前端进阶之路:1.5w字整理23种前端设计模式
Posted web前端学习圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端进阶之路:1.5w字整理23种前端设计模式相关的知识,希望对你有一定的参考价值。
△ 是新朋友吗?记得先点web前端学习圈关注我哦~
我们开发人员经常会说:"Talk is cheap, show me the code"。要想写出令人赏心悦目的代码,我觉得是否使用了合理的设计模式起了至关重要的作用。
心里按摩部分
我们写的代码就是我们的名片,但是拿出如果是没有经过设计的代码,不仅让人读起来费劲,还会让人质疑我们的能力。
还有阻碍我们进步的是当你去读别人的框架或者源码的时候,作者往往用到了大量的设计模式,如果我们不能对设计模式足够敏感的话,很可能会浪费大量的时间,甚至一直卡在一个地方出不来,而且设计模式也在面试的过程中占了很大的一部分。
所以不论是为了以后code review的时候你的代码倍儿有面儿,还是你自己的成长和职业发展,我们都应该好好的学一学设计模式。废话不在多说,下面让我们来一起开始正式的学习。
设计原则与思想
一切抛开设计原则讲设计模式的行为都是无耻渣男耍流氓的行为,只会让你爽一时,永远也不能拥有自己的幸福,最后掉入一个无底洞(咳咳,跑题了)。
总之我们不能手里有把锤子,看哪里都是钉子,要知道为什么要使用这种设计模式,以及解决了什么问你题,有哪些应用场景。这才是关键的关键,如果你清晰的明白了这些设计原则,甚至可以根据场景组装你自己的设计模式。
废话不多说,我们应该也大体了解一些比较经典的设计模式,比如 SOLID、KISS、YAGNI、DRY、LOD 等。我们接下来会一一的进行介绍。
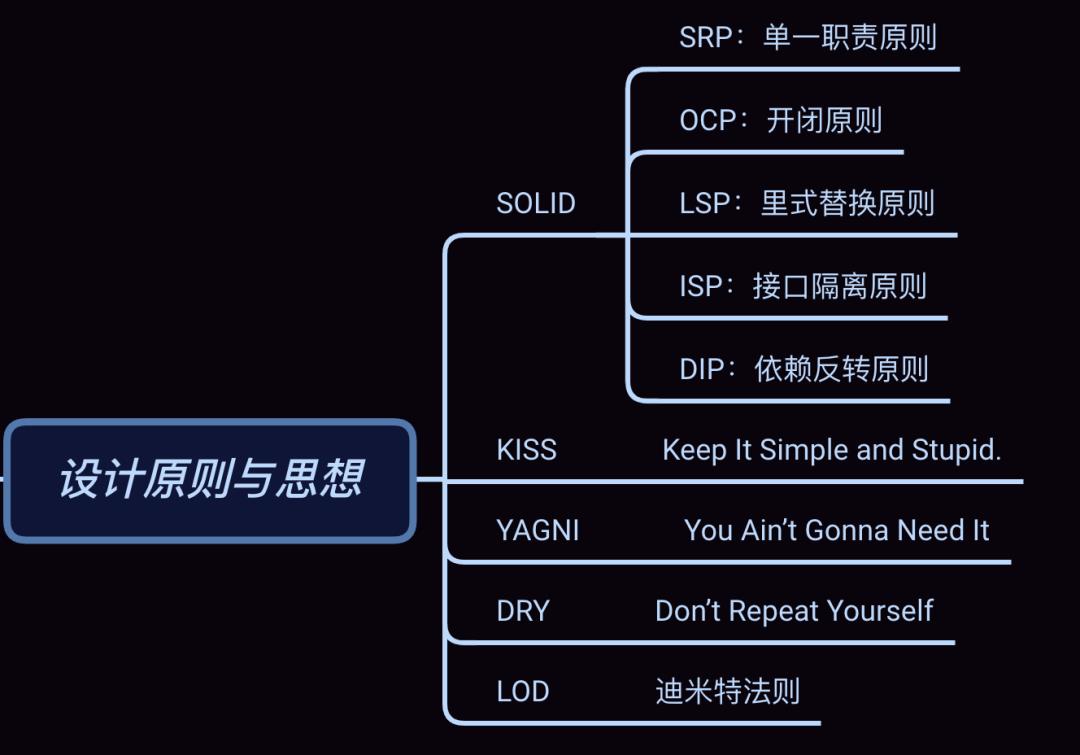
SOLID 原则
SOLID 原则并非单纯的 1 个原则,而是由 5 个设计原则组成的,它们分别是:单一职责原则、开闭原则、里式替换原则、接口隔离原则和依赖反转原则,依次对应 SOLID 中的 S、O、L、I、D 这 5 个英文字母。我们来分别看一下。
SRP-单一职责原则
全称:Single Responsibility Principle
定义:A class or module should have a single responsibility.==>一个类或者模块只负责完成一个职责(或者功能)。
理解:每一个类,应该要有明确的定义,不要设计大而全的类,要设计粒度小、功能单一的类。
作用:避免将不相关的代码耦合在一起,提高了类或者模块的内聚性。
OCP-开闭原则
全称:Open Closed Principle
定义:software entities (modules, classes, functions, etc.) should be open for extension , but closed for modification. ==> 软件实体(模块、类、方法等)应该“对扩展开放、对修改关闭”。
描述:添加一个新的功能应该是,在已有代码基础上扩展代码(新增模块、类、方法等),而非修改已有代码(修改模块、类、方法等)。
作用:增加了类的可扩展性。
LSP-里式替换原则
全称:Liskov Substitution Principle
定义:Functions that use pointers of references to base classes must be able to use objects of derived classes without knowing it.==>子类对象能够替换程序中父类对象出现的任何地方,并且保证原来程序的逻辑行为不变及正确性不被破坏。
看定义还是有点抽象,我们来举个例子看一下
class GetUser {constructor(id) {this.id = id}getInfo() {const params = {id: this.id}//...code here}}class GetVipUser extends GetUser {constructor(id, vipLevel) {super(id)this.id = idthis.level = vipLevel}getInfo() {const params = {id: this.id}if (this.level != void 0) {params.level = this.level}super.getInfo(params)}}class Demo {getUser(user) {console.log(user.getInfo())}}// 里式替换原则const u = new Demo()u.getUser(new GetUser())u.getUser(new GetVipUser())
我们看到GetVipUser的设计是符合里式替换原则的,其可以替换父类出现的任何位置,并且原来代码的逻辑行为不变且正确性也没有被破坏。
很多人看到这里就会说,你这不就是利用了类的多态特性吗?确实,他俩看着确实有点像,但是实际上是完全不同的两回事,我们把上面的代码稍微改造一下。
class GetUser {constructor(id) {this.id = id}getInfo() {const params = {id: this.id}//...code here}}class GetVipUser extends GetUser {constructor(id, vipLevel) {super(id)this.id = idthis.level = vipLevel}getInfo() {const params = {id: this.id}if (this.level == void 0) {throw new Error('level should not undefind')}super.getInfo(params)}}class Demo {getUser(user) {console.log(user.getInfo())}}// 里式替换原则const u = new Demo()u.getUser(new GetUser())u.getUser(new GetVipUser())
改动之后我们可以很清晰的看到,父类在运行时是不会出错的,但是子类当没有接受level的时候回抛出错误,整个程序的逻辑和父类产生了区别,所以是不符合里式替换原则的。
稍微总结一下。虽然从定义描述和代码实现上来看,多态和里式替换有点类似,但它们关注的角度是不一样的。多态是面向对象编程的一大特性,也是面向对象编程语言的一种语法。它是一种代码实现的思路。而里式替换是一种设计原则,是用来指导继承关系中子类该如何设计的,子类的设计要保证在替换父类的时候,不改变原有程序的逻辑以及不破坏原有程序的正确性。
里式替换原则是用来指导,继承关系中子类该如何设计的一个原则。理解里式替换原则,最核心的就是理解“design by contract,按照协议来设计”这几个字。父类定义了函数的“约定”(或者叫协议),那子类可以改变函数的内部实现逻辑,但不能改变函数原有的“约定”。这里的约定包括:函数声明要实现的功能;对输入、输出、异常的约定;甚至包括注释中所罗列的任何特殊说明。
LSP-接口隔离原则
全称:Interface Segregation Principle
定义:Clients should not be forced to depend upon interfaces that they do not use. ==> 客户端不应该被强迫依赖它不需要的接口。(其中的“客户端”,可以理解为接口的调用者或者使用者)。
描述:使用TyepScript开发的小伙伴可能对Interface更熟悉一些,但是把接口单纯的理解就是Interface也比较片面,我们说的接口可以包括这三个方面
一组 API 接口集合
单个 API 接口或函数
OOP 中的接口概念
这一原则和单一职责原则有点类似,只不过它更侧重于接口。
如果把“接口”理解为一组接口集合,可以是某个类库的接口等。如果部分接口只被部分调用者使用,我们就需要将这部分接口隔离出来,单独给这部分调用者使用,而不强迫其他调用者也依赖这部分不会被用到的接口。
如果把“接口”理解为单个 API 接口或函数,部分调用者只需要函数中的部分功能,那我们就需要把函数拆分成粒度更细的多个函数,让调用者只依赖它需要的那个细粒度函数。
如果把“接口”理解为 OOP 中的接口,也可以理解为面向对象编程语言中的接口语法。那接口的设计要尽量单一,不要让接口的实现类和调用者,依赖不需要的接口函数。
DIP-依赖反转原则
全称:Dependency Inversion Principle
定义:高层模块不要依赖低层模块。高层模块和低层模块应该通过抽象来互相依赖。除此之外,抽象不要依赖具体实现细节,具体实现细节依赖抽象。大白话就是面向接口编程,依赖于抽象而不依赖于具体
理解:基于接口而非实现编程
KISS原则
关于KISS原则英文描述有好几个版本
Keep It Simple and Stupid.
