干货:什么叫一个好的Ansible Playbook?
Posted 大魏分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了干货:什么叫一个好的Ansible Playbook?相关的知识,希望对你有一定的参考价值。
前言:
本文是我和李尧老师一起实验。李尧是红帽高级培训讲师,目前负责红帽中国区员工内部技术培训与认证。
一、什么是一个好的Ansible Playbook?
好的Ansible Playbook的三个原则:
越简单约好
可读性越好越好
通用性越强越好
三个原则看起来有点空,像废话?
我们看一个案例。这个案例是在ec2上部署一套三层应用。
这个三层应用包括:一个前端(haproxy)、两个app(tomcat)、一个db(postgresql)。
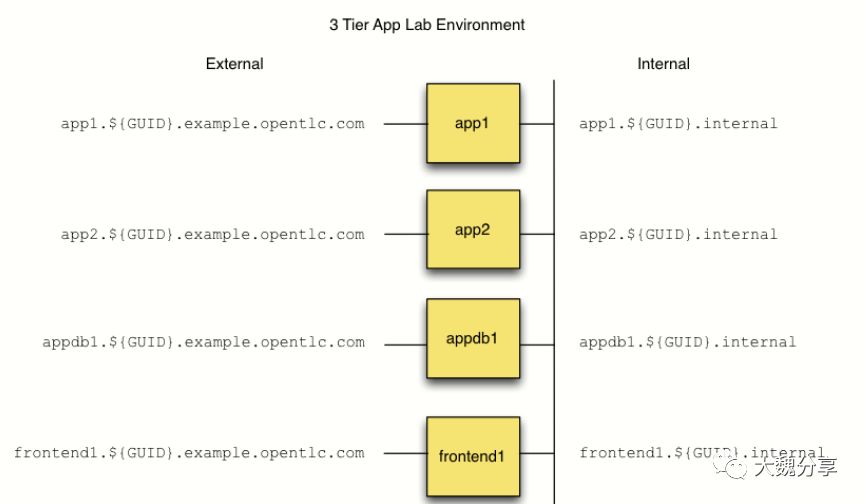
安装这个三层应用,如果手工安装,显然工作量很大,目测至少需要1-2天。但通过ansible,工作量会非常、非常、非常低。前提是,需要写出一个好的playbook。
二、一个不太好的anible playbook
针对安装三层应用的需求,我们先看一个不太好的playbook:
(https://github.com/tonykay/bad-ansible/blob/master/3tier-bad/bad-playbook.yml)
| - name: configuration | |
| hosts: all | |
| gather_facts: false # remove later! speeds up testing | |
| become: true | |
| tasks: | |
| - name: enable repos | |
| template: | |
| src: ./open_three-tier-app.repo | |
| dest: /etc/yum.repos.d/open_three-tier-app.repo | |
| mode: 0644 | |
| - name: deploy haproxy | |
| hosts: frontends | |
| gather_facts: false # remove later! speeds up testing | |
| become: true | |
| tasks: | |
| - name: http | |
| package: | |
| name: httpie | |
| state: latest | |
| - name: install HAProxy | |
| yum: | |
| name=haproxy state=latest | |
| - name: enable HAProxy | |
| service: | |
| name: haproxy | |
| state: started | |
| - name: configure haproxy | |
| template: | |
| src: ./haproxy.cfg.j2 | |
| dest: /etc/haproxy/haproxy.cfg | |
| - name: restart HAproxy | |
| service: | |
| name: haproxy | |
| state: restarted | |
| - name: deploy tomcat | |
| hosts: apps | |
| gather_facts: false | |
| become: true | |
| tasks: | |
| - name: install tomcat | |
| package: | |
| name: tomcat | |
| state: latest | |
| - name: enable tomcat at boot | |
| service: | |
| name: tomcat | |
| enabled: yes | |
| - name: create ansible tomcat directory | |
| file: | |
| path: /usr/share/tomcat/webapps/ROOT | |
| state: directory | |
| - name: copy static index.html to tomcat webapps/ansible/index.html | |
| template: | |
| src: index.html.j2 | |
| dest: /usr/share/tomcat/webapps/ROOT/index.html | |
| mode: 0644 | |
| - name: start tomcat | |
| service: | |
| name: tomcat | |
| state: started | |
| - name: index.html on app 1 | |
| hosts: app1 | |
| gather_facts: false | |
| become: true | |
| tasks: | |
| - name: copy static index.html to tomcat webapps/ansible/index.html | |
| template: | |
| src: index.html.app1 | |
| dest: /usr/share/tomcat/webapps/ansible/index.html | |
| - name: index.html on app 1 | |
| hosts: app2 | |
| gather_facts: false | |
| become: true | |
| tasks: | |
| - name: copy static index.html to tomcat webapps/ansible/index.html | |
| template: | |
| src: index.html.app2 | |
| dest: /usr/share/tomcat/webapps/ansible/index.html | |
| - name: deploy postgres | |
| hosts: apps | |
| gather_facts: false | |
| become: true | |
| hosts: appdbs | |
| tasks: | |
| - name: install progress | |
| command: "yum install -y postgresql-server" | |
| #- name: install postgres | |
| # yum: | |
| # name: postgresql-server | |
| # state: latest | |
| - name: enable apache at boot | |
| service: | |
| name: postgresql | |
| enabled: yes | |
| - name: tell user to finish setting up postgres | |
| debug: | |
| msg: "Either uncomment the postgres setup or manually login and initialize" | |
| # only run the next 2 tasks once! | |
| # - name: initilize postgres | |
| # command: postgresql-setup initdb | |
| # - name: initilize postgres some more | |
| # command: chkconfig postgresql on | |
| - name: start postgres | |
| service: | |
| name: postgresql.service | |
| state: started | |
| - name: deploy apache | |
| hosts: apps | |
| gather_facts: false | |
| become: true | |
| hosts: apps | |
| tasks: | |
| - name: install apache | |
| yum: | |
| name: httpd | |
| state: latest | |
| - name: enable apache at boot | |
| service: | |
| name: httpd | |
| enabled: yes | |
| - name: start apache | |
| service: | |
| name: httpd | |
| state: started |
Playbook大致做的事情是:
收集信息(ansible 2.3以后,有这个功能)
enable repos
安装haproxy、http
安装tomcat并进行配置
安装postgres并进行配置
安装并启动apache
执行这个playbook以后,通过curl检测前端,部署成功后,通过浏览器进行验证,前端访问的是app1:
front1:

haproxy的前端对于后端两个应用可以配置负载均衡的策略,当app1出现问题或者负载比较大的时候,前端将访问请求指向app2:

按理说,能写出这样一个playbook,其实还是很牛的。
但从技术角度,它并不是一个好的playbook。原因:
这个playbook太长,比较复杂
这个playbook可读性较差
这个playbook不方便复用
下来,看一个好的例子。
三、一个好的Ansible Playbook样例
我们看一个好的playbook案例。
(https://github.com/tonykay/good-ansible)
这个playbook的目录结构如下:

我们看一下主任务:main.yml
| --- | |
| - hosts: jumpbox | |
| gather_facts: false | |
| roles: | |
| - {name: osp-facts, when: ansible_product_name == 'OpenStack Compute'} | |
| # Setup front-end load balancer tier | |
| - name: setup load-balancer tier | |
| hosts: frontends | |
| become: yes | |
| roles: | |
| - {name: base-config, tags: base-config} | |
| - {name: lb-tier, tags: [lbs, haproxy]} | |
| # Setup application servers tier | |
| - name: setup app tier | |
| hosts: apps | |
| become: yes | |
| gather_facts: false | |
| roles: | |
| - {name: base-config, tags: base-config} | |
| - {name: app-tier, tags: [apps, tomcat]} | |
| # Setup database tier | |
| - name: setup database tier | |
| become: yes | |
| hosts: appdbs | |
| roles: | |
| - {name: base-config, tags: base-config} | |
| - {name: geerlingguy.postgresql, tags: [dbs, postgres]} |
相对于上一个案例,这个main.yml就清爽很多了。无论从可读性、简便性都高很多。
这个yaml做的事情:配置load-balancer tier、app tier、 database tier。然后,这三个大的任务,分别调用写好的roles。
这里,我们仅以配置load-balancer tier举例进行分析。
| - name: setup load-balancer tier | |
| hosts: frontends | |
| become: yes | |
| roles: | |
| - {name: base-config, tags: base-config} | |
| - {name: lb-tier, tags: [lbs, haproxy]} |
针对以上内容,配置load-balancer tier的操作会在frontends主机组上执行,用root用户执行配置。
然后,在frontends组的主机上,执行两个role:
执行base-config role。
执行lb-tier role 。
接下来,我们看一下这两个role的具体内容。

查看tasks下的主任务:
| --- | |
| # Initial, common, system setup steps | |
| - name: enable sudo without tty for some ansible commands | |
| replace: | |
| path: /etc/sudoers | |
| regexp: '^Defaults\s*requiretty' | |
| replace: 'Defaults !requiretty' | |
| backup: yes | |
| - name: enable repos | |
| template: | |
| src: repos_template.j2 | |
| dest: /etc/yum.repos.d/open_three-tier-app.repo | |
| mode: 0644 | |
| #- name: setup hostname | |
| # hostname: | |
| # name: "{{ inventory_hostname }}" | |
| - name: install base tools and packages | |
| yum: | |
| name: "{{ item }}" | |
| state: latest | |
| with_items: | |
| - httpie | |
| - python-pip |
上边task做的事情:
替换文件内容:将/etc/sudoers文件中的^Defaults\s*requiretty替换为Defaults !requiretty,
然后,enable repos、设置主机名、安装http和python。
接下来,看一下lb-tier role

