木木学设计模式之1.迭代器模式
Posted 脚本之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了木木学设计模式之1.迭代器模式相关的知识,希望对你有一定的参考价值。
脚本之家
你与百万开发者在一起




我看过好些关于学习方法的书籍,它们大都不约而同的提到了这么一个概念:刻意学习(刻意练习)。这种练习方法的核心是假设专家级水平是逐渐地练出来的,而有效进步的关键在于找到一系列的小任务,让受训者按顺序完成。这些小任务必须是受训者正好不会做,但是又正好可以学习掌握的。
而且在《万万没想到:用理工科思维理解世界》这本书中也明确的指出,最好的学习方式是“学徒制–即一个老师一对一的辅导一个学徒,将自己丰富的经验技术传授给学徒,并能针对学徒学习中错误的地方进行纠正。
本专栏对设计模式的讲解便是建立在以上两种科学的学习方法之上,以师徒情景的方式进行。
木木 – 初级程序员,学徒,对编程技术充满兴趣,但由于自己的经验有限,总是会遇到技术瓶颈。
乔大大 – 资深架构师,大神,专家,对软件技术无所不知,擅长将深奥的知识深入浅出的讲解出来,是木木的良师益友。
2019年4月16日 天气晴
木木今天接到了一个新的修改任务,明明是很简单的修改,但是由于需要修改的地方在软件系统源码中多处出现,耗费了他很多的时间,于是他很虚心的跑去向“设计模式”专家谢大神请教。
木木:乔大大,今天我遇到了一个简单的修改,但是却耗费了我很多时间,您帮我看看,有什么优化的方法不?
乔大大:什么问题?说来听听。
木木:我们的项目有一个聚合类,以前内部是用list实现的,现在老大叫我改为用数组实现,修改的过程中,我发现很多地方需要对它进行遍历,换成数组实现后,遍历的代码变了,于是我不得不进行多处修改。我问题是这样的:
业务场景:
原来的需求:将书本聚合类 BookAggregate实例对象 中的所有书本 Book实例对象 遍历一遍,做一些处理
修改的内容:现在需要将BookAggregate中list属性类型由List变为Array
/**
* 说明:书本类
*
* @author qiaodada
* @since 2019/4/18
*/
public class Book {
public Book(String name) {
this.name = name;
}
private String name;
...
}
/**
* 说明:书本聚合类
*
* @author qiaodada
* @since 2019/4/18
*/
public class BookAggregate{
private String name;
private List<Book> books; //改为用数组实现
public BookAggregate(String name, List<Book> books) {
this.name = name;
this.books = books;
}
...
}
问题代码片段:
for(int i=0;i<bookAggregate.getBooks().size();i++){
Book book = bookAggregate.getBooks().get(i);
...
}
将list改为array后:
for(int i=0;i<bookAggregate.getBooks().length;i++){ //1处修改
Book book = bookAggregate.getBooks()[i]; //2处修改
...
}
乔大大:明白了,这个问题很好解决啊,用迭代器模式不就行了~
木木:哇,传说中的设计模式?对了,什么是迭代器模式?我记得java的集合类好像都有一个Iterator()方法,是这个吗?(触碰到了不熟悉的区域)
乔大大:听我慢慢给你讲哇。
1.什么是迭代器模式:
迭代器模式 是一种将聚合数据遍历功能与聚合类进行解耦,用于在数据集合中按照顺序遍历集合的设计模式。
2.再看看迭代器模式的UML类图:
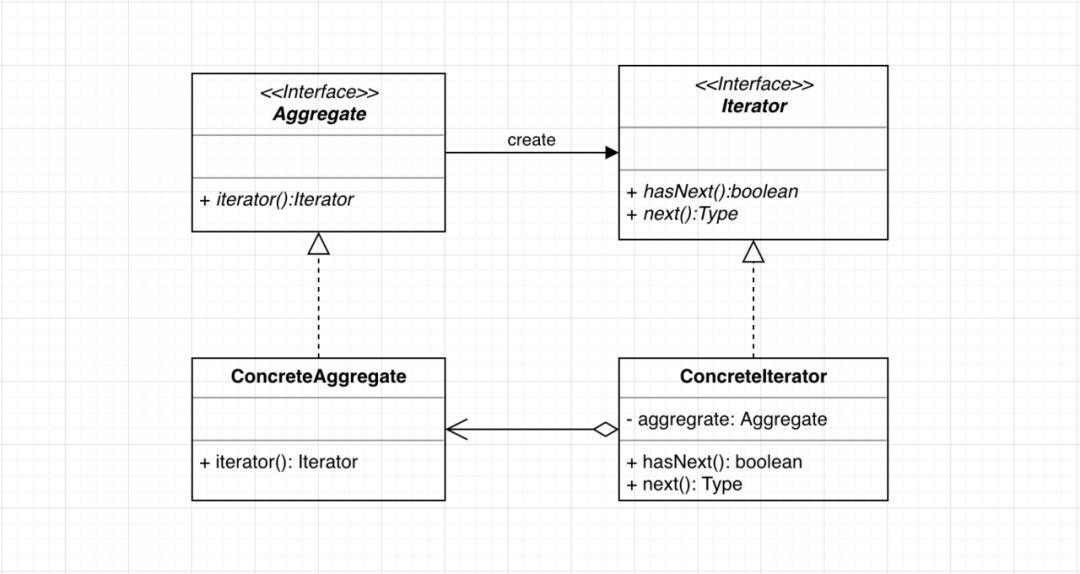
木木:看了这个UML类图,我发现了迭代器模式有四个主要类,您能分别讲解一下吗?