Keep It Short and Simple.
Keep It Simple and Straightforward. 这几个描述的都差不多,大体意思就是:尽量保持简单。这是一个“万金油”的设计原则,它不光可以用在软件开发上,更加广泛的产品设计,系统设计例如冰箱,洗衣机都用到了这个原则。当时看乔布斯砖的时候,你会觉得他一直在践行这个原则。那么我们在开发中应该怎么践行这个原则呢
尽量不要使用同事可能不懂的技术来实现代码
不要重复造轮子,要善于使用已经有的工具类库
不要过度优化,不要过度使用一些奇技淫巧
YAGNI原则
YAGNI 原则的英文全称是:You Ain’t Gonna Need It。直译就是:你不会需要它。这条原则也算是万金油了。当用在软件开发中的时候,它的意思是:不要去设计当前用不到的功能;不要去编写当前用不到的代码。实际上,这条原则的核心思想就是:不要做过度设计。
DRY原则
它的英文描述为:Don’t Repeat Yourself。中文直译为:不要重复自己。将它应用在编程中,可以理解为:不要写重复的代码。看似简单,实际上我们工作中不自觉的写了大量重复的代码,比如
实现逻辑重复
功能语义重复
代码执行重复
迪米特法则
单从这个名字上来看,我们完全猜不出这个原则讲的是什么。不过,它还有另外一个更加达意的名字,叫作最小知识原则,英文翻译为:The Least Knowledge Principle。通俗的讲就是:不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口(也就是定义中的“有限知识”)。迪米特法则是实现高内聚,松耦合的法宝。那么什么是高内聚和松耦合呢?
所谓高内聚,就是指相近的功能应该放到同一个类中,不相近的功能不要放到同一个类中。相近的功能往往会被同时修改,放到同一个类中,修改会比较集中,代码容易维护。
所谓松耦合是说,在代码中,类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动不会或者很少导致依赖类的代码改动。
不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。迪米特法则是希望减少类之间的耦合,让类越独立越好。每个类都应该少了解系统的其他部分。一旦发生变化,需要了解这一变化的类就会比较少。
总结
说了这么多,我们应该熟练的掌握这些原则,有了这些原则我们才能明白后面的设计模式范式到底是遵循了什么思想,要解决什么问题。并且要时刻提醒自己,设计模式不是重点,写出高质量的代码才是我们要到达的彼岸。
设计模式与范式
设计模式分三个大类:创建型模式, 结构型模式,行为型模式
创建型设计模式
创建型模式中,单例模式,工厂模式(又分为简单工厂和抽象工厂),和原型模式是比较常用的,建造者模式用的不太多,了解下就好。
单例模式
单例设计模式(Singleton Design Pattern)理解起来非常简单。一个类只允许创建一个对象(或者实例),那这个类就是一个单例类,这种设计模式就叫作单例设计模式,简称单例模式。
单例模式的实现也比较简单,下面给出了两种实现方法
//方法一class GetSeetingConfig {static instance = nullconstructor() {console.log('new')}getConfig() {//...}static getInstance () {if (this.instance == void 0) {this.instance = new GetSeetingConfig()}return this.instance}}const seeting1 = GetSeetingConfig.getInstance()const seeting2 = GetSeetingConfig.getInstance()//两次只打印一次newseeting1 === seeting2 // true//方法二class GetSeetingConfig {constructor() {console.log('new')}getConfig() {//...}}GetSeetingConfig.getInstance = (function() {let instancereturn function() {if (!instance){instance = new GetSeetingConfig()}return instance}})()const seeting1 = GetSeetingConfig.getInstance()const seeting2 = GetSeetingConfig.getInstance()//两次只打印一次newseeting1 === seeting2 // true
优点:
单例模式能保证全局的唯一性,可以减少命名变量
单例模式在一定情况下可以节约内存,减少过多的类生成需要的内存和运行时间
把代码都放在一个类里面维护,实现了高内聚
缺点:
单例对 OOP 特性的支持不友好
单例对抽象、继承、多态都支持的不太好
单例会隐藏类之间的依赖关系
单例对代码的可测试性不友好
单例不支持有参数的构造函数
经典场景:
模态框
状态管理库(Redux,mobx,Vuex)中的store
工厂模式
我们从字面意思上来理解工厂,对于消费者来说,我们不关心你的生产流程,关心的是最终的产品。
所以为了让代码逻辑更加清晰,可读性更好,我们要善于将功能独立的代码块进行封装一个职责单一的类或者模块,这种基于抽象的思维就是工厂模式的来源。
工厂模式又分为简单工厂模式,工厂方法模式和抽象工厂模式。
简单工厂模式
//简单工厂模式class User {constructor(role, name) {this.name = name;this.role = role}}class Admin {constructor(role, name) {this.name = name;this.role = role}}class SuperAdmin {constructor(role, name) {this.name = name;this.role = role}}class RoleFactory {static createUser(role) {if (role === 'user') {return new User(role,'用户')} else if (role === 'admin') {return new Admin(role, '管理员')} else if (role === 'superadmin') {return new SuperAdmin(role, '超级管理员')}}}const user = RoleFactory.createUser('user'')
简单工厂的优点在于,你只需要一个正确的参数,就可以获取到你所需要的对象,而无需知道其创建的具体细节。但是当内部逻辑变得很复杂这个函数将会变得很庞大并且难以维护。
工厂方法模式
所以当一个简单工厂变得过于复杂时,我们可以考虑用工厂方法来代替它。工厂方法的核心是将实际创建对象的工作推迟到子类中。
class UserFactory {constructor(role, name) {this.name = name;this.role = role;}init() {//我们可以把简单工厂中复杂的代码都拆分到每个具体的类中// code here//...return new User(this.role, this.name)}}class AdminFactory {constructor(role, name) {this.name = name;this.role = role;}init() {//我们可以把简单工厂中复杂的代码都拆分到每个具体的类中// code here//...return new Admin(this.role, this.name)}}class SuperAdminFactory {constructor(role, name) {this.name = name;this.role = role;}init() {//我们可以把简单工厂中复杂的代码都拆分到每个具体的类中// code here//...return new SuperAdmin(this.role, this.name)}}class RoleFactory {static createUser(role) {if (role === 'user') {return new UserFactory(role,'用户')} else if (role === 'admin') {return new AdminFactory(role, '管理员')} else if (role === 'superadmin') {return new SuperAdminFactory(role, '超级管理员')}}}const user = RoleFactory.createUser('user'')
那什么时候该用工厂方法模式,而非简单工厂模式呢?
