如何快速解析xml以及灵活定义key查找信息
Posted python自动化笔记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何快速解析xml以及灵活定义key查找信息相关的知识,希望对你有一定的参考价值。
现在xml文件的运用越来越广,那么什么是xml?xml指可扩展标记语言(EXtensible Markup Language),被用来传输和存储数据,用户可以自己定义标签,非常灵活。更加详细的介绍可以参考w3c的定义,链接如下http://www.w3school.com.cn/xml/xml_intro.asp
目前python解析xml文件有以下3中方式:xml.dom,xml.sax,xml.etree,今天主要讲xml.etree中纯python写的elementtree,还有一种是c写的celementtree,速度会比elementtree快一些,不过如果解析的文件小且数量不多的话,两者的使用并不会有太大差距感知。
有时候,xml文档中同一个元素,相同的标签会重复多次,对于这样的情况应该如何灵活快速的解析呢?如果希望每次都按不同的标签作为key来查找元素,又该如何呢?我们一个一个的来解决~~~
第一个问题,可以把重复的tag用一个dict对象存起来,key就是tag,value是一个list对象存放tag的值。中间有利用来递归,递归结束条件是无子节点。同层标签,无重复标签,直接以tag:value字典的形式展示解析结果,如果是第一次遇到重复标签,需要先把该标签原来存储的结果删除,然后以新的对象形式存储结果,选择用list是因为list不会去重,允许重复结果存在。
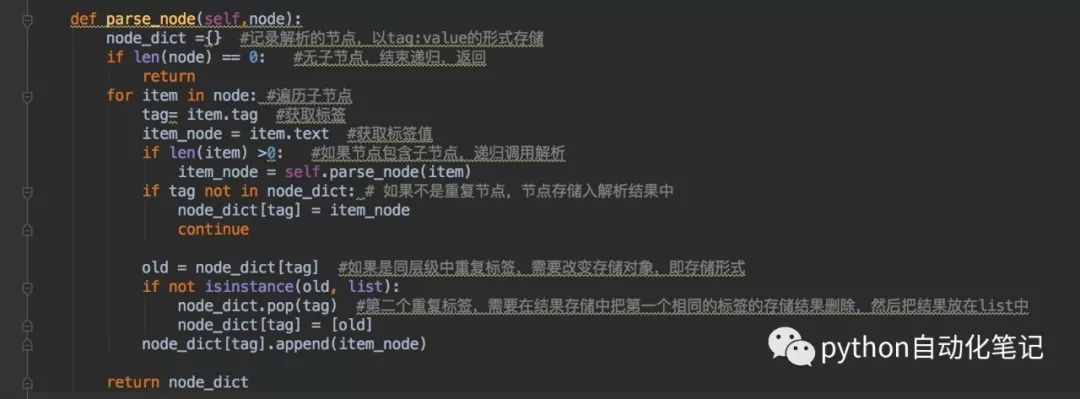
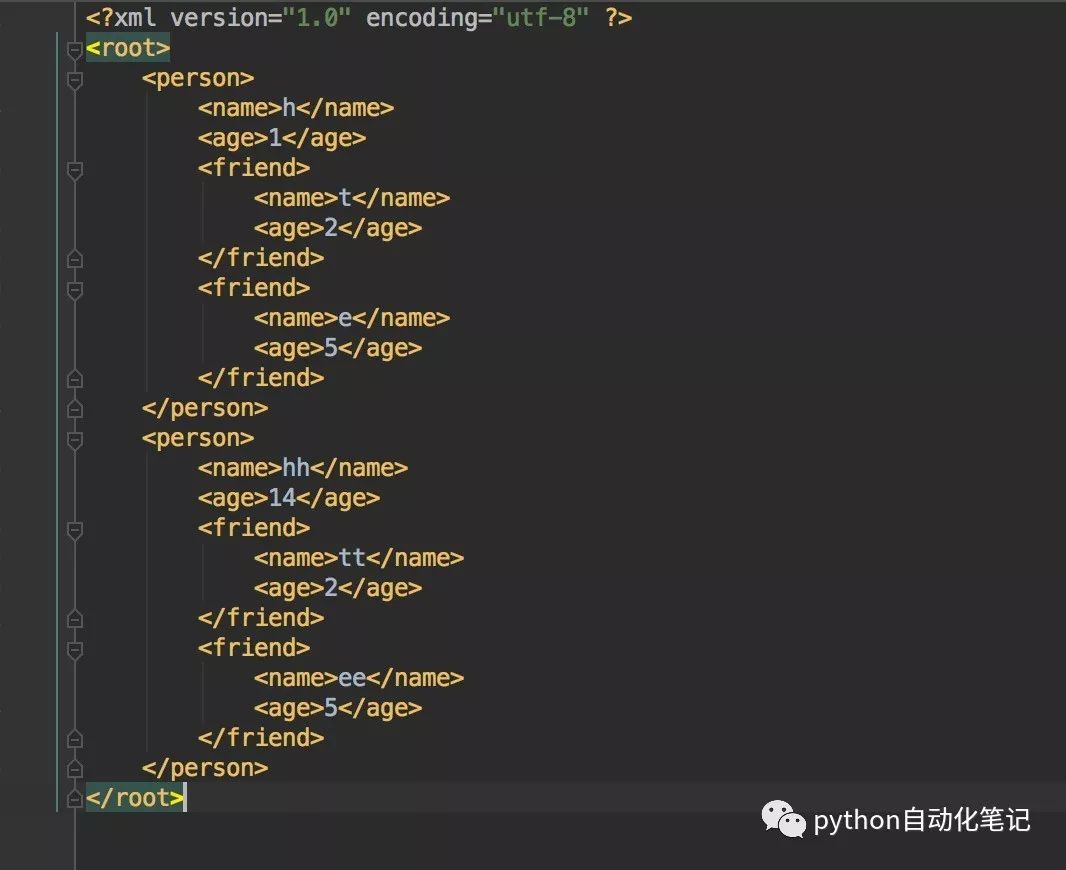

可以看到解析后的结果,每个元素是一个dict对象,同一个原素内同层级重复的标签会以list对象的形式存在。
第二问题解决方案是把查找标签作为一组key来结构化上面解析的结果。由于dict对象的key只能是不可变类型,然而key有可能是由多个标签组成的,所以选择tuple类型作为key.
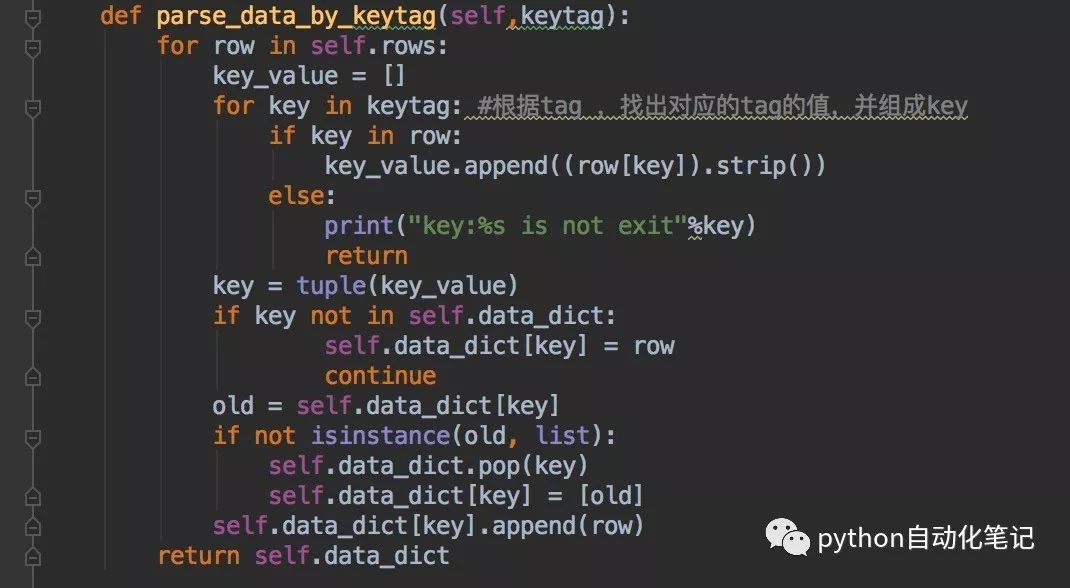
key可以是一个标签,也可以是多个标签组合的。如果key值重复了,相同key值的会放在一个list中。
今天就到这里啦,有疑问欢迎沟通交流,谢谢~~
以上是关于如何快速解析xml以及灵活定义key查找信息的主要内容,如果未能解决你的问题,请参考以下文章