乔大大:我正要接着说UML类图中的这四个主要的类呢。
3.迭代器模式中登场的四个主要角色
1.Iterator–迭代器接口
定义按顺序逐个遍历元素的接口。主要定义hasNext()和next()方法,其中next()方法的作用为:取出当前元素,并将游标移动到下一个位置。
2.ConcreteIterator–具体迭代器类
Iterator接口的具体实现类。实现Iterator接口定义的方法,一般会定义具体聚合类和当前位置两个属性用于实现遍历。
3.Aggregate–聚合接口
定义创建具体Iterator类的接口。主要定义Iterator()方法,返回一个具体的Iterator实例。实现此接口的类表明其具有迭代功能。
4.ConcreteIterator–具体聚合类
Aggregate接口的具体实现类。主要实现了Iterator()方法,返回所对应的迭代器。
乔大大:下面将迭代器模式应用到你遇到问题的场景。
4.对木木所遇到的问题的改进:
将聚合类BookAggregate的遍历改为专门的iterator来实现。
UML类图:
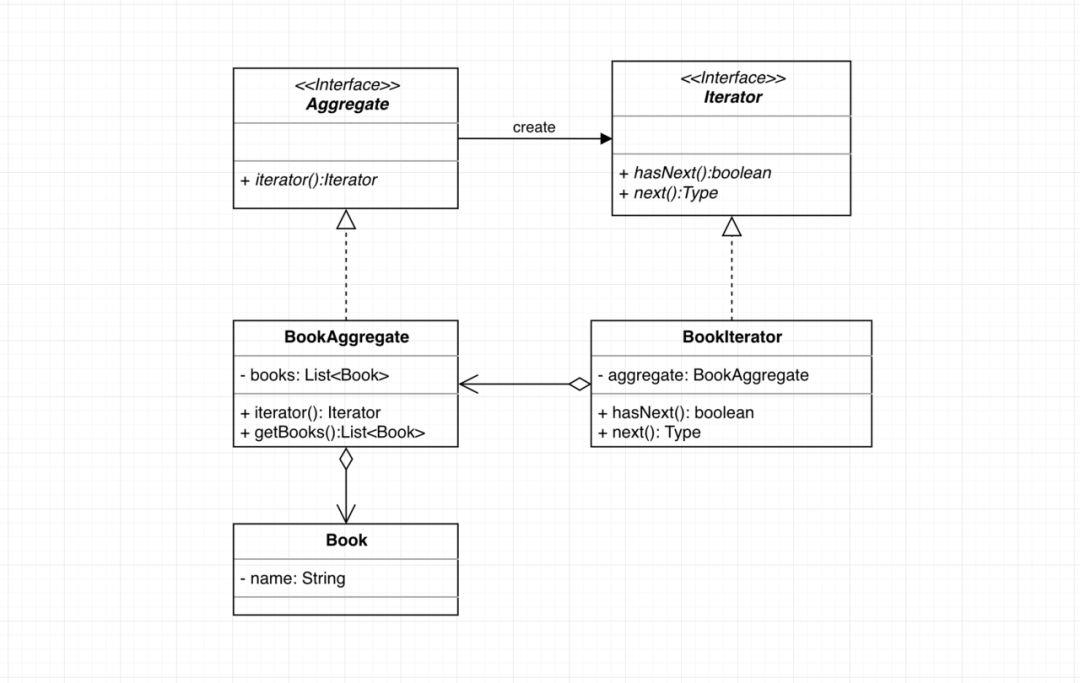
抽象接口:
/**
* 说明:迭代器接口
*
* @author qiaodada
* @since 2019/4/18
*/
public interface Iterator<T> {
T next();
boolean hasNext();
}
/**
* 说明:聚合接口
*
* @author qiaodada
* @since 2019/4/18
*/
public interface Aggregate<T> {
Iterator<T> iterator();
}
实现类:
/**
* 说明:书本聚合类
*
* @author qiaodada
* @since 2019/4/18
*/
public class BookAggregate implements Aggregate<Book> {
private String name;
private List<Book> books;
public BookAggregate(String name, List<Book> books) {
this.name = name;
this.books = books;
}
@Override
public Iterator<Book> iterator() {
return new BookIterator(this);
}
}
/**
* 说明:书本迭代器
*
* @author qiaodada
* @since 2019/4/18
*/