之所以将某个代码块剥离出来,独立为函数或者类,原因是这个代码块的逻辑过于复杂,剥离之后能让代码更加清晰,更加可读、可维护。但是,如果代码块本身并不复杂,就几行代码而已,我们完全没必要将它拆分成单独的函数或者类。基于这个设计思想,当对象的创建逻辑比较复杂,不只是简单的 new 一下就可以,而是要组合其他类对象,做各种初始化操作的时候,我们推荐使用工厂方法模式,将复杂的创建逻辑拆分到多个工厂类中,让每个工厂类都不至于过于复杂。而使用简单工厂模式,将所有的创建逻辑都放到一个工厂类中,会导致这个工厂类变得很复杂。
抽象工厂模式
在简单工厂和工厂方法中,类只有一种分类方式。上面的例子中我们根据用和的角色来划分的,但是如果根据业务需要,我们也需要对用户注册时用的手机号或者邮箱也要进行划分的话。如果用工厂方法我们就需要上面三种每种又分为手机号或邮箱的工厂,总共9中,要是再增加一种分类形式,我们可以发现它是指数型增长的趋势。我们的工厂总有一天会爆炸的。抽象工厂就是针对这种非常特殊的场景而诞生的。我们可以让一个工厂负责创建多个不同类型的对象,而不是只创建一种对象。这样就可以有效地减少工厂类的个数。
class Factory {createUserParser(){thorw new Error('抽象类只能继承,不能实现')}createLoginParser(){thorw new Error('抽象类只能继承,不能实现')}}class UserParser extends Factory {createUserParser(role, name) {return new UserFactory(role, name)}createLoginParser(type) {if (type === 'email'){return new UserEmail()} else if (type === 'phone') {return new UserPhone()}}}class AdminParser extends Factory {createUserParser(role, name) {return new AdminFactory(role, name)}createLoginParser(type) {if (type === 'email'){return new AdminEmail()} else if (type === 'phone') {return new AdminPhone()}}}class SuperAdminParser extends Factory {createUserParser(role, name) {return new SuperAdminFactory(role, name)}createLoginParser(type) {if (type === 'email'){return new SuperAdminEmail()} else if (type === 'phone') {return new SuperAdminPhone()}}}
总结
除了刚刚提到的这几种情况之外,如果创建对象的逻辑并不复杂,那我们就直接通过 new 来创建对象就可以了,不需要使用工厂模式。
现在,我们上升一个思维层面来看工厂模式,它的作用无外乎下面这四个。这也是判断要不要使用工厂模式的最本质的参考标准。
封装变化:创建逻辑有可能变化,封装成工厂类之后,创建逻辑的变更对调用者透明。
代码复用:创建代码抽离到独立的工厂类之后可以复用。
隔离复杂性:封装复杂的创建逻辑,调用者无需了解如何创建对象。
控制复杂度:将创建代码抽离出来,让原本的函数或类职责更单一,代码更简洁。
建造者模式
将一个复杂的对象分解成多个简单的对象来进行构建,将复杂的构建层与表示层分离,使得相同的构建过程可以创建不同的表示的模式便是建造者模式。
这样说还是有点抽象,我们来看一个具体的例子,比如我们要创建一个CaKe类,这个类需要传name,color, shape,sugar这四个参数。这当然难不倒我们,只需要
class Cake {constructor(name, color, shape, suger) {this.name = name;this.color = color;this.shape = shape;this.suger = suger;}}new Cake('cake', 'white', 'circle', '30%')
现在,Cake 只有 4 个可配置项,对应到构造函数中,也只有 4 个参数,参数的个数不多。但是,如果可配置项逐渐增多,变成了 8 个、10 个,甚至更多,那继续沿用现在的设计思路,构造函数的参数列表会变得很长,代码在可读性和易用性上都会变差。在使用构造函数的时候,我们就容易搞错各参数的顺序,传递进错误的参数值,导致非常隐蔽的 bug。
这个时候,我们还有一个方法,就是给每个属性添加set方法,将必填的属性放到构造函数中,不是必填的向外暴露set方法,让使用者选择自主填写或者不填写。(比如我们的name和color是必填的,其余不必填)
class Cake {consotructor(name, color) {this.name = name;this.color = color;}validName() {if(this.name == void 0) {console.log('name should not empty')return false}return true}validColor() {if (this.color == void 0) {console.log('color should not empty')true}return true}setShape(shape) {if (this.validName() && this.validColor()) {this.shape = shape;}}setSugar(sugar) {if (this.validName() && this.validColor()) {this.sugar = sugar;}}//...}
至此,我们仍然没有用到建造者模式,通过构造函数设置必填项,通过 set() 方法设置可选配置项,就能实现我们的设计需求。但是我们再增加一下难度
必填的配置项有很多,把这些必填配置项都放到构造函数中设置,那构造函数就又会出现参数列表很长的问题。
如果配置项之间有一定的依赖关系,比如我们加一个iSuger属性,当为true时,必须设置suger属性,或者我们加一个cakeSize和boxSize,cakeSize要始终小于boxSize。如果我们继续使用现在的设计思路,那这些配置项之间的依赖关系或者约束条件的校验逻辑就无处安放了。
还有如果我们希望Cake是一个不可变的对象,也就是说,对象在创建好之后,就不能再修改内部的属性值。要实现这个功能,我们就不能在 Cake 类中暴露 set() 方法。为了解决这些问题,建造者模式就派上用场了。
class Cake {constructor(name, color, shape, suger) {this.name = name;this.color = color;this.shape = shape;this.suger = suger;}}class CakeBuilder {valid() {//valid all params...}setName() {this.valid()//...return this;}setColor() {this.valid()//...return this;}setShage() {this.valid()//...return this;}setSuger() {this.valid()//...return this;}build() {const cake = new Cake()cake.shape = this.setShape()cake.suger = this.setSuger()cake.name = this.setName()cake.color = this.setColor()return cake}}const cake1 = new CakeBuilder().setName('cake').setColor('yellow').setShape('heart').setSugar('70%').builder()//我们还可以把这长长的链式调用封装起来,也就是指导者function diractor(builder) {return builder.setName('cake').setColor('yellow').setShape('heart').setSugar('70%').builder()}const cakeBuilder = new CakeBuilder()const cake2 = diractor(cakeBuilder)
Cake类中的成员变量,要在 Builder 类中重新再定义一遍,可以看出,建造者模式的使用有且只适合创建极为复杂的对象。在前端的实际业务中,在没有这类极为复杂的对象的创建时,还是应该直接使用对象字面或工厂模式等方式创建对象。
原型模式
如果对象的创建成本比较大,而同一个类的不同对象之间差别不大(大部分字段都相同),在这种情况下,我们可以利用对已有对象(原型)进行复制(或者叫拷贝)的方式来创建新对象,以达到节省创建时间的目的。这种基于原型来创建对象的方式就叫作原型设计模式(Prototype Design Pattern),简称原型模式。
class Person {constructor(name) {this.name = name}getName() {return this.name}}class Student extends Person {constructor(name) {super(name)}sayHello() {console.log(`Hello, My name is ${this.name}`)}}let student = new Student("xiaoming")student.sayHello()
对于前端程序员来说,原型模式是一种比较常用的开发模式。这是因为,有别于 Java、C++ 等基于类的面向对象编程语言,javascript 是一种基于原型的面向对象编程语言。即便 JavaScript 现在也引入了类的概念,但它也只是基于原型的语法糖而已。
结构型设计模式
结构型模式又分为7类,其中代理模式,装饰者模式,适配器模式和桥接模式用的比较多。
代理模式
代理模式(Proxy Design Pattern)的原理和代码实现都不难掌握。它在不改变原始类(或叫被代理类)代码的情况下,通过引入代理类来给原始类附加功能。代理模式在前端中比较常用的虚拟代理和缓存代理。
虚拟代理
我们用虚拟代理来实现一个图片的懒加载
class MyImg {static imgNode = document.createElement("img")constructor(selector) {selector.appendChild(this.imgNode);}setSrc(src) {this.imgNode = src}}const img = new MyImg(document.body)img.setSrc('xxx')
