经典排序希尔排序
Posted xuanxuan丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了经典排序希尔排序相关的知识,希望对你有一定的参考价值。
希尔排序
简介:
希尔排序,英文Shell's sort,是一位叫D.L.Shell的老哥在1959就提出来的算法,是《》的一种又称“缩小增量排序”(Diminishing Increment Sort),其实就是是直接插入排序算法的一种更高效的改进版本。
希尔排序是非稳定排序算法。
原理:
大的原理跟《》原理一样,都是后一位跟前一位比较大小,后一位小的就交换位置。
优化在于,这里增加了一个叫“增量”的东西,其实就是分组的大小,然后每次开始,先把所有数组分成 “增量m” 个分组,当然每个分组的大小是增量n/m。然后每次增量m除以2,直到最后为1(整个数组)结束。
思路:
这里假设开始设置一个增量n/2,
将所有数据分组,每组就是2个数(n为偶数的话),分组个数就是n/2个,n是数组长度。
然后这个几个分组在组内进行插入排序。
增量m=m/2,也就是分组数量减半,合并了,继续在变大了的分组进行插入排序。
重复步骤②③④,知道最后m=1,也就是只有一个分组,所有元素在一组,进行一次插入排序。
结束。
上图上图↓
示例数组[1,10,35,61,89,36,55,44]
第一轮,初始增量8除以2,为4
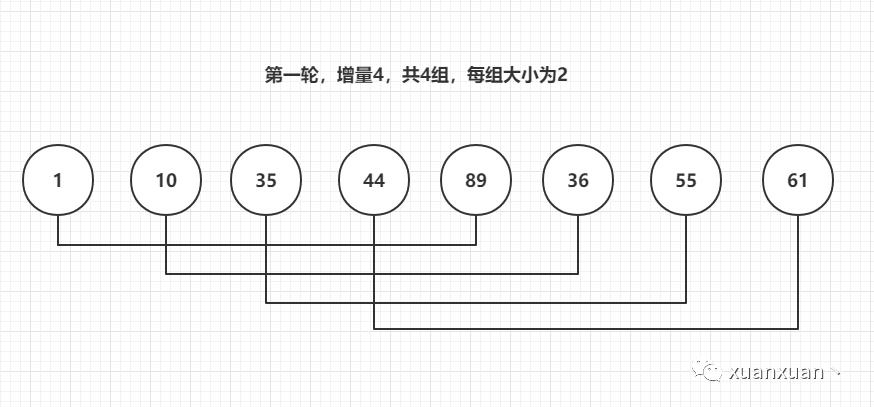
第一轮后数组[1,10,35,44,89,36,55,61]
第二轮增量4除以2,为2
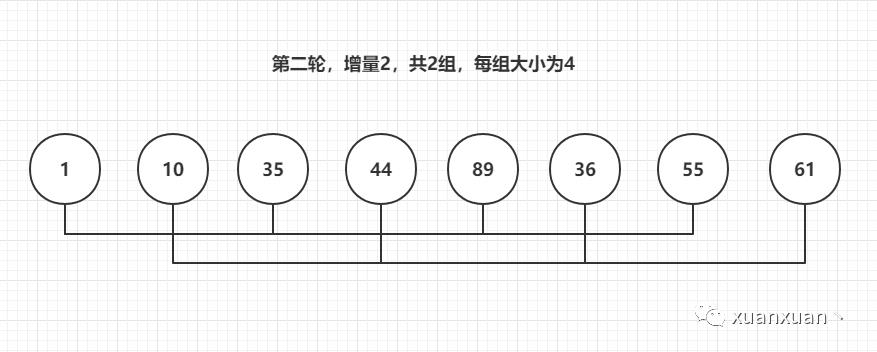
第二轮后数组[1,10,35,36,55,44,89,61]
第三轮增量2除以2,为1
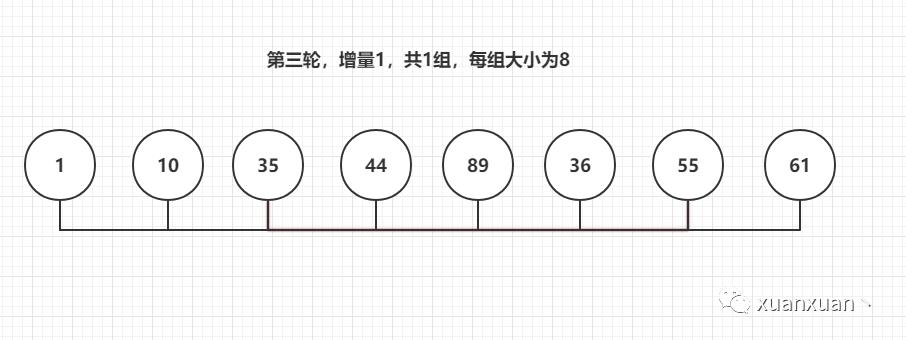
最后数组[1,10,35,36,44,55,61,89]。
表格形式展示↓
代码:
public static void sort3(int[] a) {//增量int gap = a.length;do {gap /= 2; //增量每次减半for (int i = 0; i < gap; i++) {// 插入排序for (int j = i; j < a.length; j += gap) {int k;int t = a[j];for (k = j; k - gap >= 0 && t < a[k - gap]; k -= gap) {a[k] = a[k - gap];}a[k] = t;}}} while (gap != 1);}
算法分析:
稳定性:
由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序。但是上面排序也可以看出,分组分轮进行排序的时候,不同的轮中相同的数,就可以发生次序变化,前后互换,最后其稳定性就会被打乱,所以shell排序是不稳定的。
时间复杂度:
希尔排序是基于插入排序的一种算法, 在此算法基础之上增加了一个新的特性,提高了效率。希尔排序的时间的时间复杂度为O(n^(3/2)),希尔排序时间复杂度的下界是n*log2n。希尔排序没有快速排序算法快 O(n(logn)),因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比O(n²)复杂度的算法快得多。并且希尔排序非常容易实现,算法代码短而简单。
此外,希尔算法在最坏的情况下和平均情况下执行效率相差不是很多,与此同时快速排序在最坏的情况下执行的效率会非常差。专家们提倡,几乎任何排序工作在开始时都可以用希尔排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法. 本质上讲,希尔排序算法是直接插入排序算法的一种改进,减少了其复制的次数,速度要快很多。原因是,当n值很大时数据项每一趟排序需要移动的个数很少,但数据项的距离很长。当n值减小时每一趟需要移动的数据增多,此时已经接近于它们排序后的最终位置。正是这两种情况的结合才使希尔排序效率比插入排序高很多。
Shell算法的性能与所选取的分组长度序列有很大关系。
空间复杂度:
O(1),跟插入排序一样,是一个原地排序算法。
总结:
希尔排序是按照不同步长对元素进行插入排序,当刚开始元素很无序的时候,步长最大,所以插入排序的元素个数很少,速度很快;当元素基本有序了,步长很小,插入排序对于有序的序列效率很高。所以,希尔排序的时间复杂度会比o(n^2)好一些。
我预两副棺材,一副你的一副我的
以上是关于经典排序希尔排序的主要内容,如果未能解决你的问题,请参考以下文章