public class BookIterator implements Iterator<Book> {
private BookAggregate aggregate;
private int position;
public BookIterator(BookAggregate aggregate) {
this.aggregate = aggregate;
this.position = 0;
}
@Override
public Book next() {
return aggregate.getBooks().get(position++); //1.如果BookAggregate中的books属性改为数组实现,此处需修改
}
@Override
public boolean hasNext() {
return position < aggregate.getBooks().size();//2.如果BookAggregate中的books属性改为数组实现,此处需修改
}
}
运行样例:
/**
* 说明:
*
* @author qiaodada
* @since 2019/4/18
*/
public class IteratorMain {
public static void main(String[] args) {
Book book1 = new Book("《设计模式之禅》");
Book book2 = new Book("《head first 设计模式》");
Book book3 = new Book("《图解设计模式》");
List<Book> books = Stream.of(book1,book2,book3).collect(Collectors.toList());
BookAggregate aggregate = new BookAggregate("设计模式系列图书",books);
Iterator<Book> iterator = aggregate.iterator();
System.out.println(aggregate.getName()+":");
while (iterator.hasNext()){
Book book = iterator.next();
System.out.println(book.getName());
}
}
}
运行结果:
设计模式系列图书:
《设计模式之禅》
《head first 设计模式》
《图解设计模式》
木木:我明白了,使用迭代器模式之后,挨个获取书本的循环代码好像就跟BookAggregate无关了,直接交给了具体的迭代器类(BookIterator)来实现了,实现了解耦,确实是一个很好的设计。