先看一下上面这段代码,定义了一个MyImg类,接收一个选择器,然后在这个选择器下面创建一个img标签并且暴露一个setSrc方法。
如果网速慢,图片又非常大的话,拿这个标签的占位刚开始是白屏的。所以我们会用到图片预加载的方式。
虚拟代理的特点是,代理类和真正的类都暴露了痛仰的接口,这样对于调用者来说是无感的。
class ProxyMyImg {static src = 'xxx本地预览图地址loading.gif'constructor(selector) {this.img = new Imagethis.myImg = new MyImg(selector)this.myImg.setSrc(this.src)}setSrc(src) {this.img.src = srcthis.img.onload = () => {this.myImg.setSrc(src)}}}const img = new ProxyMyImg(document.body)img.setSrc('xxx')
ProxyMyImg控制了客户对MyImg的访问,并且在此过程中加入一些额外的操作,比如在图片加载好之前,先把img节点的src设置为一张本地的loading图片。
这样做的好处是把添加img节点和设置预加载给解耦了,每个类都去一个任务,这是符合单一职责原则的。如果有一天网速足够快了,完全不需要预加载,我们直接去掉代理就可以了,这也是符合开闭原则的。
缓存代理
缓存代理可以为一些开销大的运算结果提供暂时的缓存,在下次运算时,如果传递进来的参数跟之前一致,则可以直接返回缓存好的运算结果。
比如我们有一个计算乘积的函数
const mult = (...args) => {console.log('multing...')let res = 1args.forEach(item => {res*=item})return item}mult(2,3) //6mult(2,3,5)//30
加入缓存代理函数
const mult = (...args) => {console.log('multing...')let res = 1args.forEach(item => {res*=item})return res}const proxyMult = (() => {const cache = {}return (...args) => {const key = [].join.call(args, ',')if (key in cache) {return cache[args]}return cache[key] = mult.apply(null, args)}})()proxyMult(1,2,3,4)// multing... 24proxyMult(1,2,3,4)//24
Proxy
ES6新增了代理类Proxy
语法
const p = new Proxy(target, handler)
target 要使用 Proxy 包装的目标对象(可以是任何类型的对象,包括原生数组,函数,甚至另一个代理)。
handler 一个通常以函数作为属性的对象,各属性中的函数分别定义了在执行各种操作时代理 p 的行为。
关于更多的详情请看developer.mozilla.org/zh-CN/docs/…
下面我们用Proxy来实现一下缓存代理的例子
const mult = (args) => {console.log('multing...')let res = 1args.forEach(item => {res*=item})return res}const handler = {cache: {},apply: function(target, thisArg, args) {const key = [].join.call(args, ',')if(key in this.cache) {return this.cache[key]}return this.cache[key] = target(args)}}const proxyMult = new Proxy(mult, handler)proxyMult(1,2,3,4)//multing...//24proxyMult(1,2,3,4)//24
装饰者模式
装饰者模式可以动态地给某个对象添加一些额外的职责,而不会影响从这个类中派生的其他对象。
class Plan {fire() {console.log('发射子弹')}}class PlanDecorator {constructor(plan) {this.plan = plan}fire() {this.plan.fire()console.log('发射导弹')}}const plan = new Plan()const newPlan = new PlanDecorator(plan)newPlan.fire() //发射子弹 发射导弹
如果你熟悉TypeScript,那么他的代码结构就是这样的
interface IA {init: () => void}class A implements IA {public init() {//...}}class ADecorator implements IA {constructor (a: IA) {this.a = a}init() {// 功能增强代码a.init()// 功能增强代码}}
著名的AOP就是通过装饰者模式来实现的
before
Function.prototype.before = function(beforeFn) {const _this = this //保存原函数的引用return function() {// 返回包含了原函数和新函数的"代理函数"beforeFn.apply(this, arguments)// 执行新函数,修正thisreturn _this.apply(this, arguments) // 执行原函数并返回原函数的执行结果,this不被劫持}}
after
Function.prototype.after = function(afterFn) {const _this = thisreturn function() {const res = _this.apply(this, arguments)afterFn.apply(this, arguments)return res}}
around(环绕通知)
Function.prototype.around = function(beforeFn, aroundFn) {const _this = thisreturn function () {return _this.before(beforeFn).after(aroundFn).apply(this, arguments)// 利用之前写的before 和after 来实现around}}
测试
const log = (val) => {console.log(`日志输出${val}`)}const beforFn = () => {console.log(`日志输出之前先输出${new Date().getTime()}`)}const afterFn = () => {console.log(`日志输出之前再输出${new Date().getTime()}`)}const preLog = log.before(beforFn)const lastLog = log.after(afterFn)const aroundLog = log.around(beforeFn, afterFn)preLog(11)lastLog(22)aroundLog(33)
当AOP遇到装饰器
ES7中增加了对装饰器的支持,它就是用来修改类的行为,或者增强类,这使得在js中使用装饰者模式变得更便捷
class User {@checkLogingetUserInfo() {console.log('获取用户信息')}}// 检查用户是否登录function checkLogin(target, name, descriptor) {let method = descriptor.valuedescriptor.value = function (...args) {// 校验方法,假设这里可以获取到用户名/密码if (validate(args)) {method.apply(this, args)} else {console.log('没有登录,即将跳转到登录页面...')}}}let user = new User()user.getUserInfo()
还有比较典型的在React中的高阶组件
function HOCDecorator(WrappedComponent){return class HOC extends Component {render(){const newProps = {param: 'HOC'};return <div><WrappedComponent {...this.props} {...newProps}/></div>}}}@HOCDecoratorclass OriginComponent extends Component {render(){return <div>{this.props.param}</div>}}
如果你熟悉mobx的话,你会发现里面的功能都支持装饰器,当然我们也可以在Redux中使用装饰器来实现connect函数,这都是很方便的。具体可以看阮一峰老师的讲解 es6.ruanyifeng.com/#docs/decor…
适配器模式
适配器模式的英文翻译是 Adapter Design Pattern。顾名思义,这个模式就是用来做适配的,它将不兼容的接口转换为可兼容的接口,让原本由于接口不兼容而不能一起工作的类可以一起工作。对于这个模式,有一个经常被拿来解释它的例子,就是 USB 转接头充当适配器,把两种不兼容的接口,通过转接变得可以一起工作。
class GooleMap {show() {console.log('渲染地图')}}class BaiduMap {display() {console.log('渲染地图')}}class GaodeMap {show() {console.log('渲染地图')}}// 上面三个类,如果我们用多态的思想去开发的话是很难受的,所以我们通过适配器来统一接口class BaiduAdaapterMap {show() {return new BaiduMap().display()}}
所以适配器模式应用场景一般为
统一多个类的接口设计
替换依赖的外部系统
兼容老版本接口
适配不同格式的数据
桥接模式
举个很简单的例子,现在有两个纬度 Car 车 (奔驰、宝马、奥迪等) Transmission 档位类型 (自动挡、手动挡、手自一体等) 按照继承的设计模式,Car是一个基类,假设有M个车品牌,N个档位一共要写 M乘N 个类去描述所有车和档位的结合。而当我们使用桥接模式的话,我首先new一个具体的Car(如奔驰),再new一个具体的Transmission(比如自动档)。那么这种模式只有M+N个类就可以描述所有类型,这就是M乘N的继承类爆炸简化成了M+N组合。
