一种混合式聚焦爬虫框架:有效检索Surface Web和Dark Web中的特定内容
Posted MottoIN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一种混合式聚焦爬虫框架:有效检索Surface Web和Dark Web中的特定内容相关的知识,希望对你有一定的参考价值。
摘要
人们常用的搜索引擎(如Google、Bing、Yahoo或Duckduckgo等)只能够对万维网上仅有的一小部分网页进行索引,对于深网或暗网中的内容,一般的搜索引擎无法访问,由于存在种种限制(如:为响应具体的查询生成动态页面、隐私内容需要私人授权等),常规的网络爬虫技术也难以抓取暗网中的内容。
本文介绍一种混合爬虫技术,它能够自动完成某一指定的主题的Web资源检索,这个过程中涉及到整个Web页面链接结构的自动导航,以及通过预测与主题相关的链接来获取所推荐的超链接。该爬行框架的显著特征是:它是一种通用的爬行框架,能够无缝地浏览表面网站(Surface Web)和现有的一些暗网(如:Tor,I2P,和Freenet)站点,用于发现表面网站和暗网上的任意主题的web资源。每次爬行过程中都会自动调整爬行行为,其分类指导的超链接选择策略是基于目标网络的类型和一个超链接与所选主题的关联性(即证据强度)而定的。我们一共研究了11种超链接选择方法,基于链接和父网页分类器的动态线性组合提出了一种新的超链接选择方法,实验该爬虫框架对表面网络和暗网都是有效的。
研究背景
在过去10年中,宽带服务迅速普及,随着网上存储资源的日趋丰富以及互联网应用的不断扩展,因特网的使用量大大增加,信息共享呈现全局扩散模式,这种变化为人类许多不同的领域和学科的发展带来了非凡的意义,然而,我们也应当看到,它同时也带来了新的威胁。极端组织和恐怖组织利用互联网作为沟通渠道,招募新成员、激励老成员、传播潜在的颠覆性的内容,包括制造自制爆炸物信息(HMEs)和简易爆炸装置(IED)的知识,策划和实施暴力和恐怖行为等。
在这种情况下,对执法机构在网络上及时搜索并获取恐怖活动相关的最新消息提出了挑战。调查人员一般集中在表面网络进行信息的搜索,然而,利用传统的搜索引擎只能索引一小部分可用的Web信息;其余的、更多更有价值的信息都被转移到了暗网中,无法利用传统的方法检索到。由于进入这些地下网络存在一定的技术限制,针对暗网的Web爬行技术也更具挑战性。
由于暗网的独特性和网站托管的波动性(通常情况下,托管暗网Web内容的机器并非是保持24/7正常运行的),传统的搜索引擎不能索引这些地下网络的内容;只有一小部分稳定的搜索工具能够检索暗网中的部分网页(如ahmia4、torch5)。要知道,暗网的本质是不允许提供一个可靠的搜索引擎的。寻找暗网入口点最有效的方法是利用目录列表,也称为隐藏的维基(hidden wikis)或隐藏的服务列表(hidden service lists),这些页面上发布一些暗网中托管的站点信息,主要用于广告推广,基于站点主题进行关联分类,大多数与非法活动(例如,HMEs、武器、恐怖主义、儿童色情、贩卖人口和毒品)有关。这些提供d目录列表的站点不仅托管在感兴趣的地下网络,有几个库还托管在表面网站。同时,地下网络并非孤岛,它们与外部世界保持着一种连接。有种情况是很常见的,即一个托管在暗网中的站点上包含的超链接指向其他暗网站点或表面网站。表面网站和暗网之间、不同的暗网站点之间互联互通,这表明,至少在理论上,能够开发出一种可以穿越表面网站和不同类型的暗网的爬虫框架。
在这种背景下,本文提出了一种新的爬虫框架。该爬虫框架在超链接的选择上遵循三种不同的分类模式:
一种基于链接的分类器:考虑到本地环境中的超链接,即锚文本、周围的文字和每个超链接的URL的条款;
一种父网页分类器:基于全局上下文考虑,评估一个父页面中的超链接与感兴趣主题的相关性;
目标网页分类器:利用全局上下文语境,产生页面上超链接的相关性;
相关工作
