aiohttp高并发爬虫框架
Posted Bert的理想国
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了aiohttp高并发爬虫框架相关的知识,希望对你有一定的参考价值。
aiohttp高并发爬虫框架
前言
今天在突然想起了崔庆才书上的一个aiohttp框架,然后就探究了一下,aiohttp官方解释是:Asynchronous HTTP Client/Server for asyncio and Python.就是一个python的异步框架,属于非堵塞式的框架,和requests模块比较相似但是也有巨大区别。requests模块属于堵塞式的模块,堵塞式和非堵塞式的区别就在于,堵塞式是只有一个请求完一个url之后完成所有的操作才会去继续请求第二个url,而非堵塞式是请求完第一个url之后立刻会去请求第二个url,而不是等待io完成之后再去请求第二个url,这就大大的增大了爬取的效率。今天就是使用aiohttp爬取一下新闻网做一个实战,在下一期可能会做一个使用aiohttp做压力测试。
准备
python3.5+(asyncio在3.5之后才有)
aiohttp(使用pip安装)
案例
使用aiohttp爬取新闻网站新闻实战:
1.安装aiohttp框架
pip intsall aiohttp
2.网站分析
(1)分析需要获取的内容
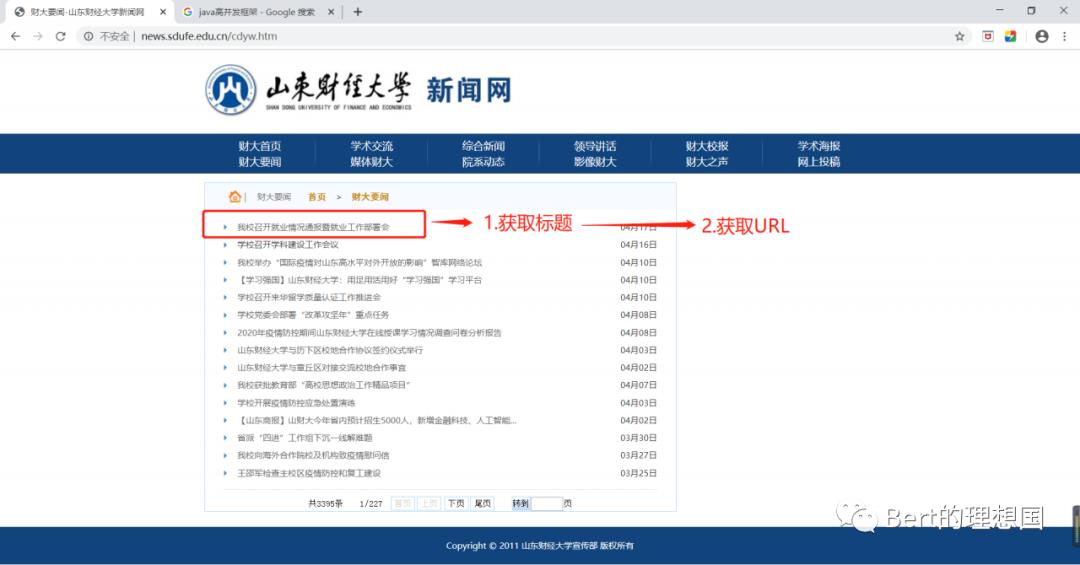
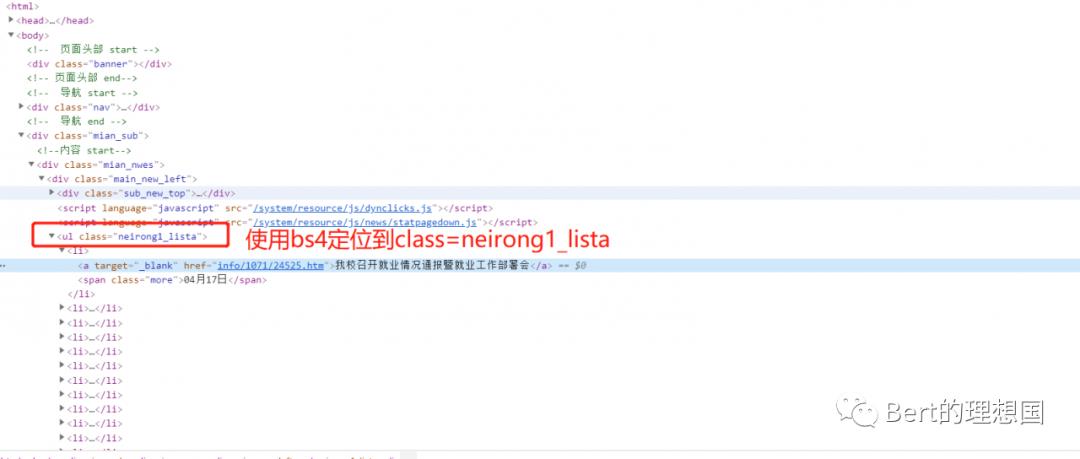
(2)元素审查
代码部分
import aiohttp
import asyncio
from bs4 import BeautifulSoup
import time
import requests
'''
@author:Bert_fk
@project:aiohttpTest
'''
urls=[]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
url='http://news.sdufe.edu.cn/cdyw/{}.htm'
#使用aiohttp框架,异步发起请求,获得网页源码
async def getData(url,headers):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
response=await response.text()
return response
#抽取数据
def extract_elements(data):
soup=BeautifulSoup(data,'lxml')
ul_list=soup.select('ul[class="neirong1_lista"] li')
a_list=soup.select('ul[class="neirong1_lista"] a')
print(ul_list)
return a_list
#构造url
def conUrl():
#urls.add(url.format(i) for i in range(89,54,-1))
urls=[url.format(i) for i in range(225,1,-1)]
return urls
#aiohttp主方法
async def main():
url_len=conUrl()
for s in range(0,len(url_len)):
extract_elements(await getData(url_len[s],headers))
start=time.clock()
loop=asyncio.get_event_loop()
#asyncio.ensure_future(main())
loop.run_until_complete(main())
end=(time.clock()-start)
print("aiohttp请求所用时间:"+str(end))
效果展示
总结
aiohttp在爬取信息方面也是比较好用的,在某些方面使用起来优于requests模块。
以上是关于aiohttp高并发爬虫框架的主要内容,如果未能解决你的问题,请参考以下文章