class Car {constructor(brand) {this.brand = brand}speed() {//...}}class Transmission {constructor(trans) {this.trans = trans}action() {...}}class AbstractCar {constructor(car, transmission) {this.car = carthis.transmission}run () {this.car.speed()this.traansmission.action()//...}}
门面模式
门面模式,也叫外观模式,英文全称是 Facade Design Pattern。在 GoF 的《设计模式》一书中,门面模式是这样定义的:门面模式为子系统提供一组统一的接口,定义一组高层接口让子系统更易用。
假设有一个系统 A,提供了 a、b、c、d 四个接口。系统 B 完成某个业务功能,需要调用 A 系统的 a、b、d 接口。利用门面模式,我们提供一个包裹 a、b、d 接口调用的门面接口 x,给系统 B 直接使用。
如果是后台同学的话,说明接口粒度太细了,我们可以要求其将abd接口封装为一个接口供我们使用,这会提高一部分性能。但是由于各种原因后台不改,我们也可以将abd接口封装在一起,这也使得我们的代码具有高内聚,低耦合的特性。
举个最简单的例子
const myEvent = {// ...stop: e => {e.stopPropagation();e.preventDefault();}}
组合模式
组合模式的定义:将一组对象组织(Compose)成树形结构,以表示一种“部分 - 整体”的层次结构。组合模式的应用前提是他的数据需要是树形结构。
假设我们有这样一个需求:设计一个类来表示文件系统中的目录,能方便地实现下面这些功能:
动态地添加、删除某个目录下的子目录或文件
统计指定目录下的文件个数
统计指定目录下的文件总大小
class FileSystemNode {constructor(path) {this.path = path}countNumOfFiles() {}countSizeOfFiles() {}getPath() {return this.path}}class File extends FileSystemNode {constructor(path) {super(path)}countNumOfFiles () {return 1}countSizeOfFiles() {//利用NodejsApi通过路径获取文件...}}class Directory extends FileSystemNode{constructor(path) {super(path)this.fileList = []}countNumOfFiles () {//...}countSizeOfFiles() {//...}addSubNode(fileOrDir) {this.fileList.push(fileOrDir)}removeSubNode(fileOrDir) {return this.fileList.filter(item => item !== fileOrDir)}}//如果我们要表示/***/*/leon*/leon/aa.txt*/leon/bb*/leon/bb/cc.jsconst root = new Directory('/')const dir_leon = new Directory('/leon/')root.addSubNode(leon)const file_aa = new File('/leon/aa.txt')const dir_bb = new Directory('leon/bb')dir_leon.addSubNode(file_aa)dir_leon.addSubNode(dir_bb)const file_cc = new File('/leon/bb/cc.js')dir_bb.addSubNode(file_cc)
组合模式不好的一点是有可能一不小心就创建了大量的对象而降低性能或难以维护,所以我们接下来讲的享元模式就是用来解决这个问题的。
享元模式
所谓“享元”,顾名思义就是被共享的单元。享元模式的意图是复用对象,节省内存,前提是享元对象是不可变对象。
定义中的“不可变对象”指的是,一旦通过构造函数初始化完成之后,它的状态(对象的成员变量或者属性)就不会再被修改了。所以,不可变对象不能暴露任何 set() 等修改内部状态的方法。
具体来讲,当一个系统中存在大量重复对象的时候,如果这些重复的对象是不可变对象,我们就可以利用享元模式将对象设计成享元,在内存中只保留一份实例,供多处代码引用。这样可以减少内存中对象的数量,起到节省内存的目的。实际上,不仅仅相同对象可以设计成享元,对于相似对象,我们也可以将这些对象中相同的部分(字段)提取出来,设计成享元,让这些大量相似对象引用这些享元。
我们来看个例子,假如要做一个简单的富文本编辑器(只需要记录文字和格式)。
class CharacterStyle{constructor(font, size, color) {this.font = fontthis.size = sizethis.color = color}equals(obj) {return this.font === obj.font&& this.size === obj.size&& this.color = obj.color}}class CharacterStyleFactory {static styleList = []getStyle(font, size, color) {const newStyle = new CharacterStyle(font, size, color)for(let i = 0, style; style = this.styleList[i++];) {if (style.equals(newStyle)) {return style}}CharacterStyleFactory.styleList.push(newStyle)return newStyle}}class Character {constructor(c, style) {this.c = cthis.style = style}}class Editor {static chars = []appendCharacter(c, font, size, color) {const style = CharacterStyleFactory.getStyle(font, size, color)const character = new Character(c, style)Editor.chars.push(character)}}
如果我们不把样式提取出来,我们每敲一个文字,都会调用 Editor 类中的 appendCharacter() 方法,创建一个新的 Character 对象,保存到 chars 数组中。如果一个文本文件中,有上万、十几万、几十万的文字,那我们就要在内存中存储这么多 Character 对象。那有没有办法可以节省一点内存呢?实际上,在一个文本文件中,用到的字体格式不会太多,毕竟不大可能有人把每个文字都设置成不同的格式。所以,对于字体格式,我们可以将它设计成享元,让不同的文字共享使用。
行为型设计模式
观察者模式
观察者模式(Observer Design Pattern)也被称为发布订阅模式(Publish-Subscribe Design Pattern),在对象之间定义一个一对多的依赖,当一个对象状态改变的时候,所有依赖的对象都会自动收到通知。
一般情况下,被依赖的对象叫作被观察者(Observable),依赖的对象叫作观察者(Observer)。不过,在实际的项目开发中,这两种对象的称呼是比较灵活的,有各种不同的叫法,比如:Subject-Observer、Publisher-Subscriber、Producer-Consumer、EventEmitter-EventListener、Dispatcher-Listener。不管怎么称呼,只要应用场景符合刚刚给出的定义,都可以看作观察者模式。
我们下面实现一个简单但是最经典的实现方式。先通过模板模式的思想把基类写出来
class Subject {registerObserver() {throw new Error('子类需重写父类的方法')}removeObserver() {throw new Error('子类需重写父类的方法')}notifyObservers() {throw new Error('子类需重写父类的方法')}}class Observer{update() {throw new Error('子类需重写父类的方法')}}
然后根据模板来具体的实现
class ConcreteSubject extends Subject {static observers = []registerObserver(observer) {ConcreteSubject.observers.push(observer)}removeObserver(observer) {ConcreteSubject.observers = ConcreteSubject.observers.filter(item => item !== oberser)}notifyObservers(message) {for(let i = 0,observer; observer = ConcreteSubject.observers[i++];) {observer.update(message)}}}class ConcreteObserverOne extends Observer {update(message) {//TODO 获得消息通知,执行自己的逻辑console.log(message)//...}}class ConcreteObserverTwo extends Observer {update(message) {//TODO 获得消息通知,执行自己的逻辑console.log(message)//...}}class Demo {constructor() {const subject = new ConcreteSubject()subject.registerObserver(new ConcreteObserverOne())subject.registerObserver(new ConcreteObserverTwo())subject.notifyObservers('copy that')}}const demo = new Demo()
事实上,上面只是给出了一个大体的原理和思路,实际中的观察者模式要复杂的多,比如你要考虑同步阻塞或异步非阻塞的问题,命名空间的问题,还有必须要先注册再发布吗?而且项目中用了大量的观察者模式的话会导致增加耦合性,降低内聚性,使项目变得难以维护。
模板模式
模板方法模式在一个方法中定义一个算法骨架,并将某些步骤推迟到子类中实现。模板方法模式可以让子类在不改变算法整体结构的情况下,重新定义算法中的某些步骤。