乔大大:正是这样的。
5.为什么要用设计模式?
木木:但是我还是有一个疑问,通过迭代器模式重构代码以后,好像多了好几个类和接口,代码的复杂度似乎比以前更高了。
乔大大:你说的没错,辩证唯物主义告诉我们:任何事物都具有两面性。应用设计模式解耦模块,带来灵活度和可扩展性,同时很多时候会带来复杂度的增加(主要是类的增加)。所以,我们需要评估引入设计模式后的利弊,在恰当的地方引入,不要滥用设计模式,造成过度设计。
举例说明:
Iterator<Book> iterator = aggregate.iterator();
while (iterator.hasNext()){
Book book = iterator.next();
}
乔大大: 看上面的核心代码,这里在遍历book的时候只用到了iterator中的方法,并没有用到aggregate中的方法,也就是说,遍历逻辑并不需要依赖aggregate的实现。这样带来的好处就是当BookAggregate内部改用数组来存储的时候,上面的代码并不需要做任何改变(只需要修改BookIterator中hasNext()和next()的实现),依旧能够运行。
木木:这对于BookAggregate的调用者来说真的是太方便了!真希望我同事都能写出这样的组件给我调用,哈哈~
乔大大:对的,设计模式的作用就是指导我们编写可复用的类,所谓“可复用”就是指将类实现为“组件”,当一个组件发生改变时,不需要对其他组件进行修改或者只需要很小的修改即可应对。
乔大大:例如本例中,我们将各个类和接口都看成是组件,我们对比应用设计模式之前和应用设计模式之后的组件之间的关系图:
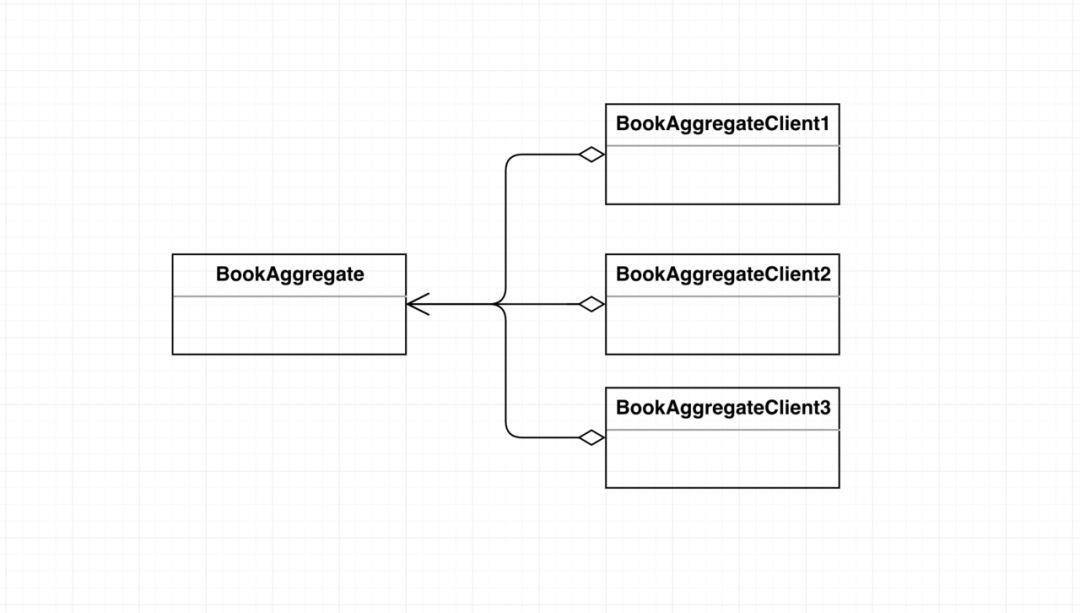
BookAggregate和它的调用客户端组件紧密相连,耦合紧密,修改BookAggregate,改为数组实现后,它所对应的多个客户端组件的循环代码都需要进行修改,工作量大,不利于维护。
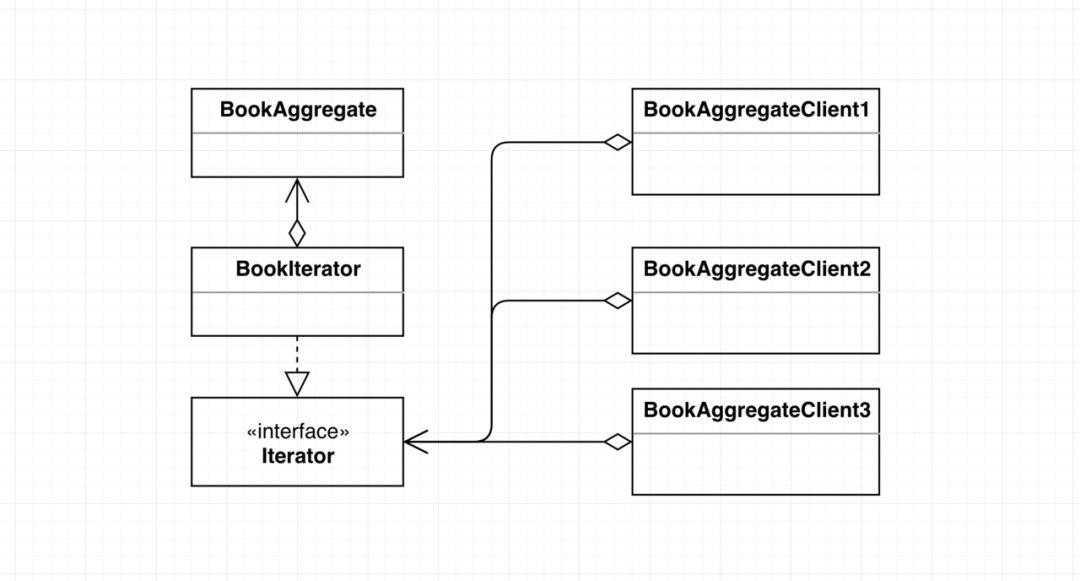
BookAggregate的多个客户端组件只与Iterator接口耦合,与BookAggregate解耦,由于Iterator只是一个抽象接口,不会改变(除非修改接口的方法名),BookAggregate修改为数组实现后,只需要修改BookIterator中对应的hasNext()和next()的实现代码,BookAggregate所对应的多个客户端组件不需要作任何的改变。
木木:哇塞,秒啊,通过引入设计模式之后,成功的将由BookAggregate的修改引起的多处修改变为一处修改,提高代码的可维护性,good!
