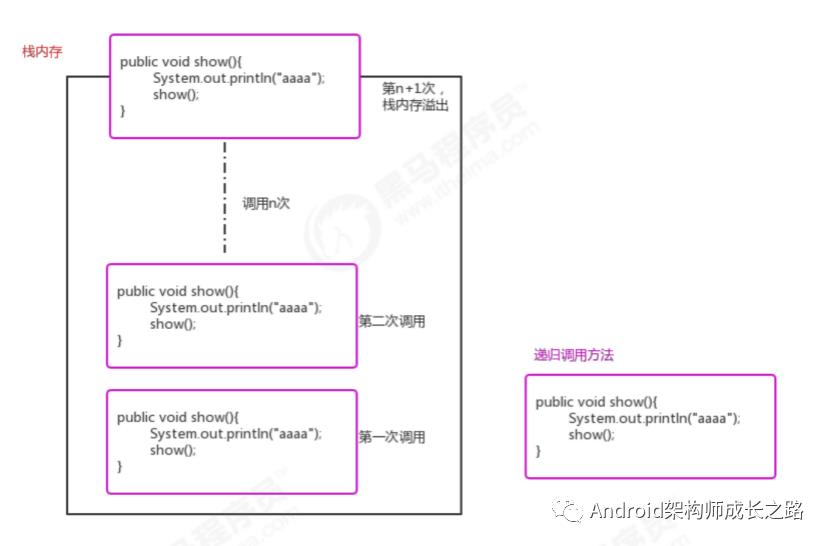
定义方法时,在方法内部调用方法本身,称之为递归.
public void show(){
System.out.println("aaaa");
show();
}
作用:
它通常把一个大型复杂的问题,层层转换为一个与原问题相似的,规模较小的问题来求解。递归策略只需要少量的程序就可以描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。
在递归中,不能无限制的调用自己,必须要有边界条件,能够让递归结束,因为每一次递归调用都会在栈内存开辟 新的空间,重新执行方法,如果递归的层级太深,很容易造成栈内存溢出。
需求:
请定义一个方法,使用递归完成求N的阶乘;
代码实现:
分析:
1!: 1
2!: 2*1=2*1!
3!: 3*2*1=3*2!
4!: 4*3*2*1=4*3!
...
n!: n*(n-1)*(n-2)...*2*1=n*(n-1)!
所以,假设有一个方法factorial(n)用来求n的阶乘,那么n的阶乘还可以表示为n*factorial(n-1)
代码实现:

2.2.2 归并排序
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
需求:
排序前:{8,4,5,7,1,3,6,2}
排序后:{1,2,3,4,5,6,7,8}
排序原理:
1.尽可能的一组数据拆分成两个元素相等的子组,并对每一个子组继续拆分,直到拆分后的每个子组的元素个数是1为止。
2.将相邻的两个子组进行合并成一个有序的大组;
3.不断的重复步骤2,直到最终只有一个组为止。
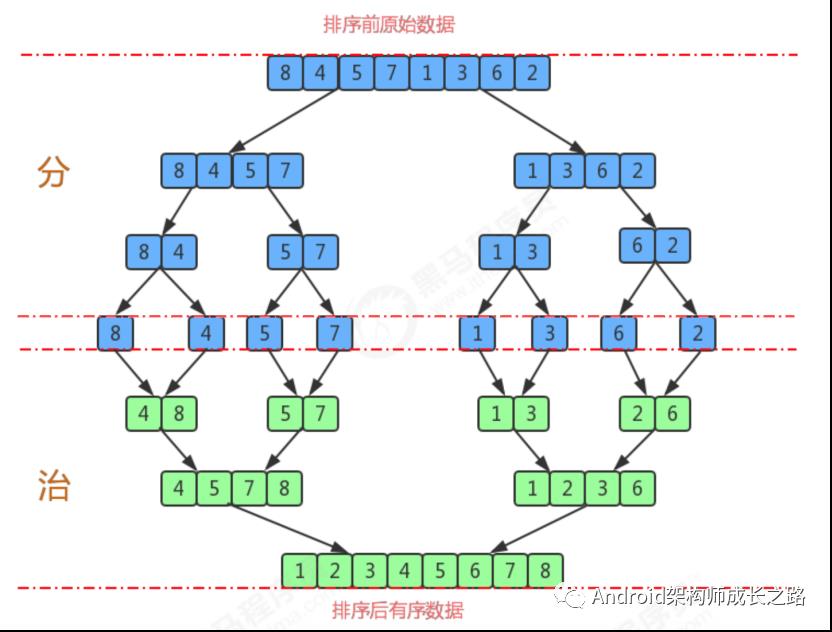

归并原理:
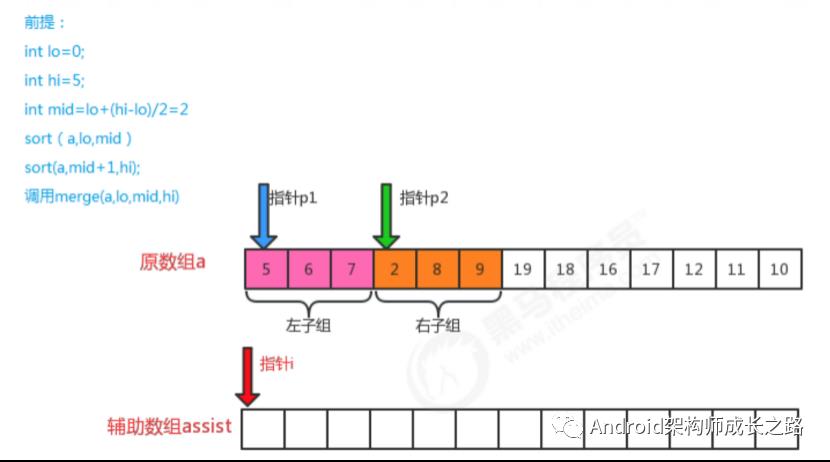
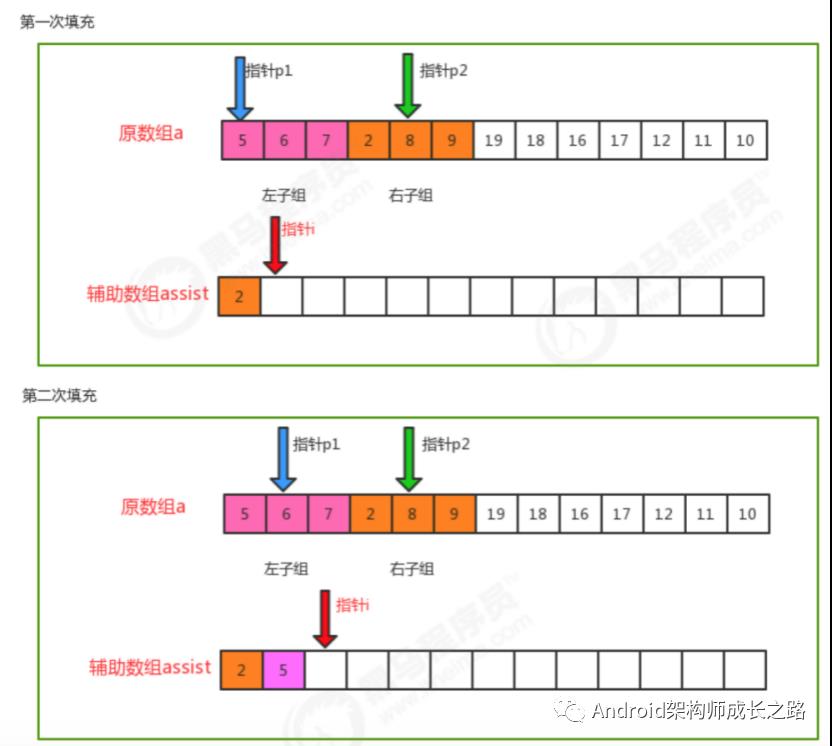
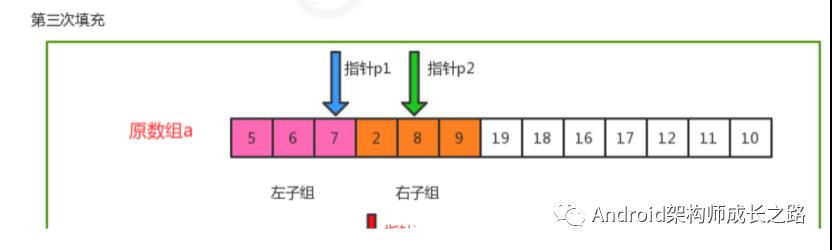

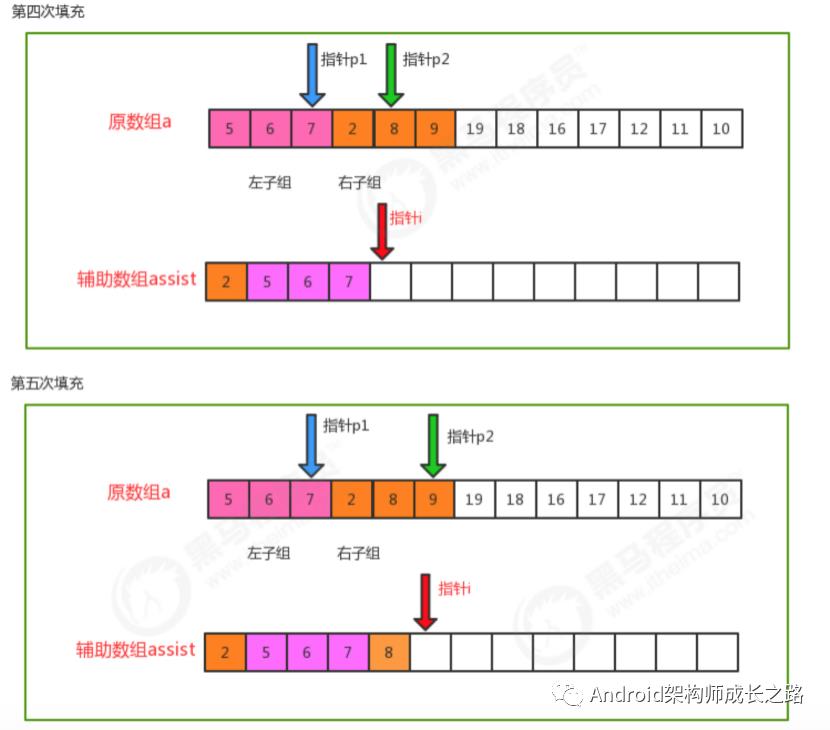
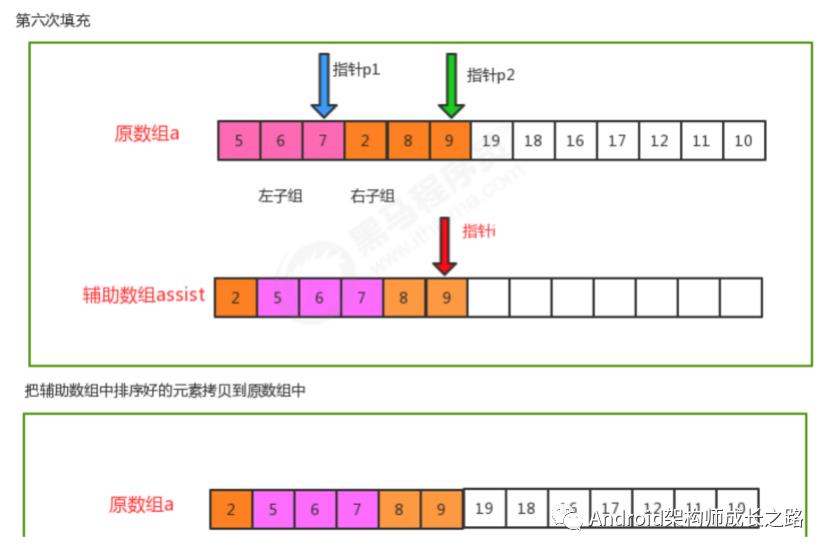
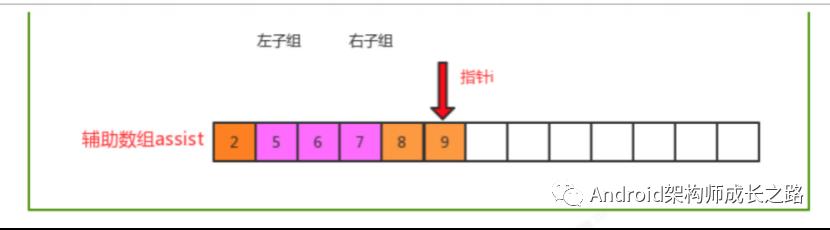



归并排序时间复杂度分析:
归并排序是分治思想的最典型的例子,上面的算法中,对a[lo...hi]进行排序,先将它分为a[lo...mid]和a[mid+1...hi] 两部分,分别通过递归调用将他们单独排序,最后将有序的子数组归并为最终的排序结果。该递归的出口在于如果 一个数组不能再被分为两个子数组,那么就会执行merge进行归并,在归并的时候判断元素的大小进行排序。