这里的“算法”,我们可以理解为广义上的“业务逻辑”,并不特指数据结构和算法中的“算法”。这里的算法骨架就是“模板”,包含算法骨架的方法就是“模板方法”,这也是模板方法模式名字的由来。
比如说我们要做一个咖啡机的程序,可以通过程序设定帮我们做出各种口味的咖啡,它的过程大概是这样的
加入浓缩咖啡
加糖
加奶
加冰
加水
有可能有的你不需要加,那我们可以写一个hook来控制各个变量,比如我们下面给是否加冰加一个hook
class Tea {addCoffee() {console.log('加入咖啡')}addSuger() {throw new Error('子类需重写父类的方法')}addMilk() {throw new Error('子类需重写父类的方法')}addIce() {console.log('加入冰块')}isIce() {return false // 默认不加冰}addWater() {console.log('加水')}init() {this.addCoffee()this.addSuger()this.addMilk()if (this.isIce()) {this.addIce()}}}
模板写好了,我们接下来做一杯拿铁
class Latte extends Tea {addSuger() {console.log('加糖')}addMilk() {console.log('加奶')}isIce() {return true}}const ice_latte = new Latte()ice_latte.init()
我们可以看到,我们不仅在父类中封装了子类的算法框架,还将一些不会变化的方法在父类中实现,这样子类就直接继承就可以了。其实,之前讲组合模式的时候,也有用到了模板方法模式,你可以回头看一眼。
这也是我们讲设计原则的时候讲到的要基于接口而非实现编程,你可以把他理解为基于抽象而非实现编程。所以开发前,要做好设计,会让我们事半功倍。
js去写模板还是有一丢丢问题的,比如我们在父类中某些方法里面抛出错误的方法虽然能实现但是不美观,如果你熟悉Ts的话,那就很好办了,你可以去写一个抽象类,子类去实现这个抽象类,或者规定接口(interface),父类和子类都基于接口去编程,有兴趣的可以自己实现一下。
策略模式
策略模式,英文全称是 Strategy Design Pattern。定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式可以使算法的变化独立于使用它们的客户端(这里的客户端代指使用算法的代码)。
我们知道,工厂模式是解耦对象的创建和使用,观察者模式是解耦观察者和被观察者。策略模式跟两者类似,也能起到解耦的作用,不过,它解耦的是策略的定义、创建、使用这三部分。
策略的定义
// 因为所有的策略类都实现相同的接口,所以我们可以通过模板来定义class Strategy {algorithmInterface() {}}class ConcreteStrategyA extends Strategy {algorithmInterface() {//具体的实现//...}}class ConcreteStrategyB extends Strategy {algorithmInterface() {//具体的实现//...}}//...
策略的创建
因为策略模式会包含一组策略,在使用它们的时候,一般会通过类型(type)来判断创建哪个策略来使用。为了封装创建逻辑,我们需要对客户端代码屏蔽创建细节。我们可以把根据 type 创建策略的逻辑抽离出来,放到工厂类中。
class StrategyFactory {strategies = new Map()constructor () {this.strategies.set("A", new ConcreteStrategyA())this.strategies.set("B", new ConcreteStrategyB())//...}getStrategy(type) {return type && this.strategies.get(type)}}
在实际的项目开发中,这个模式比较常用。最常见的应用场景是,利用它来避免冗长的 if-else 或 switch 分支判断。不过,它的作用还不止如此。它也可以像模板模式那样,提供框架的扩展点等等。
职责链模式
职责链模式的英文翻译是 Chain Of Responsibility Design Pattern。将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。
通俗的讲就是在职责链模式中,多个处理器(也就是刚刚定义中说的“接收对象”)依次处理同一个请求。一个请求先经过 A 处理器处理,然后再把请求传递给 B 处理器,B 处理器处理完后再传递给 C 处理器,以此类推,形成一个链条。链条上的每个处理器各自承担各自的处理职责,所以叫作职责链模式。
职责链的实现方式有两种,我们先来看一种理解起来简单的,HandlerChain 类用数组来保存所有的处理器,并且需要在 HandlerChain 的 handle() 函数中,依次调用每个处理器的 handle() 函数。
class IHandler {handle() {throw new Error('子类需重写这个方法')}}class HandlerA extends IHandler {handle() {let handled = false//...return handled}}class HandlerB extends IHandler {handle() {let handled = false//...return handled}}class HandlerChain {handles = []addHandle(handle) {this.handles.push(handle)}handle() {this.handles.for(let i= 0, handler; handler = this.handles[i++];) {handled = handler.handle()if (handle) {break}}}}const chain = new HandlerChain()chain.addHandler(new HandlerA())chain.addHandler(new HandlerB())chain.handle()
第二种方法用到了链表的实现方式
class Handler {successor = nullsetSuccessor(successor) {this.successor = successor}handle() {const isHandle = this.doHandle()if (!isHandle && !!this.successor) {this.successor.handle}}doHandle() {throw new Error('子类需重写这个方法')}}class HandlerA extends Handler {doHandle() {let handle = false//...return handle}}class HandlerB extends Handler {doHandle() {let handle = false//...return handle}}class HandlerChain {head = nulltail = nulladdHandler(handler) {handler.setSuccessor(null)if (head === null) {head = handlertail = handlerreturn}tail.setSuccessor(handler)tail = handler}handle() {if (!!head) {head.handle()}}}const chain = new HandlerChain()chain.addHandler(new HandlerA())chain.addHandler(new HandlerB())chain.handle()
还记得我们之前说装饰者模式说到的AOP吗,我们可以把它稍微改造一下,也可以变成职责链的方式。
Function.prototype.after = function(afterFn) {let self = thisreturn function() {let res = self.apply(this, arguments)if (res === false) {afterFn.apply(this, arguments)}return ret}}const res = fn.after(fn1).after(fn2).after(fn3)
可以看出我们传进去的afterFn函数如果返回false的话,会连着这条链一直传下去,直到最后一个,一旦返回true,就不会将请求往后传递了。
迭代器模式
迭代器模式,也叫游标模式。它用来遍历集合对象。这里说的“集合对象”,我们也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如,数组、链表、树、图、跳表。
一个完整的迭代器模式,一般会涉及容器和容器迭代器两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。容器中需要定义 iterator() 方法,用来创建迭代器。迭代器接口中需要定义 hasNext()、currentItem()、next() 三个最基本的方法。容器对象通过依赖注入传递到迭代器类中。
class ArrayIterator {constructor( arrayList) {this.cursor = 0this.arrayList = arrayList}hasNext() {return this.cursor !== this.arrayList.length}next() {this.cursor++}currentItem() {if(this.cursor > this.arrayList.length) {throw new Error('no such ele')}return this.arrayList[this.cursor]}}
在上面的代码实现中,我们需要将待遍历的容器对象,通过构造函数传递给迭代器类。实际上,为了封装迭代器的创建细节,我们可以在容器中定义一个 iterator() 方法,来创建对应的迭代器。为了能实现基于接口而非实现编程,我们还需要将这个方法定义在 ArrayList 接口中。具体的代码实现和使用示例如下所示:
class ArrayList {constructor(arrayList) {this.arrayList = arrayList}iterator() {return new ArrayIterator(this.arrayList)}}const names = ['lee', 'leon','qing','quene']const arr = new ArrayList(names)const iterator = arr.iterator()iterator.hasNext()iterator.currentItem()iterator.next()iterator.currentItem()