乔大大:正是如此,这下你明白了为什么要用设计模式了吧。
6.JAVA中的迭代器组件
乔大大:其实,对于设计模式,JAVA中有不少原生的支持。比如迭代器模式,JAVA中就已经提供了java.lang.Iterable接口(对应类图中的Aggregate接口)和java.util.Iterator接口,我们可以开箱即用。
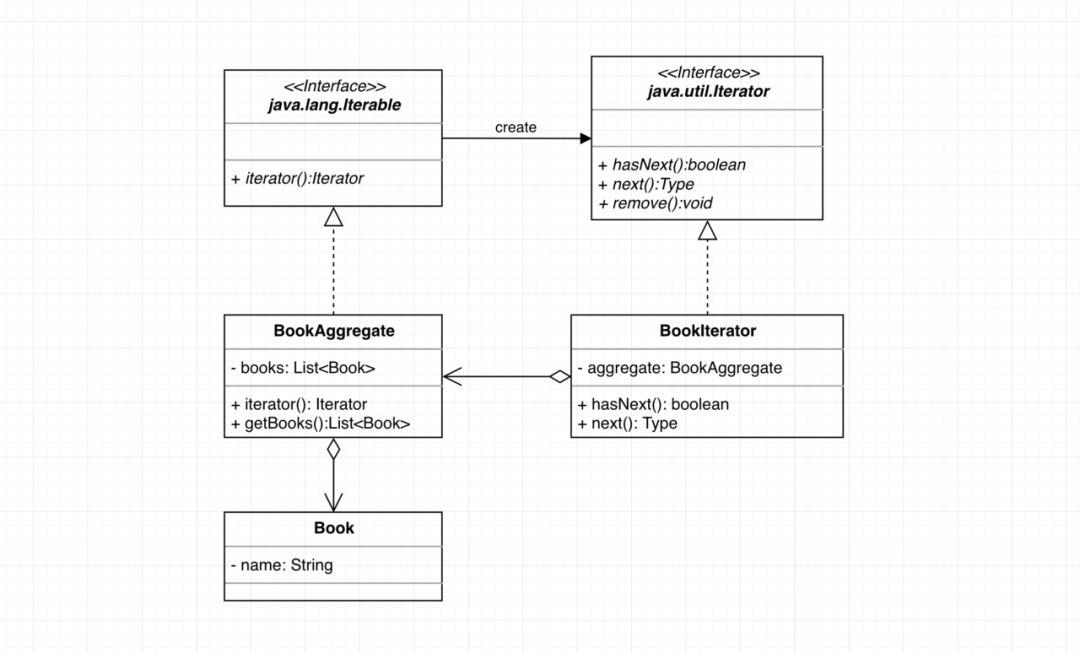
乔大大:并且,通过JAVA中的迭代器组件实现的聚合类可以使用增强for循环语法进行迭代操作,大大简化代码!
...
System.out.println(aggregate.getName());
for (Book book: aggregate) {
System.out.println(book.getName());
}
...
木木:对啊,通过使用JAVA提供的迭代器通用组件类,简化了我们的编码量,只需要编写具体的实现类就行了。
7.优先使用抽象来编程
木木:乔大大,我还注意到了一个细节,看下图:
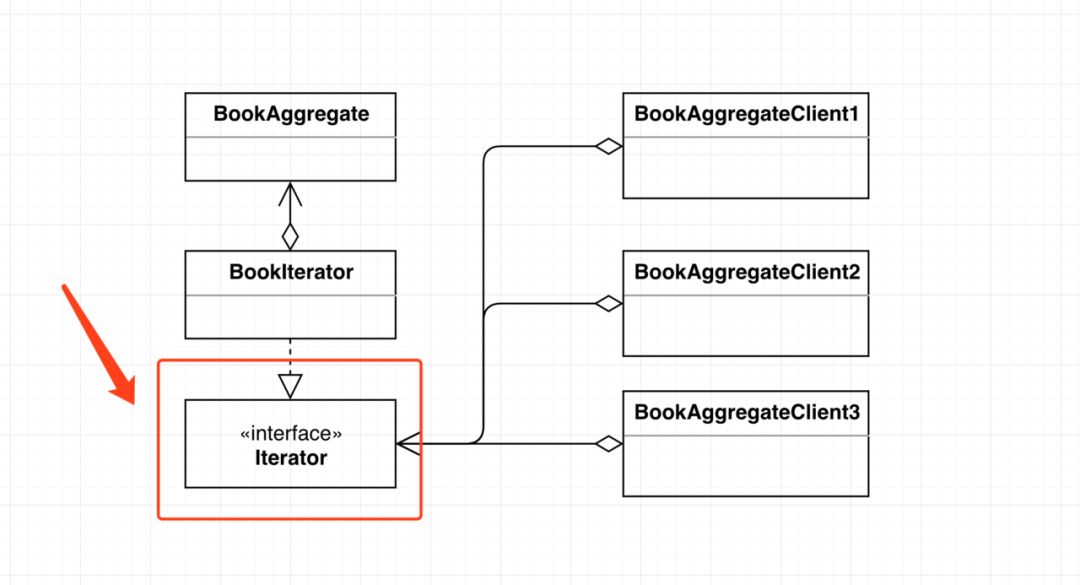
这里的多个BookAggregateClient组件都引用的是Iterator接口,而不是直接引用BookIterator实现类,为什么要这样做呢?
