初识python爬虫框架Scrapy
Posted 小小爬虫师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识python爬虫框架Scrapy相关的知识,希望对你有一定的参考价值。
Scrapy,按照其官网(https://scrapy.org/)上的解释:一个开源和协作式的框架,用快速、简单、可扩展的方式从网站提取所需的数据。
我们一开始上手爬虫的时候,接触的是urllib、requests抑或是Selenium这样的库,这些库都有非常好的易用性,上手很快,几行代码就能实现网页的批量爬取。但是当我们的爬虫越来越大、越来越复杂时,这个时候,框架式的爬虫就可以发挥它的威力了,这其中python爬虫领域最著名的开源框架便是scrapy。其版本目前已更新到了1.6.
认识一个库都是从看官方文档开始的,scrapy的官方文档就写得很精致,甚至比网上大多数博客中片段的上手文章要好很多,小爬建议各位都跟着官方文档走一遍:https://doc.scrapy.org/en/latest/。当然,中文的scrapy网站也建议各位参考,网站内提供了很多简单的实例:http://www.scrapyd.cn/。
scrapy的安装非常方便:pip install Scrapy。pip会方便地给我们安装scrapy和它需要的所有依赖包,除了有些慢。如果您会科学上网,那么这些就都不算问题。
小爬我电脑用的win10专业版,直接使用PowerShell就可以方便查看scrapy。
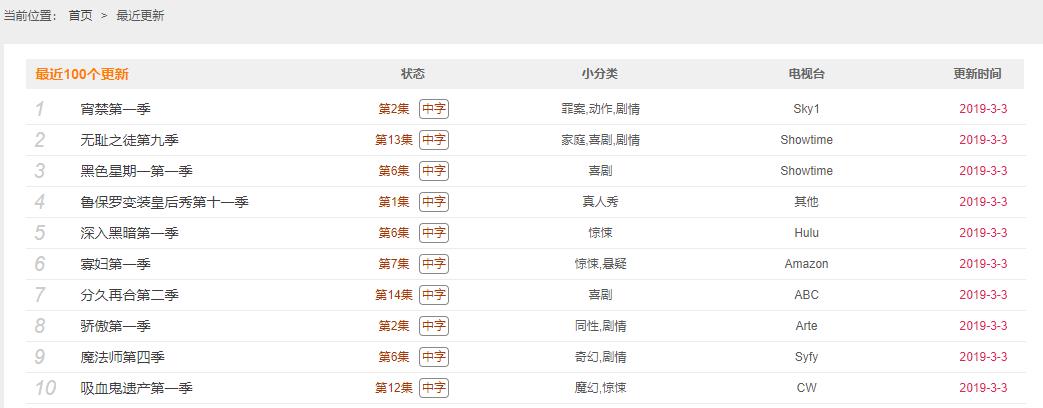
我们不妨写个简单的爬虫,从爬取美剧天堂“最近100个更新”开始,网页如下:https://www.meijutt.com/new100.html
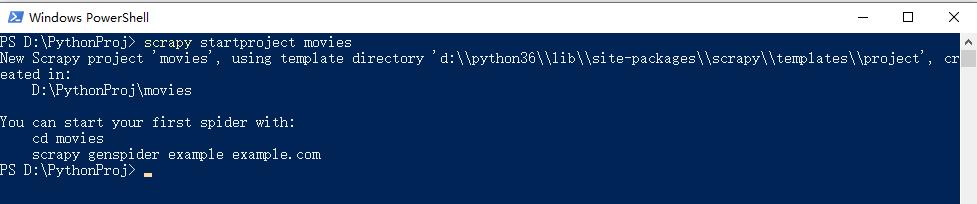
1、首先,新建一个项目:scrapy startproject movies
2、然后 在powershell中使用CD movies切换到对应的项目文件夹下,再新建自己的爬虫:scrapy genspider [options] <name> <domain>
我们暂且使用默认的模板(template)创建爬虫:scrapy genspider meiju meiju.com

3、将文件夹导入Visual studio code,可以看到整个工程项目的文件夹结构如下:
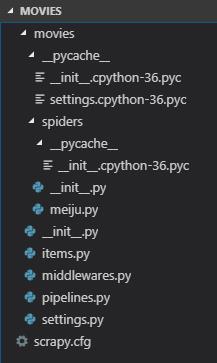
这些模块具体的作用可以详见其结构图:
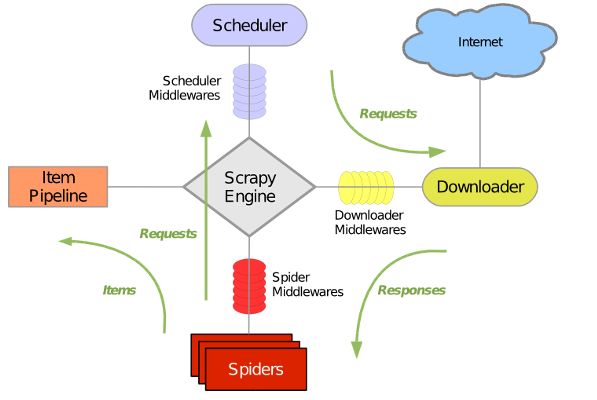
引擎、下载器、爬虫、调度器、管道,结合各类中间件,利用twisted异步框架,实现多线程爬取。
4、首先修改Items.py文件,定义要爬取的字段,即数据存储的模板:默认代码如下图所示:
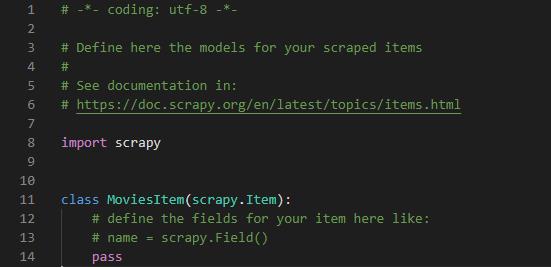
比如,我们要获取美剧天堂该页面下的“名称”和“分类”字段,可以这样定义item:
import scrapy
class MoviesItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() #名称
classification=scrapy.Field() #分类
框架自动生成的爬虫脚本代码如下:
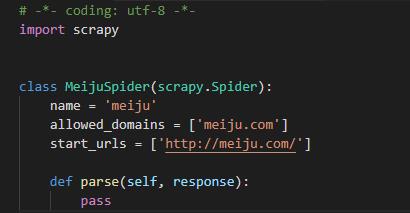