上面我们只实现了数组的迭代器,关于对象的迭代器,他们的原理差不多,你可以自己去实现以下。
相对于 for 循环遍历,利用迭代器来遍历有下面三个优势:
迭代器模式封装集合内部的复杂数据结构,开发者不需要了解如何遍历,直接使用容器提供的迭代器即可;
迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一;
迭代器模式让添加新的遍历算法更加容易,更符合开闭原则。除此之外,因为迭代器都实现自相同的接口,在开发中,基于接口而非实现编程,替换迭代器也变得更加容易。
状态模式
状态模式一般用来实现状态机,而状态机常用在游戏、工作流引擎等系统开发中。不过,状态机的实现方式有多种,除了状态模式,比较常用的还有分支逻辑法和查表法。
“超级马里奥”游戏不知道你玩过没有?在游戏中,马里奥可以变身为多种形态,比如小马里奥(Small Mario)、超级马里奥(Super Mario)、火焰马里奥(Fire Mario)、斗篷马里奥(Cape Mario)等等。在不同的游戏情节下,各个形态会互相转化,并相应的增减积分。比如,初始形态是小马里奥,吃了蘑菇之后就会变成超级马里奥,并且增加 100 积分。
实际上,马里奥形态的转变就是一个状态机。其中,马里奥的不同形态就是状态机中的“状态”,游戏情节(比如吃了蘑菇)就是状态机中的“事件”,加减积分就是状态机中的“动作”。比如,吃蘑菇这个事件,会触发状态的转移:从小马里奥转移到超级马里奥,以及触发动作的执行(增加 100 积分)。
为了方便接下来的讲解,我对游戏背景做了简化,只保留了部分状态和事件。简化之后的状态转移如下图所示:
class MariostateMachine {constructor() {this.score = 0this.currentState = new SmallMario(this)}obtainMushRoom() {this.currentState.obtainMushRoom()}obtainCape() {this.currentState.obtainCape()}obtainFireFlower() {this.currentState.obtainFireFlower()}meetMonster() {this.currentState.meetMonster()}getScore() {return this.score}getCurrentState() {return this.currentState}setScore(score) {this.score = score}setCurrentState(currentState) {this.currentState = currentState}}class Mario {getName() {}obtainMushRoom() {}obtainCape(){}obtainFireFlower(){}meetMonster(){}}class SmallMario extends Mario {constructor(stateMachine) {super()this.stateMachine = stateMachine}obtainMushRoom() {this.stateMachine.setCurrentState(new SuperMario(this.stateMachine))this.stateMachine.setScore(this.stateMachine.getScore() + 100)}obtainCape() {this.stateMachine.setCurrentState(new CapeMario(this.stateMachine))this.stateMachine.setScore(this.stateMachine.getScore() + 200)}obtainFireFlower() {this.stateMachine.setCurrentState(new FireMario(this.stateMachine))this.stateMachine.setScore(this.stateMachine.getScore() + 300)}meetMonster() {// do something}}class SuperMario extends Mario {constructor(stateMachine) {super()this.stateMachine = stateMachine}obtainMushRoom() {// do nothing...}obtainCape() {this.stateMachine.setCurrentState(new CapeMario(this.stateMachine))this.stateMachine.setScore(this.stateMachine.getScore() + 200)}obtainFireFlower() {this.stateMachine.setCurrentState(new FireMario(this.stateMachine))this.stateMachine.setScore(this.stateMachine.getScore() + 300)}meetMonster() {this.stateMachine.setCurrentState(new SmallMario(this.stateMachine))this.stateMachine.setScore(this.stateMachine.getScore() - 100)}}//CapeMario FireMario格式相同//使用const mario = new MarioStateMachine()mario.obtainMushRoom()mario.getScore()
MarioStateMachine 和各个状态类之间是双向依赖关系。MarioStateMachine 依赖各个状态类是理所当然的,但是,反过来,各个状态类为什么要依赖 MarioStateMachine 呢?这是因为,各个状态类需要更新 MarioStateMachine 中的两个变量,score 和 currentState。
状态模式的代码实现还存在一些问题,比如,状态接口中定义了所有的事件函数,这就导致,即便某个状态类并不需要支持其中的某个或者某些事件,但也要实现所有的事件函数。不仅如此,添加一个事件到状态接口,所有的状态类都要做相应的修改。
中介模式
中介模式定义了一个单独的(中介)对象,来封装一组对象之间的交互。将这组对象之间的交互委派给与中介对象交互,来避免对象之间的直接交互。
实际上,中介模式的设计思想跟中间层很像,通过引入中介这个中间层,将一组对象之间的交互关系(或者说依赖关系)从多对多(网状关系)转换为一对多(星状关系)。原来一个对象要跟 n 个对象交互,现在只需要跟一个中介对象交互,从而最小化对象之间的交互关系,降低了代码的复杂度,提高了代码的可读性和可维护性。
提到中介模式,有一个比较经典的例子不得不说,那就是航空管制。
为了让飞机在飞行的时候互不干扰,每架飞机都需要知道其他飞机每时每刻的位置,这就需要时刻跟其他飞机通信。飞机通信形成的通信网络就会无比复杂。这个时候,我们通过引入“塔台”这样一个中介,让每架飞机只跟塔台来通信,发送自己的位置给塔台,由塔台来负责每架飞机的航线调度。这样就大大简化了通信网络。
下面我们用代码实现以下:
class A {constructor() {this.number = 0}setNumber(num, m) {this.number = numif (m) {m.setB()}}}class B {constructor() {this.number = 0}setNumber(num, m) {this.number = numif (m) {m.setA()}}}class Mediator {constructor(a, b) {this.a = athis.b = b}setA() {let number = this.b.numberthis.a.setNumber(number * 10)}setB() {let number = this.a.numberthis.b.setNumber(number / 10)}}let a = new A()let b = new B()let m = new Mediator(a, b)a.setNumber(10, m)console.log(a.number, b.number)b.setNumber(10, m)console.log(a.number, b.number)
访问者模式
允许一个或者多个操作应用到一组对象上,解耦操作和对象本身。访问者模式是23中经典设计模式中最难理解的设计模式之一,因为它难理解、难实现,应用它会导致代码的可读性、可维护性变差,所以,访问者模式在实际的软件开发中很少被用到,在没有特别必要的情况下,建议你不要使用访问者模式。
而且访问者模式需要用到函数的重载,用js去实现是一件费力不讨好的事情。为了保证这篇文章的完整性,我们用Java来实现一下,你看看了解一下就可以了。
public interface Visitor {void visit(Engine engine);void visit(Body body);void visit(Car car);}public class PrintCar implements Visitor {public void visit(Engine engine) {System.out.println("Visiting engine");}public void visit(Body body) {System.out.println("Visiting body");}public void visit(Car car) {System.out.println("Visiting car");}}public class CheckCar implements Visitor {public void visit(Engine engine) {System.out.println("Check engine");}public void visit(Body body) {System.out.println("Check body");}public void visit(Car car) {System.out.println("Check car");}}public interface Visitable {void accept(Visitor visitor);}public class Body implements Visitable {@Overridepublic void accept(Visitor visitor) {visitor.visit(this);}}public class Engine implements Visitable {@Overridepublic void accept(Visitor visitor) {visitor.visit(this);}}public class Car {private List<Visitable> visit = new ArrayList<>();public void addVisit(Visitable visitable) {visit.add(visitable);}public void show(Visitor visitor) {for (Visitable visitable: visit) {visitable.accept(visitor);}}}public class Client {static public void main(String[] args) {Car car = new Car();car.addVisit(new Body());car.addVisit(new Engine());Visitor print = new PrintCar();car.show(print);}}