乔大大:这个问题问的非常好!看来你是在认真思考的。
木木:嘿嘿~~
乔大大:使用具体的类,很容易导致类之间的强耦合,这些类也难以作为组件被再次利用。为了弱化类之间的耦合,使类更容易作为组件被再次利用,我们需要引入抽象类和接口。
举例说明:如果现在有一个新的需求,需要一个能遍历钢笔的组件。
对于直接依赖实现类编程的方式,那么我们以前的BookAggregateClient组件就不能被复用,需要重新写一个PenAggregateClient类,如下图:
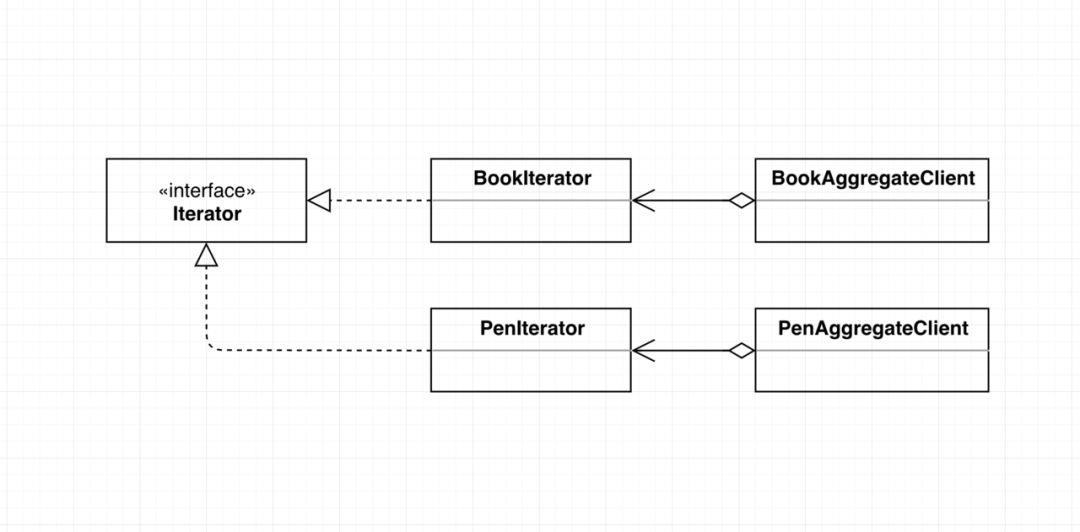
注意,BookAggregateClient和PanAggregateClient所具有的功能其实是相同的,即遍历一个集合。那我们有没有必要针对不同遍历元素编写不同的类来进行遍历呢?答案明显是否定的。
对于依赖抽象编程的方式,那么我们以前的组件就能够被复用,这里我们将它命名为IteratorClient。如下图:
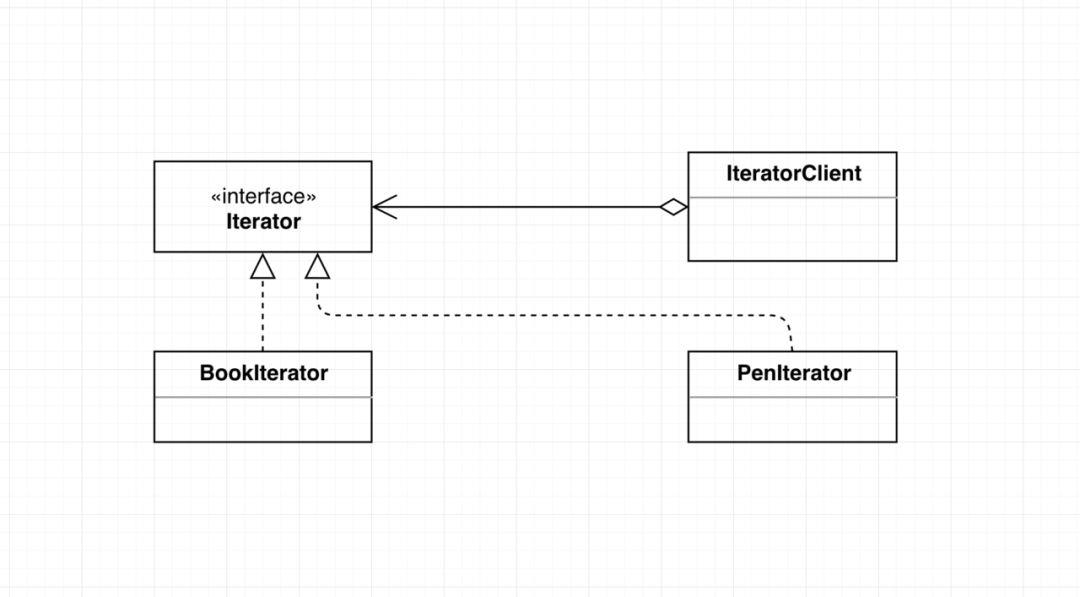
修改为依赖接口后,不管是进行遍历Book还是遍历Pen的业务,都可以通过同一个IteratorClient来实现啦,成功实现了组件的复用。
具体代码:
/**
* 说明:进行遍历的通用组件
*
* @author lupan
* @since 2019/4/20
*/
public class IteratorClient {
public static <T> void iterate(Iterator<T> iterator) { //如果这里依赖具体的迭代器类,就不能实现复用。
