selenium-获取下拉选择框value默认的文本,而不是下拉框所有的文本值
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了selenium-获取下拉选择框value默认的文本,而不是下拉框所有的文本值相关的知识,希望对你有一定的参考价值。
如图假如通过by_value选择了天津这项,怎么判断他的文本是不是天津?
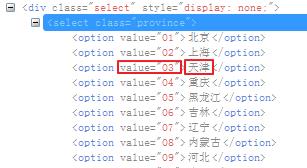
首先,Select类功能中
all_selected_options: 获取下拉菜单和列表中被选中的所有选项内容
first_selected_option: 获取下拉菜单和列表的第一个选项
所以呢,可以这样写,
----
#定位省份类型字段,作为Select类的对象实例
select_province_type = Select(self.driver.find_element_by_class_name('province'))
#检查默认选项是否为'天津'
self.assertTrue(select_province_type.first_selected_option.text == '天津') 参考技术A verifySelectedLabel 比较选择的文本
verifySelectedValue 比较value
Python3.x:selenium遍历select下拉框获取value值
Python3.x:遍历select下拉框获取value值
Select提供了三种选择方法:
# 通过选项的顺序,第一个为 0 select_by_index(index) # 通过value属性 select_by_value(value) # 通过选项可见文本 select_by_visible_text(text)
Select提供了四种方法取消选择:
deselect_by_index(index)
deselect_by_value(value)
deselect_by_visible_text(text)
deselect_all()
Select提供了三个属性方法给我们必要的信息:
# 提供所有的选项的列表,其中都是选项的WebElement元素 options # 提供所有被选中的选项的列表,其中也均为选项 all_selected_options的WebElement元素 # 提供第一个被选中的选项,也是下拉框的默认值 first_selected_option
示例一:代码(selenium遍历select选项列表):
from selenium import webdriver driver = webdriver.PhantomJS() driver.get("http://************/center_tjbg.shtml") #通过contains函数,提取匹配特定文本的所有元素 frame = driver.find_element_by_xpath("//iframe[contains(@src,\'http://**********/cms-search/monthview.action?action=china&channelFidStr=e990411f19544e46be84333c25b63de6\')]") #进入iframe页面 driver.switch_to.frame(frame) #获取select标签 select = driver.find_element_by_id("channelFidStr") # 获取select里面的option标签,注意使用find_elements options_list=select.find_elements_by_tag_name(\'option\') # 遍历option for option in options_list: #获取下拉框的value和text print ("Value is:%s Text is:%s" %(option.get_attribute("value"),option.text)) #退出iframe driver.switch_to_default_content() driver.quit()
示例二:代码(BeautifulSoup遍历select选项列表):
url = "http://********************/monthview.action?action=china" headerDict = {\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.31 Safari/537.36\'} data = {\'riqi\': \'2017年12月\', \'channelFidStr\': \'e990411f19544e46be84333c25b63de6\', \'channelIdStr\': \'08ce523457dd47d2aad6b41246964535\'} # psot 传递参数 res = requests.post(url, data=data, headers=headerDict) # 获取跳转后的页面源码 soup = BeautifulSoup(res.content, "html.parser") #获取select的选项列表 option_list = soup.find(id=\'channelFidStr\').find_all(\'option\') #遍历select的选项列表 for option in option_list: print("value:%s text:%s"%(option[\'value\'],option.text))
作者:整合侠
链接:http://www.cnblogs.com/lizm166/p/8367615.html
来源:博客园
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
以上是关于selenium-获取下拉选择框value默认的文本,而不是下拉框所有的文本值的主要内容,如果未能解决你的问题,请参考以下文章