一般来说,访问者模式针对的是一组类型不同的对象。不过,尽管这组对象的类型是不同的,但是,它们继承相同的父类或者实现相同的接口。在不同的应用场景下,我们需要对这组对象进行一系列不相关的业务操作(抽取文本、压缩等),但为了避免不断添加功能导致类不断膨胀,职责越来越不单一,以及避免频繁地添加功能导致的频繁代码修改,我们使用访问者模式,将对象与操作解耦,将这些业务操作抽离出来,定义在独立细分的访问者类中。
备忘录模式
在不违背封装原则的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便之后恢复对象为先前的状态。
这个模式理解、掌握起来不难,代码实现比较灵活,应用场景也比较明确和有限,主要是用来防丢失、撤销、恢复等。
//备忘类class Memento{constructor(content){this.content = content}getContent(){return this.content}}// 备忘列表class CareTaker {constructor(){this.list = []}add(memento){this.list.push(memento)}get(index){return this.list[index]}}// 编辑器class Editor {constructor(){this.content = null}setContent(content){this.content = content}getContent(){return this.content}saveContentToMemento(){return new Memento(this.content)}getContentFromMemento(memento){this.content = memento.getContent()}}//测试代码let editor = new Editor()let careTaker = new CareTaker()editor.setContent('111')editor.setContent('222')careTaker.add(editor.saveContentToMemento())editor.setContent('333')careTaker.add(editor.saveContentToMemento())editor.setContent('444')console.log(editor.getContent()) //444editor.getContentFromMemento(careTaker.get(1))console.log(editor.getContent()) //333editor.getContentFromMemento(careTaker.get(0))console.log(editor.getContent()) //222
备忘录模式也叫快照模式,具体来说,就是在不违背封装原则的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便之后恢复对象为先前的状态。这个模式的定义表达了两部分内容:一部分是,存储副本以便后期恢复;另一部分是,要在不违背封装原则的前提下,进行对象的备份和恢复。
备忘录模式的应用场景也比较明确和有限,主要是用来防丢失、撤销、恢复等。它跟平时我们常说的“备份”很相似。两者的主要区别在于,备忘录模式更侧重于代码的设计和实现,备份更侧重架构设计或产品设计。
命令模式
命令模式将请求(命令)封装为一个对象,这样可以使用不同的请求参数化其他对象(将不同请求依赖注入到其他对象),并且能够支持请求(命令)的排队执行、记录日志、撤销等(附加控制)功能。
// 接收者类class Receiver {execute() {console.log('接收者执行请求')}}// 命令者class Command {constructor(receiver) {this.receiver = receiver}execute () {console.log('命令');this.receiver.execute()}}// 触发者class Invoker {constructor(command) {this.command = command}invoke() {console.log('开始')this.command.execute()}}// 开发商const developer = new Receiver();// 售楼处const order = new Command(developer);// 买房const client = new Invoker(order);client.invoke()
在一些面向对象的语言中,函数不能当做参数被传递给其他对象,也没法赋值给变量,借助命令模式,我们将函数封装成对象,这样就可以实现把函数像对象一样使用。但是在js中函数当成参数被传递是再简单不过的事情了,所以上面的代码我们也可以直接用函数来实现。
解释器模式
解释器模式为某个语言定义它的语法(或者叫文法)表示,并定义一个解释器用来处理这个语法。比如我们要实现一个加减乘除的计算,如果单纯用if-else去判断操作符,这四种运算符号也能够用,但是如果我们后面要实现一个科学计算的话会需要用到更多的if-else判断,这未免会有些臃肿
class Context {constructor() {this._list = []; // 存放 终结符表达式this._sum = 0; // 存放 非终结符表达式(运算结果)}get sum() {return this._sum}set sum(newValue) {this._sum = newValue}add(expression) {this._list.push(expression)}get list() {return this._list}}class PlusExpression {interpret(context) {if (!(context instanceof Context)) {throw new Error("TypeError")}context.sum = ++context.sum}}class MinusExpression {interpret(context) {if (!(context instanceof Context)) {throw new Error("TypeError")}context.sum = --context.sum;}}class MultiplicationExpression {interpret(context) {if (!(context instanceof Context)) {throw new Error("TypeError")}context.sum *= context.sum}}class DivisionExpression {interpret(context) {if (!(context instanceof Context)) {throw new Error("TypeError")}context.sum /= context.sum}}// MultiplicationExpression和DivisionExpression省略/** 以下是测试代码 **/const context = new Context();// 依次添加: 加法 | 加法 | 减法 表达式context.add(new PlusExpression());context.add(new PlusExpression());context.add(new MinusExpression());context.add(new MultiplicationExpression());context.add(new MultiplicationExpression());context.add(new DivisionExpression());// 依次执行: 加法 | 加法 | 减法 表达式context.list.forEach(expression => expression.interpret(context));console.log(context.sum);
解释器模式的代码实现比较灵活,没有固定的模板。我们前面说过,应用设计模式主要是应对代码的复杂性,解释器模式也不例外。它的代码实现的核心思想,就是将语法解析的工作拆分到各个小类中,以此来避免大而全的解析类。一般的做法是,将语法规则拆分一些小的独立的单元,然后对每个单元进行解析,最终合并为对整个语法规则的解析。
总结
每个设计模式都应该由两部分组成:第一部分是应用场景,即这个模式可以解决哪类问题;第二部分是解决方案,即这个模式的设计思路和具体的代码实现。不过,代码实现并不是模式必须包含的。如果你单纯地只关注解决方案这一部分,甚至只关注代码实现,就会产生大部分模式看起来都很相似的错觉。
大部分设计模式的原理和实现,都非常简单,难的是掌握应用场景,搞清楚能解决什么问题。
应用设计模式只是方法,最终的目的,也就是初心,是提高代码的质量。具体点说就是,提高代码的可读性、可扩展性、可维护性等。所有的设计都是围绕着这个初心来做的。
所以,在做代码设计的时候,你一定要先问下自己,为什么要这样设计,为什么要应用这种设计模式,这样做是否能真正地提高代码质量,能提高代码质量的哪些方面。如果自己很难讲清楚,或者给出的理由都比较牵强,没有压倒性的优势,那基本上就可以断定这是一种过度设计,是为了设计而设计。
实际上,设计原则和思想是心法,设计模式只是招式。掌握心法,以不变应万变,无招胜有招。所以,设计原则和思想比设计模式更加普适、重要。掌握了设计原则和思想,我们能更清楚地了解为什么要用某种设计模式,就能更恰到好处地应用设计模式,甚至我们还可以自己创造出来新的设计模式。
源自:https://juejin.im/post/6868054744557060110
以上是关于前端进阶之路:1.5w字整理23种前端设计模式的主要内容,如果未能解决你的问题,请参考以下文章