while (iterator.hasNext()) {
T t = iterator.next();
...//进行其他操作,如:System.out.println(t);
}
}
}
木木:组件的复用性真的提高了好多,我以后再也不要只使用具体类来编程,要优先使用抽象类和接口来编程了。
8.面向对象五个基本原则–单一职责原则
木木听了乔大大的教导后,回去应用迭代器模式将代码进行了重构以后,得到了项目组老大的表扬。
后来木木又进行了自我反思,心想,设计模式真的太好用了,以后一定要跟着乔大大把设计模式学好了。对这次代码的重构所用的编码原则进行了总结:
提到面向对象基本原则,不得不先注意到耦合和内聚这两个概念,它们是这些原则的基础。
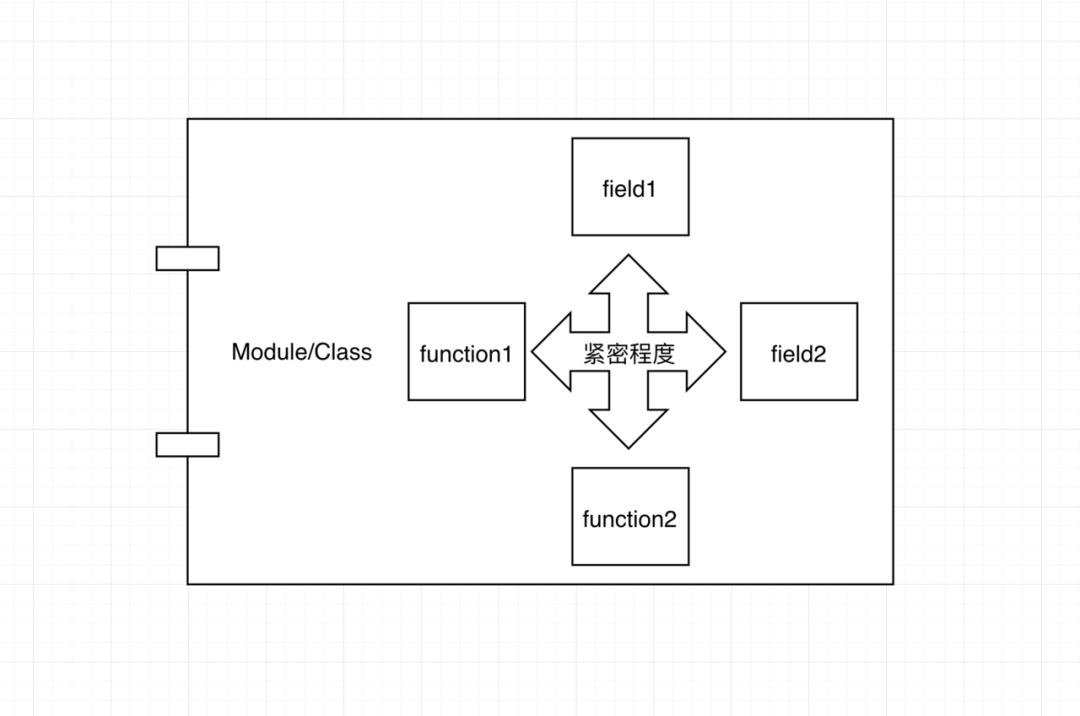
内聚
内聚 用来描述一个类或模块紧密的达到单一目的或责任的程度。当一个模块或者类被设计成只支持一组相关的功能时,我们说它具有高内聚;反之,当被设计成支持一组不相关功能时,我们说它具有低内聚。
耦合
耦合 用来描述一组类或模块间相互关联程度。当一组类或者模块被设计得关联度很高时,我们说它们是高耦合;反之,当一组类或模块被设计成不相互关联或者关联度很低时,我们说它们就有低耦合。
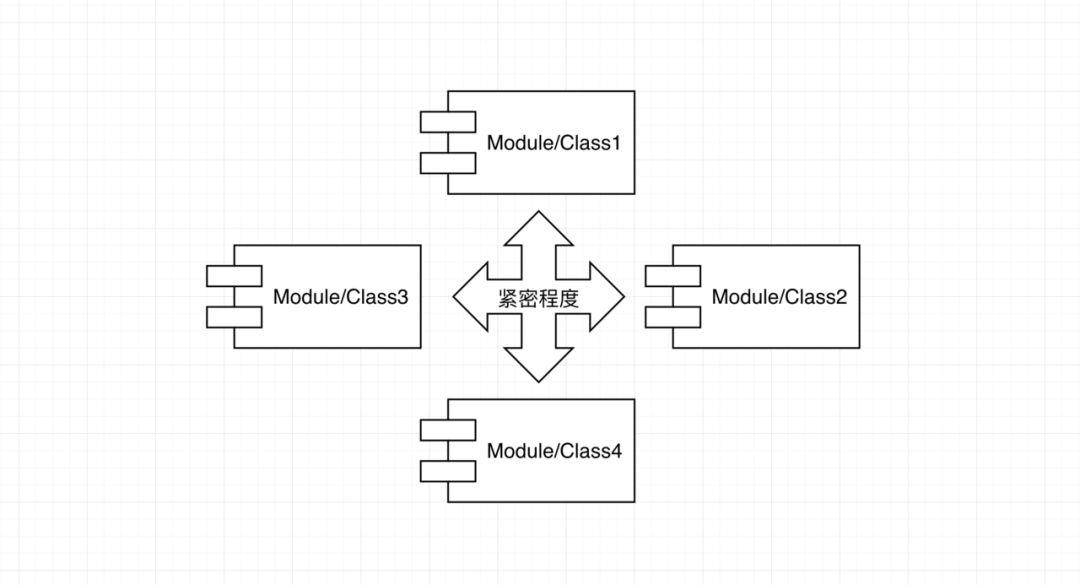
内聚描述类或模块内部的紧密程度,耦合描述类或模块之间的紧密程度。
单一职责原则:
单一职责原则(SRP:Single responsibility principle)又称单一功能原则,面向对象五个基本原则之一。它规定一个类应该只有一个发生变化的原因。
