简单使用scrapy爬虫框架批量采集网站数据
Posted 青灯编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单使用scrapy爬虫框架批量采集网站数据相关的知识,希望对你有一定的参考价值。
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
本篇文章就使用python爬虫框架scrapy采集网站的一些数据。
基本开发环境
Python 3.6
Pycharm
如何安装scrapy
在cmd 命令行当中 pip install scrapy 就可以安装了。但是一般情况都会出现网络超时的情况。
例如:
pip install -i https://mirrors.aliyun.com/pypi/simple/ scrapy清华:https://pypi.tuna.tsinghua.edu.cn/simple阿里云:http://mirrors.aliyun.com/pypi/simple/中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/华中理工大学:http://pypi.hustunique.com/山东理工大学:http://pypi.sdutlinux.org/豆瓣:http://pypi.douban.com/simple/
你可能会出现的报错:
在安装Scrapy的过程中可能会遇到缺少VC++等错误,可以安装缺失模块的离线包
Scrapy如何爬取网站数据
本篇文章以豆瓣电影Top250的数据为例,讲解一下scrapy框架爬取数据的基本流程。
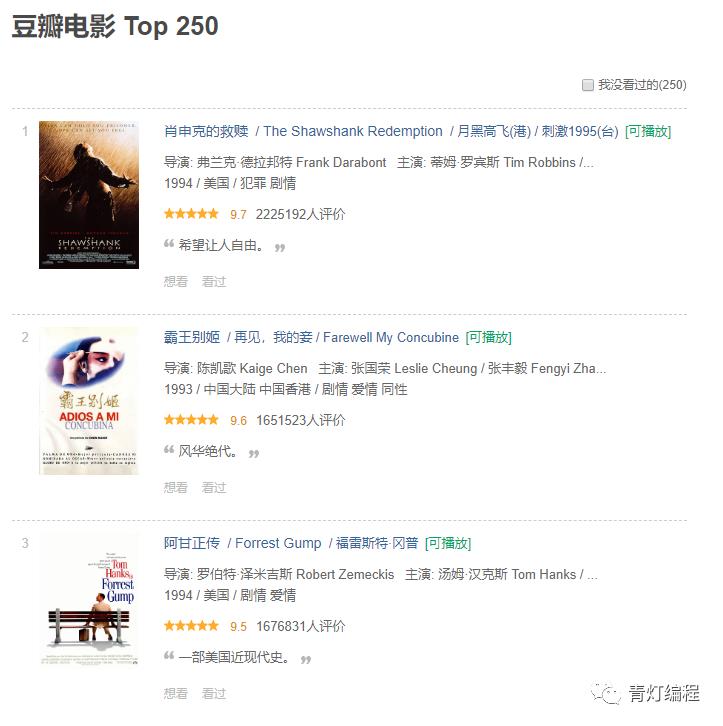
豆瓣Top250 这个数据就不过多分析,静态网站,网页结构十分适合写爬取,所以很多基础入门的爬虫案例都是以豆瓣电影数据 以及猫眼电影数据为例的。
Scrapy的爬虫项目的创建流程
1.创建一个爬虫项目
在Pycharm中选择 Terminal 在 Local 里面输入
scrapy startproject +(项目名字<独一无二>)

2.cd 切换到爬虫项目目录
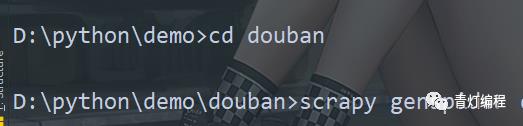
3.创建爬虫文件
scrapy genspider (+爬虫文件的名字<独一无二的>) (+域名限制)

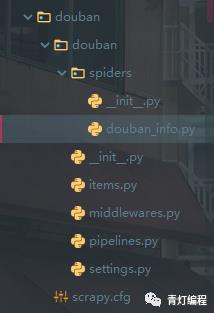
这就对于scrapy的项目创建以及爬虫文件创建完成了。
Scrapy的爬虫代码编写
1、在 settings.py 文件中关闭robots协议 默认是True
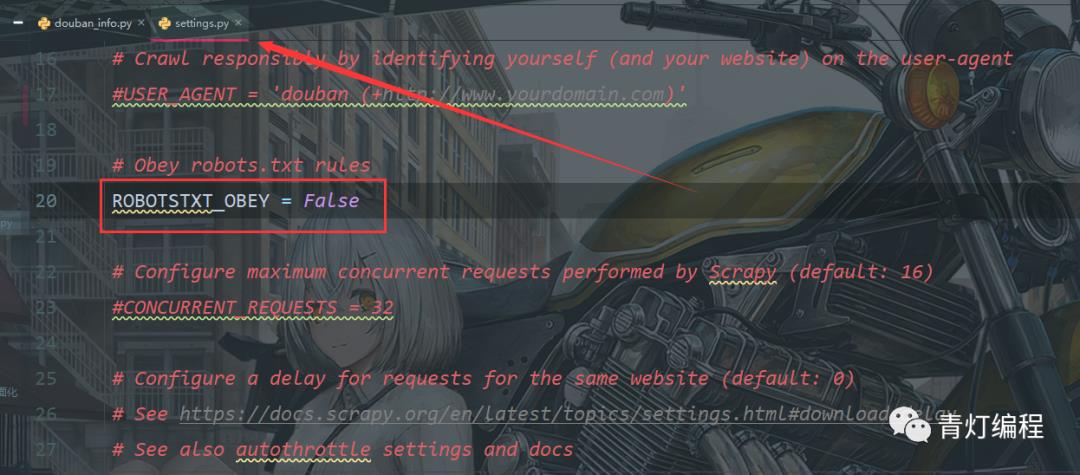
2、在爬虫文件下修改起始网址
start_urls = ['https://movie.douban.com/top250?filter=']3、写解析数据的业务逻辑
爬取内容如下:
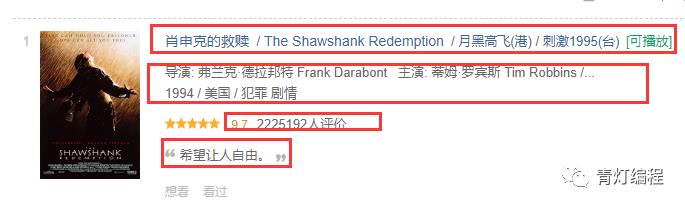
douban_info.py
import scrapyfrom ..items import DoubanItemclass DoubanInfoSpider(scrapy.Spider):name = 'douban_info'allowed_domains = ['douban.com']start_urls = ['https://movie.douban.com/top250?start=0&filter=']def parse(self, response):lis = response.css('.grid_view li')print(lis)for li in lis:title = li.css('.hd span:nth-child(1)::text').get()movie_info = li.css('.bd p::text').getall()info = ''.join(movie_info).strip()score = li.css('.rating_num::text').get()number = li.css('.star span:nth-child(4)::text').get()summary = li.css('.inq::text').get()print(title)yield DoubanItem(title=title, info=info, score=score, number=number, summary=summary)href = response.css('#content .next a::attr(href)').get()if href:next_url = 'https://movie.douban.com/top250' + hrefyield scrapy.Request(url=next_url, callback=self.parse)
