58金融的CSRF防御实践
Posted 58技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了58金融的CSRF防御实践相关的知识,希望对你有一定的参考价值。
导读
防范CSRF攻击对于互联网企业来说意义重大,本文结合58金融的实践场景,旨在帮助大家共同提高nodejs服务的安全性。
背景
<img src=” https://hellobank.com/transfer/money/to/?accountId=6225&money=100” />常见认知误区
开发规则
我们在众多实际项目中总结出如下6条规则。
规则1:get请求无需防御CSRF攻击。
按照HTTP语义来说,get请求仅用于查询,不能用于提交信息。也就是说任何一个get请求,都不应该导致后端业务状态及业务数据的变化。攻击者一定是希望通过CSRF攻击造成后端业务数据的变化,如发帖购物转账等,没有变化也就无需防御。(接口防恶意刷数的除外,不在本文的讨论范围)
该规则虽看似简单,实际开发中却常被接口制定者所忽略。在实际开发中我们见到很多开发中使用get请求提交信息,或者更为隐蔽的漏洞是,虽然get请求没有提交任何信息,但却导致了后端服务状态或数据库数据发生了改变。因此该规则的重点在于后端同学正确理解HTTP语义和定义前后端接口。
规则2:不携带业务cookie的请求无需防御
这条规则看似简单,但往往最容易被开发人员所忽略。CSRF的攻击者一定是希望冒用受害者的身份,通常更准确的术语是cookie,去发送某些请求到服务器以达到攻击者的目的。但如果受害者连业务cookie都没有的话,说明服务器根本不认识该受害者,攻击者的目的也就无法实现了。换句话理解:用户都没登录,不为系统识别,模拟他没有任何收益。(接口防恶意刷数的除外,不在本文的讨论范围)
举个例子,新闻网站的列表页和详情页,一般都开放给所有人查看。攻击者诱使其他非登录用户访问某个新闻页面,没有收益且不会导致新闻网站后台的业务和状态数据改变,因此一般来讲无需防范。(当然如果考虑到点击量和曝光率、广告费的话也有必要防御,这些不在本文讨论范围)
规则3:URL白名单里的post请求无需防范
规则4:浏览器端发送post请求时,为header添加csrf参数,其值由业务cookie计算得出
规则5:服务器端收到post请求时,检查其业务cookie及header中的csrf是否正确匹配
为什么最后这俩条规则要放一起呢?因为这俩条规则是CSRF防御的技术核心,前后端代码配合一起作用,才能防御CSRF攻击。单独仅前端或后端防御肯定行不通。
首先,为什么要给请求增加header呢?因为受害者在访问邪恶网页时,受害者向我们的服务器所发出的请求,该请求和邪恶网页的域名一定是不同的,这也是CSRF中的Cross-Site的含义。因此受到跨域的限制,攻击者无法改变该请求的任何信息,特别是受害者的业务cookie值。
所以我们在浏览器端,给合法用户请求的header上加上csrf的参数,并且该参数的值由业务cookie计算得出。如此则攻击者无法事先知道受害者的cookie,也就无法计算出header的csrf参数。
然后在服务器端获取业务cookie以及header中的csrf值进行匹配校验,一致则认为是有效请求,不一致则认为是CSRF攻击进行拦截。
规则6:可以使用专门的CSRF cookie替换业务cookie,但要保证cookie足够随机、无法被预测
针对某些网站,其业务cookie因安全原因或其他历史原因设置为httponly,导致JavaScript无法读取。此时我们需要在nodejs端生成一个可以被JavaScript读取的cookie,专门负责处理CSRF逻辑。
具体实现
上述规则可以用如下代码逻辑实现(代码仅供逻辑展示,均已脱敏仅供参考)。
这里我们选用了koa2,将判断逻辑抽象成一个函数,返回true时代表截获到了CSRF攻击。
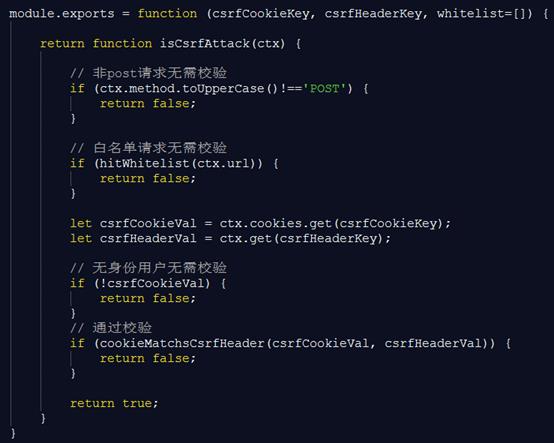
这里可以根据业务需要,适当拓展防御措施,如根据CSRF攻击的频次考虑增加校验码流程,或对IP进行限制。此处不做详述。
以上是关于58金融的CSRF防御实践的主要内容,如果未能解决你的问题,请参考以下文章