Python Scrapy爬虫框架学习0
Posted 小小时光记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python Scrapy爬虫框架学习0相关的知识,希望对你有一定的参考价值。
1. Scrapy 教程
我们会有以下的几个任务:
创建一个scrapy项目
创建一个爬虫来爬取网站并获取数据
修改爬虫来爬取递归的链接
1.1 创建一个scrapy项目
在自己的项目文件夹下面,使用脚本命令: scrapy startproject jiufunews,则会创建一个项目文件夹jiufunews。
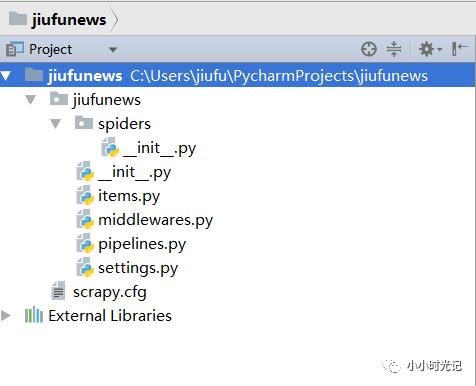
项目文件的目录层级如下:
scrapy.cfg # 项目的items定义文件
middlewares.py # 项目中间件信息
pipelines.py # 项目管道信息文件
settings.py # 项目设置文件
spiders/ # 爬虫文件夹,爬虫的实现方法等文件将放在这个文件夹下面
1.2 爬虫的实现
当项目创建完毕以后,新建一个文件并命名为jiufunews,并复制如下代码。以下的代码为爬取玖富官网中的新闻信息,元素拾取器为使用xpath。
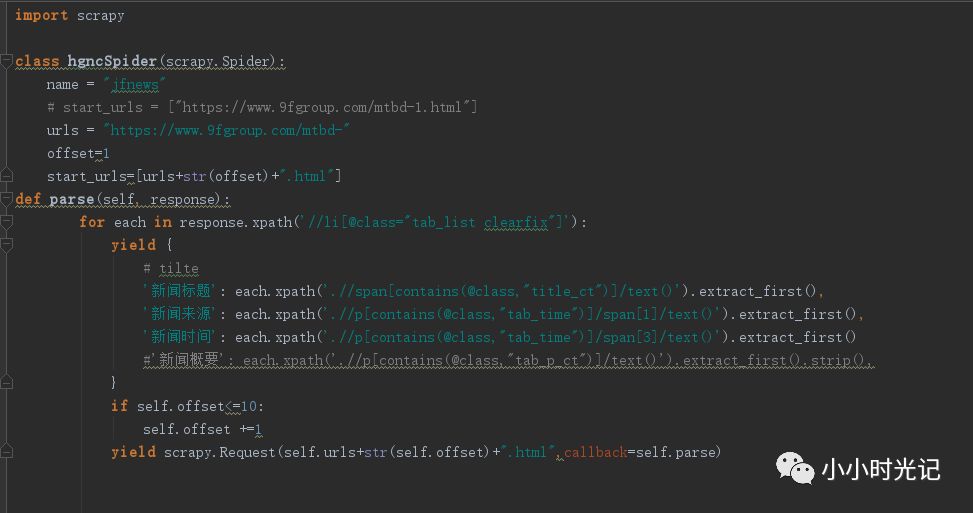
步骤1:定义爬虫的名字(名字唯一性)
步骤2:定义爬虫需要爬取的URL
步骤3:使用Parse方法去实现爬虫
步骤4:查看html页面,可以看见我们需要爬取的元素都是在//li[@class="tab_list clearfix"]'元素下面,所以对这个标签进行遍历
步骤5:使用url中的if循环进行url的拼接自增长获取翻页的数据
其中对于数据的获取,需要使用selector 的拾取器,可以使用css或者xpath来进行拾取。下本以xpath为例
'新闻时间': each.xpath('.//p[contains(@class,"tab_time")]/span[3]/text()').extract_first()
代表的含义为在当前标签下(<li class="tab_list clearfix>)下,寻找class=tab_time的p标签,对其下的第三个span标签获取其文本信息。
1.3 URL遍历
定义两个变量offset & urls,在循环完成第一个URL后自增量offset字段,并通过urls变量来进行拼接行程翻页的数据追踪,遍历完成第N个URL的爬虫。
1.4 运行程序
新建Python文件begin,并复制代码,因pycharm IDE中不支持直接的运行程序,只能以嵌入cmd命令行的形式实现运行。(有别的方法??)
from scrapy import cmdline
cmdline.execute("scrapy crawl jfnews".split())
运行程序即可查看爬取的信息。
以上的程序基本上可以完成对大多数页面的信息抓取,比如学校的新闻内容、工作列表、论坛信息等。
下一步将进行学习xpath的更复杂HTML数据清洗和数据的加载与保存。
以上是关于Python Scrapy爬虫框架学习0的主要内容,如果未能解决你的问题,请参考以下文章