查看主任务:
| --- | |
| - name: install {{ payload }} | |
| yum: | |
| name: "{{ payload }}" | |
| state: latest | |
| - name: enable {{ payload }} at boot | |
| service: | |
| name: "{{ payload }}" | |
| enabled: yes | |
| - name: configure haproxy to load balance over app servers | |
| template: | |
| src: haproxy.cfg.j2 | |
| dest: /etc/haproxy/haproxy.cfg | |
| mode: 0644 | |
| - name: start {{ payload }} | |
| service: | |
| name: "{{ payload }}" | |
| state: restarted |
上面的playbook做的操作:安装、配置、启动一个服务。这个服务是个变量{{ payload }},这个变量会在vars进行设置,通过下面的配置,我们知道这个变量是haproxy。

所以,本playbook执行的任务就是安装、配置、启动haproxy服务。
那么,将一个大的playbook拆分成role的好处是什么呢?我们看一下main.yml的另外一个任务:
| - name: setup app tier | |
| hosts: apps | |
| become: yes | |
| gather_facts: false | |
| roles: | |
| - {name: base-config, tags: base-config} | |
| - {name: app-tier, tags: [apps, tomcat]} |
我们看到,这个任务也是先调用 base-config这个role。
这样,这些roles可以不仅被这个大的playbook调用,也可以方便被其他人调用。
此外,在ansible中,我们可以设置vault,也就是对关键参数进行AES 256加密。然后其他变量可以调用这个加密参数(如密码等机密信息)
我们看一个加密文件:
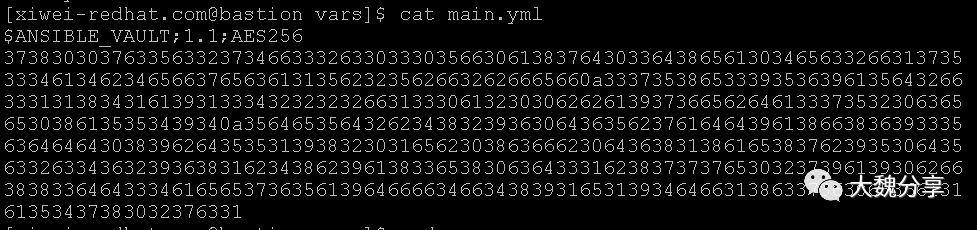
那么,我们怎么解密这个文件呢?
在知道密码的情况下(不知道密码我也无法破解),执行如下命令:

因此,这个加密文件中的内容,key是own_repo_path,value是我抹掉的内容。
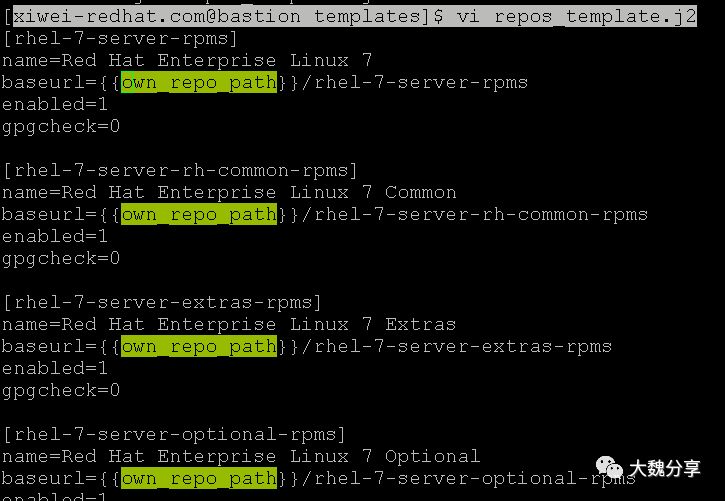
而own_repo_path这个参数,在template的文件中被调用:
书写roles的核心内容modules,是下面的网站上是公开的:
http://docs.ansible.com/ansible/latest/modules/list_of_all_modules.html
而ansible module的迅速壮大,也是ansible目前成为自动化运维领域第一语言的一个重要原因。
参照文档:
https://github.com/prakhar1985/good_example

魏新宇
"大魏分享"运营者、红帽资深解决方案架构师
专注开源云计算、容器及自动化运维在金融行业的推广
拥有红帽RHCE/RHCA、VMware VCP-DCV、VCP-DT、VCP-Network、VCP-Cloud、ITIL V3、Cobit5、C-STAR、AIX、HPUX等相关认证。
文章打赏随意(转发和赞赏都是对作者原创的鼓励):
更多精彩内容,欢迎继续关注大魏分享:
以上是关于干货:什么叫一个好的Ansible Playbook?的主要内容,如果未能解决你的问题,请参考以下文章