itmes.py
import scrapyclass DoubanItem(scrapy.Item):# define the fields for your item here like:title = scrapy.Field()info = scrapy.Field()score = scrapy.Field()number = scrapy.Field()summary = scrapy.Field()
middlewares.py
import fakerdef get_cookies():"""获取cookies的函数"""headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/86.0.4240.111 Safari/537.36'}response = requests.get(url='https://movie.douban.com/top250?start=0&filter=',headers=headers)return response.cookies.get_dict()def get_proxies():"""代理请求的函数"""proxy_data = requests.get(url='http://127.0.0.1:5000/get/').json()return proxy_data['proxy']class HeadersDownloaderMiddleware:"""headers中间件"""def process_request(self, request, spider):# 可以拿到请求体fake = faker.Faker()# request.headers 拿到请求头, 请求头是一个字典request.headers.update({'user-agent': fake.user_agent(),})return Noneclass CookieDownloaderMiddleware:"""cookie中间件"""def process_request(self, request, spider):# request.cookies 设置请求的cookies, 是字典# get_cookies() 调用获取cookies的方法request.cookies.update(get_cookies())return Noneclass ProxyDownloaderMiddleware:"""代理中间件"""def process_request(self, request, spider):# 获取请求的 meta , 字典request.meta['proxy'] = get_proxies()return None
pipelines.py
import csvclass DoubanPipeline:def __init__(self):self.file = open('douban.csv', mode='a', encoding='utf-8', newline='')self.csv_file = csv.DictWriter(self.file, fieldnames=['title', 'info', 'score', 'number', 'summary'])self.csv_file.writeheader()def process_item(self, item, spider):dit = dict(item)dit['info'] = dit['info'].replace('\n', "").strip()self.csv_file.writerow(dit)return itemdef spider_closed(self, spider) -> None:self.file.close()
setting.py
Scrapy settings for douban projectFor simplicity, this file contains only settings considered important orcommonly used. You can find more settings consulting the documentation:https://docs.scrapy.org/en/latest/topics/settings.htmlhttps://docs.scrapy.org/en/latest/topics/downloader-middleware.htmlhttps://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'douban'SPIDER_MODULES = ['douban.spiders']NEWSPIDER_MODULE = 'douban.