这种新型的混合式聚焦爬虫框架通过自动遍历web架构图的基础上选择性的抓取与给定主题相关的网络资源。具体的过程概述如下:首先定义一组与感兴趣主题相关的种子Web页面(即爬行的起始点),并将它们添加到未被爬行下载的web页面的URL列表中,从这个列表中逐个读取页面包含的超链接,选择那些最可能与主题相关的其他网页,随后将每个选定的超链接添加到未被爬行下载的URL列表中,不断迭代地重复此过程,直到满足预定的终止规则(如,获取到了所需的页数,或达到爬行深度的限制)。
预测未访问过的网页的相关性是一个具有挑战性的任务,对此聚焦爬虫框架采用基于监督机器学习方法的分类器引导的爬行策略,它依赖于两种证据来源来选择要获得相关Web资源的超链接:一种是超链接的本地上下文语境;一种是超链接的全局上下文语境。
与此同时,对暗网的爬虫也开发完成,这类爬虫可以在Tor网络中执行索引,同时能够隐藏其身份(即具有匿名性),这对进一步监视和检查暗网起到了重要作用。由于需要提取和分析隐藏服务上承载的内容,因而建立了一个能够基于每个资源的可达性调整其行为的智能网络爬虫。朝着这个方向进一步的研究,提出了一个集中的爬行系统,在人类适当辅助的情况下,能够访问暗网中极端隐蔽的站点。最终,为了分析暗网中隐藏服务的内容和研究最流行的内容类别,开发出了一个Tor网络爬虫。
需要说明的是,混合式的聚焦爬行方法除了针对Tor网络爬行外,还能够索引Surface Web和其他地下网络(如I2P和Freenet)的内容。该爬行框架基于超链接的目的地网络类型和/或围绕超链接的本地上下文环境中的关联强度,能够自动调整其行为和链接选择策略。
在项目进展过程中,小组成员主要尝试了针对恐怖主义活动相关的Web资源的发现和挖掘。为了研究和理解恐怖主义和极端主义现象而进行的链接和内容分析,所需的多语言文本资料和网络挖掘工具主要由亚利桑那大学的暗网项目提供。
此外,对暗网中的信息进行收集和分析的方法已应用于一组圣战网站,目的是协助相关机构对情报收集工作,提高对恐怖主义和极端主义活动的了解。
混合爬虫架构
该混式聚焦爬虫能够穿越表面网站和一些地下网络(如Tor、I2P和Freenet),完成自适应的爬行行为。该爬行方法的概述图如下所示:
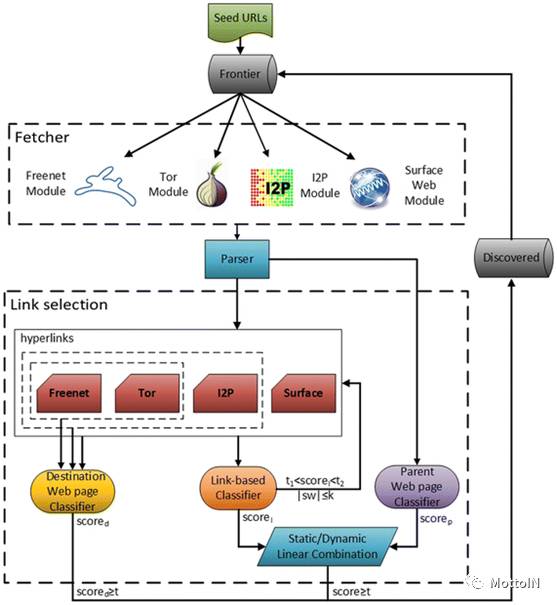
上文已经介绍过,它使用了三种不同的分类器:基于链接的分类器、父网页分类器和目标网页分类器,这三种分类器的超链接选择策略不同。混合式聚焦爬虫架构中,可以分别使用、也可以组合使用这三种分类器,当满足一定条件时,也可以一起使用。
框架的优势
待抓取的URL列表中在爬行过程中会不断的迭代更新,基于超链接的选择策略添加新的未访问过的URL。支持所有在地下网络中遇到的不同类型的网址(Tor,I2P,和Freenet),以及表面网络上的Web URL。
爬虫组件
为了支持从表面网站和地下网站抓取网页内容,需要配置适当的爬虫组件。
每种地下网络都需要利用适当的服务才能够进行网络资源的访问,具体来说,访问Tor隐藏服务需要配置Tor服务组件,抓取托管在I2PTunnel “服务器”上的i2p网页需要配置I2P服务;抓取分布在一个或多个Freenet节点上的freesite页面时需要使用Freenet代理。为此,爬行框架的抓取组件由四个独立的读取模块组成,分别负责处理抓取表面网络、Tor网络、I2P网络和Freenet网络上web内容时所需的服务。
爬行过程中,根据网络类型自动识别并区分URLs(即Surface Web,Tor,I2P,和Freenet URLs),然后转发给相应的提取模块,以便下载对应的Web资源的内容。此外,爬虫组件采用人类辅助性(human-assisted accessibility)方法获取需要人工登录认证的网站上的网页。启用此操作的前提条件是首先获取感兴趣站点的有效的用户名和密码,并将其插入到爬虫的配置文件中。自动登录过程将生成的有效cookie存储在每一个感兴趣的Web站点上,每次提交一个Web页面的新请求(作为特定Web站点的一部分)时,都会重新发送它。混合式聚焦爬虫框架不仅能够处理表面网络和地下网络的单个页面抓取,也能够解决它们之间可能存在的关联性问题。

以上是关于一种混合式聚焦爬虫框架:有效检索Surface Web和Dark Web中的特定内容的主要内容,如果未能解决你的问题,请参考以下文章