5、改写meiju.py这个爬虫文件,修改默认的start-urls属性,实现parse解析方法:
首先需要导入items下的MovieItem类,且实例化对象:
# -*- coding: utf-8 -*-
import scrapy
from movies.items import MoviesItem
class MeijuSpider(scrapy.Spider):
name = 'meiju'
allowed_domains = ['meijutt.com']
start_urls = ['https://www.meijutt.com/new100.html']
def parse(self, response):
movies=response.xpath('//ul[contains(@class,"top-list") and contains(@class,"fn-clear")]/li') #用xpath对网页返回的response对象进行解析
for each_movie in movies:
item=MovieItem() #实例出item对象
item['name']=each_movie.xpath('./h5/a/@title').extract()[0] #提起name字段
item["classification"]=each_movie.xpath('./span[2]/text()').extract_first() #提取classification字段
yield item #返回item,并交由pipeline管道处理
默认的pipeline.py管道文件如下:
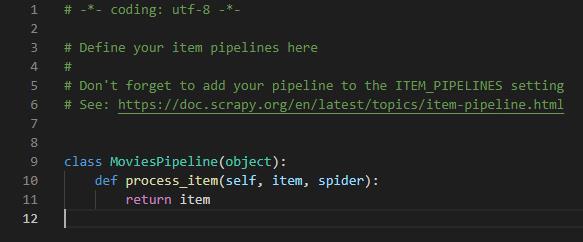
6、我们需要实现process_item方法来处理movies.py文件返回的每一个item,比如导出到txt文件:
注意:process_item()是必须要实现的方法,被定义的Item Pipeline会默认调用这个方法对Item进行处理。比如,我们可以进行数据处理或者将数据写入到数据库等操作。它必须返回Item类型的值或者抛出一个DropItem异常。
如果它返回的是Item对象,那么此Item会被低优先级的Item Pipeline的process_item()方法处理,直到所有的方法被调用完毕。
from movies.items import MoviesItem #导入items中的MoviesItem类
class MoviesPipeline(object):
def process_item(self, item, spider):
with open("D:\\myMovie.txt","a") as fp:
fp.write(item['name']+'\t'+item['classification']+"\n")
return item
其中,ITEM_PIPELINES是一个字典文件,键为要打开的ItemPipeline类,值为优先级(0-1000),ItemPipeline是按照优先级来调用的,值越小,优先级越高。
8、最后,运行爬虫:scrapy crawl meiju,过程如下:
得到的txt文件如下所示:
一个简单的scrapy爬虫项目就此大功告成!
以上是关于初识python爬虫框架Scrapy的主要内容,如果未能解决你的问题,请参考以下文章
Python | 边学边敲边记第四次:初识爬虫框架Scrapy