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agentUSER_AGENT = 'douban (+http://www.yourdomain.com)'# Obey robots.txt rulesROBOTSTXT_OBEY = False# Configure maximum concurrent requests performed by Scrapy (default: 16)CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)See https://docs.scrapy.org/en/latest/topics/settings.html#download-delaySee also autothrottle settings and docsDOWNLOAD_DELAY = 3The download delay setting will honor only one of:CONCURRENT_REQUESTS_PER_DOMAIN = 16CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)TELNETCONSOLE_ENABLED = False# Override the default request headers:DEFAULT_REQUEST_HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',}# Enable or disable spider middlewaresSee https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlSPIDER_MIDDLEWARES = {'douban.middlewares.DoubanSpiderMiddleware': 543,}# Enable or disable downloader middlewaresSee https://docs.scrapy.org/en/latest/topics/downloader-middleware.htmlDOWNLOADER_MIDDLEWARES = {'douban.middlewares.HeadersDownloaderMiddleware': 543,}# Enable or disable extensionsSee https://docs.scrapy.org/en/latest/topics/extensions.htmlEXTENSIONS = {'scrapy.extensions.telnet.TelnetConsole': None,}# Configure item pipelinesSee https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = {'douban.pipelines.DoubanPipeline': 300,}# Enable and configure the AutoThrottle extension (disabled by default)See https://docs.scrapy.org/en/latest/topics/autothrottle.htmlAUTOTHROTTLE_ENABLED = TrueThe initial download delayAUTOTHROTTLE_START_DELAY = 5The maximum download delay to be set in case of high latenciesAUTOTHROTTLE_MAX_DELAY = 60The average number of requests Scrapy should be sending in parallel toeach remote serverAUTOTHROTTLE_TARGET_CONCURRENCY = 1.0Enable showing throttling stats for every response received:AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settingsHTTPCACHE_ENABLED = TrueHTTPCACHE_EXPIRATION_SECS = 0HTTPCACHE_DIR = 'httpcache'HTTPCACHE_IGNORE_HTTP_CODES = []HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
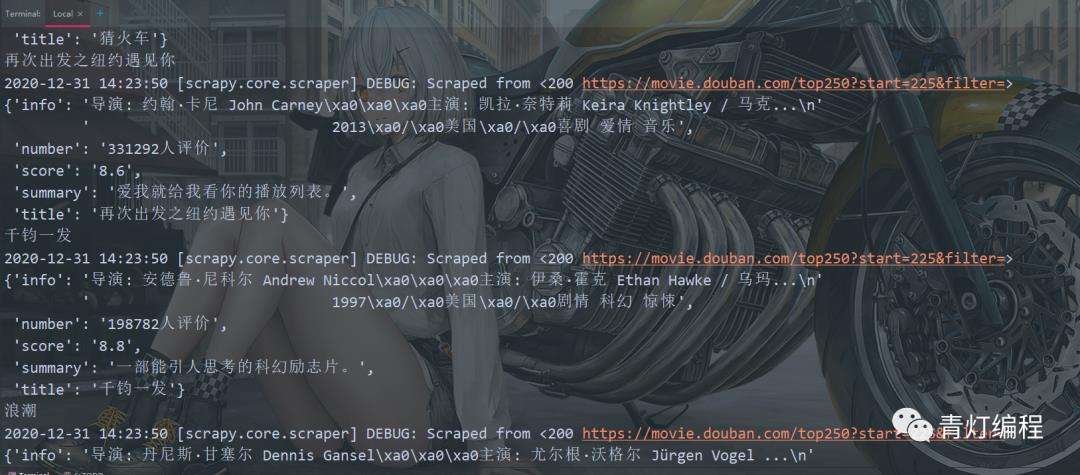
4、运行爬虫程序

输入命令 scrapy crawl + 爬虫文件名
以上是关于简单使用scrapy爬虫框架批量采集网站数据的主要内容,如果未能解决你的问题,请参考以下文章