sqlserver里面多个字段的数据计算以及统计,各位帮帮忙
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sqlserver里面多个字段的数据计算以及统计,各位帮帮忙相关的知识,希望对你有一定的参考价值。
如图表名tbl_Voucher ,字段 issms(0和1),0代表短信,1代表彩信,字段vouchertype(充值,消费,扣费,返还四种类型) userid对应另外一个客户表的主键useridA,useridA下面还有子ID,需求是:根据当前用户的ID查询出他的所有子ID的短信充值数,彩信充值数,短信扣费条数,彩信扣费条数并根据userid列出来。我贴个效果图就如上图,可以用存储过程,麻烦各位大神帮帮忙这个东西我前面没做出来,把他绕过去了,现在回头再坐还是没头绪,实在是没分了但是还是贴出来,希望有人帮帮忙
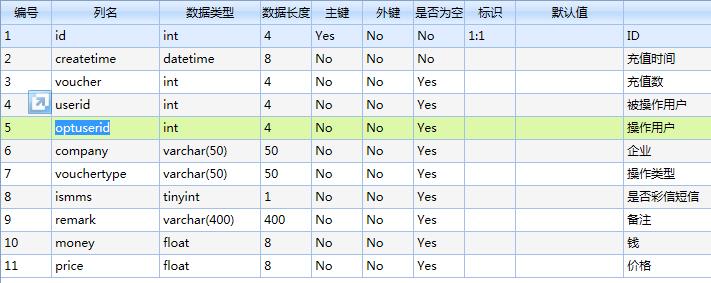
useridA下面还有子ID这是什么意思! 不是属于客户表基本信息嘛!
还是userid是被操作用户,按理说应是一对多的关系.客户表的主键useridA 多个被操作用户
如有问题可以追问,我当及时回答.
希望能帮到你!追问
属于 就像那个省市三级联动那样的
一个ID下面他有子ID,子ID下面也有可能有子ID
怎样获取一个父ID的所有子ID那个我解决了,我写了个函数可以获得
即然父ID的所有子ID那个你解决了.这是重要的一步.
那就没有什么难点了啊。你现在无非就是通过获取的id集合关联tbl_Voucher ,通过issms 和vouchertype分组汇总,然后列转行显示出来就可以了.
MySQL 根据某一个或者多个字段查找重复数据
之前上线了一个类似于微信或者支付宝账单的功能,其中有一张统计表。里面根据用户ID、年、月查询出来当月的订单数以及订单总金额。当时在创建索引的时候,是根据用户ID、年、月字段创建的联合索引。
创表 SQL
CREATE TABLE `stat_order_count` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'id',
`user_id` bigint NOT NULL DEFAULT '0' COMMENT '用户id',
`year` int NOT NULL DEFAULT '0' COMMENT '年',
`month` int NOT NULL DEFAULT '0' COMMENT '月',
`order_count` int NOT NULL DEFAULT '0' COMMENT '记工次数',
`order_amount` decimal(32,4) NOT NULL DEFAULT '0.0000' COMMENT '记工金额',
`record_date` date NOT NULL DEFAULT '1970-01-01' COMMENT '记工归属月(YYYY-MM-DD,其中DD必须为01)',
`create_at` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间',
`update_at` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '更新时间',
PRIMARY KEY (`id`),
KEY `idx_user_id_record_date` (`user_id`,`record_date`),
KEY `idx_create_at` (`create_at`),
KEY `idx_update_at` (`update_at`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='按月统计订单数与金额';
整个核心逻辑如下:
- 如果当前用户在当前年当前月没有数据就初始化
- 如果当前用户在当前年当前月有数据就更改统计信息
在非生产环境由于数据库没有进行主从分离,所以在测试的时候没有问题。当项目进行上线的时候,生产环境的数据库进行主从分离。数据新增操作的是主库,数据查询操作的是从库。如果两条数据间隔时间比较短的话,第一条数据新增到主库,第二条数据查询从库就会查询不到。同一个用户在当前年,当前月就会有多条。这样在查询用户月账单信息的时候就会查询出来多条,就会报错。
这个时候就需要把重复的数据查询出来进行删除,然后再把原来的联合索引删除,添加唯一索引。以下是查询出重复数据的 SQL:
查询重复数据.sql
select b.id
from(
select id
from stat_order_count a
where(a.user_id, a.year, a.month) in(
select user_id, year, month
from stat_order_count
group by user_id, year, month
having count(*)> 1)) b
where b.id not in(
select min(id) as id
from stat_order_count
group by user_id, year, month
having count(*)> 1)
根据查询出来的 ID 进行数据删除,然后再更新索引。
更新索引.sql
> 删除原有联合索引
alter table stat_order_count drop index idx_user_id_year_month;
> 添加唯一索引
alter table stat_order_count add UNIQUE index uk_user_id_year_month(`user_id`,`year`,`month`);
最后在数据查询的时候强制查询阿里云主库:
强制查询主库.sql
/*FORCE_MASTER*/ SELECT * FROM stat_order_count
where user_id = ? and year = ? and month = ?;
参考文章:
- https://www.jb51.net/article/152155.htm
- https://help.aliyun.com/knowledge_detail/52221.html
以上是关于sqlserver里面多个字段的数据计算以及统计,各位帮帮忙的主要内容,如果未能解决你的问题,请参考以下文章