用树状图来描述归并,如果一个数组有8个元素,那么它将每次除以2找最小的子数组,共拆log8次,值为3,所以 树共有3层,那么自顶向下第k层有2^k个子数组,每个数组的长度为2^(3-k),归并最多需要2^(3-k)次比较。因此每层的比较次数为 2^k * 2^(3-k)=2^3,那么3层总共为 3*2^3。
假设元素的个数为n,那么使用归并排序拆分的次数为log2(n),所以共log2(n)层,那么使用log2(n)替换上面3*2^3中的3这个层数,最终得出的归并排序的时间复杂度为:log2(n)*2^(log2(n))=log2(n)*n,根据大O推导法则,忽略底数,最终归并排序的时间复杂度为O(nlogn);
归并排序的缺点:
需要申请额外的数组空间,导致空间复杂度提升,是典型的以空间换时间的操作。
归并排序与希尔排序性能测试:
之前我们通过测试可以知道希尔排序的性能是由于插入排序的,那现在学习了归并排序后,归并排序的效率与希尔排序的效率哪个高呢?我们使用同样的测试方式来完成一样这两个排序算法之间的性能比较。
在资料的测试数据文件夹下有一个reverse_arr.txt文件,里面存放的是从1000000到1的逆向数据,我们可以根据这个批量数据完成测试。测试的思想:在执行排序前前记录一个时间,在排序完成后记录一个时间,两个时间的时间差就是排序的耗时。
希尔排序和插入排序性能比较测试代码:
通过测试,发现希尔排序和归并排序在处理大批量数据时差别不是很大。
以上是关于(算法三)高级排序(希尔排序和归并排序 )的主要内容,如果未能解决你的问题,请参考以下文章