所谓职责是指类变化的原因。如果一个类有多于一个的动机被改变,那么这个类就具有多于一个的职责。而单一职责原则就是指一个类或者模块应该有且只有一个改变的原因。
如果一个类承担的职责过多,就等于把这些职责耦合在一起了。一个职责的变化可能会削弱或者抑制这个类完成其他职责的能力。这种耦合会导致脆弱的设计,当发生变化时,设计会遭受到意想不到的破坏。而如果想要避免这种现象的发生,就要尽可能的遵守单一职责原则。此原则的核心就是解耦和增强内聚性。
对应于本案例,最开始的BookAggregate类有两个职责,管理集合数据、遍历集合。没有用到Iterator模式时,这两个职责都是与BookAggregate紧密联系的,在应用Iterator模式对其进行修改后,将遍历集合的职责交给了Iterator实现来完成,实现了职责的分离,符合单一职责原则,增强了组件的可复用性。
参考资料
《一百小时天才理论》
《万万没想到:用理工科思维理解世界》
《head first 设计模式》
《图解设计模式》
百度百科
创作不易,这篇技术分享花费了我整整一周下班后的时间。
能力有限,若有纰漏,不吝赐教。
声明:本文为 脚本之家专栏作者 投稿,未经允许请勿转载。
写的不错?赞赏一下

长按扫码赞赏我
-END-

● ![]()
● ![]()
●
●
●
●
返回 上一级 搜索“Java 女程序员 大数据 留言送书 运维 算法 Chrome 黑客 Python javascript 人工智能 女朋友 mysql 书籍 等关键词获取相关文章推荐。
以上是关于木木学设计模式之1.迭代器模式的主要内容,如果未能解决你的问题,请参考以下文章