实时识别字母:深度学习和 OpenCV 应用搭建实用教程
Posted AI开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时识别字母:深度学习和 OpenCV 应用搭建实用教程相关的知识,希望对你有一定的参考价值。
本文为AI研习社编译的技术博客,原标题 Tutorial:Alphabet Recognition In Real Time — A Deep Learning and OpenCV Applica,作者为 Akshay Chandra Lagandula 。
翻译 | 赵若伽 李欣 校对 | 汪其香 整理 | MY
这是一个关于如何构建深度学习应用程序的教程,该应用程序可以实时识别由感兴趣的对象(在这个案例中为瓶盖)写出的字母。
项目描述
深度学习技术的能力的一个主流的证明就是在图像数据里的目标识别。
这个深度学习 python 的应用可以从网络摄像头数据中实时的识别字母,使用者被允许使用一个感兴趣的对象(在这个案例中是一个水瓶盖)在屏幕上写出字母。
你可以点击这里访问整个项目的源码(https://github.com/akshaychandra21/Alphabet_Recognition_RealTime)。
工作实例
编码要求
代码是用 3.6 版的 Python,同时结合了 OpenCV 和 Keras 库来编写成的。
数据描述
用于机器学习和深度学习的「扩展 Hello World」目标识别基于手写字母识别的 EMNIST 数据集,它是 MNIST 数据集 (「Hello World」的目标识别) 的一个扩展版本。

就像上面显示的一样,字母 『e』 被储存在一个 28 x 28 的 numpy 数组。
编码说明
步骤 1:训练一个多层感知模型
1.1 加载数据
我们使用 Python 的 mnist 库来加载数据:

我们已经准备好要给到模型的数据了。将数据分为训练和测试集、标准化图片以及其他基本的情况。
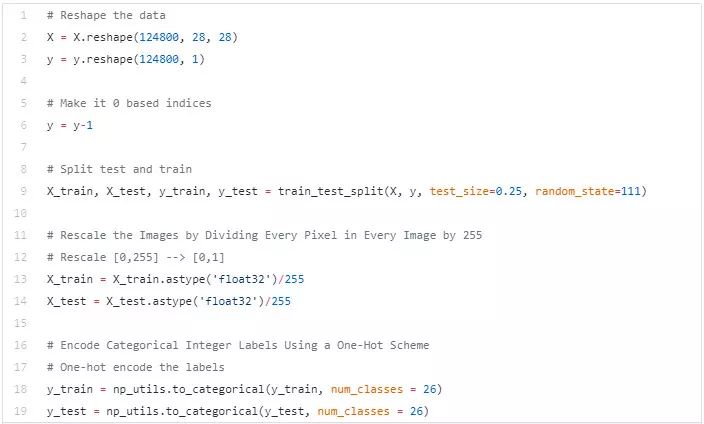
1.2 定义模型
在 Keras,模型被定义为层的序列。我们首先初始化一个 『序列模型』,然后用各自的神经元去添加各自的层, 接下来的代码做了同样的事情。
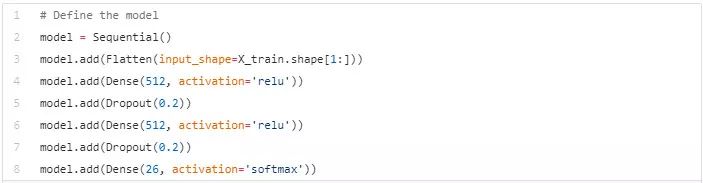
这个模型如我们希望的那样使用 28 x 28 像素(我们展平图片然后将每个像素值放入一个一维向量)作为输入。模型的输出必须由某个字母决定,所以我们设置输出层有 26 个神经元(决定是由概率做出)。
1.3 编译模型
现在已经定义好了模型,我们可以编译它了。使用高效的数字库例如 Theano 或 TensorFlow 来编译模型。
在这里我们可以指定一些需要用来训练网络的特性。通过训练,我们尝试找到可以在输出时做出决定的最好的权重组合。我们必须指定用来评估权重组合的损失函数,用来为网络寻找不同的权重组合的优化器和任何我们在训练中想收集和报告的备选的矩阵。

1.4 Fit Model
在这里,我们通过模型检查点来训练模型,这个检查点会帮助我们保存最好的模型(根据我们在上一步定义的矩阵来判断是否是最好)。
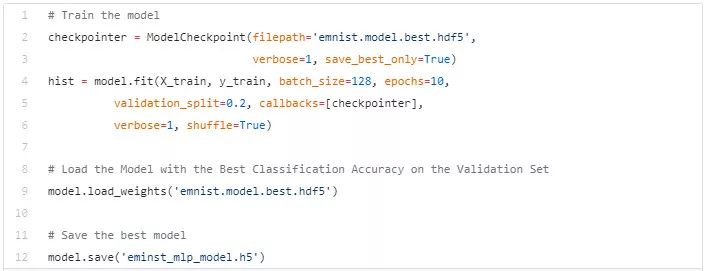
1.5 评估模型

在 EMNIST 数据集上模型的测试准确度是 91.1%.
1.6 把他们结合起来
将所有步骤结合起来,我们得到了一个通过 EMNIST 数据训练出来的合适的多层感知器模型的所有代码。
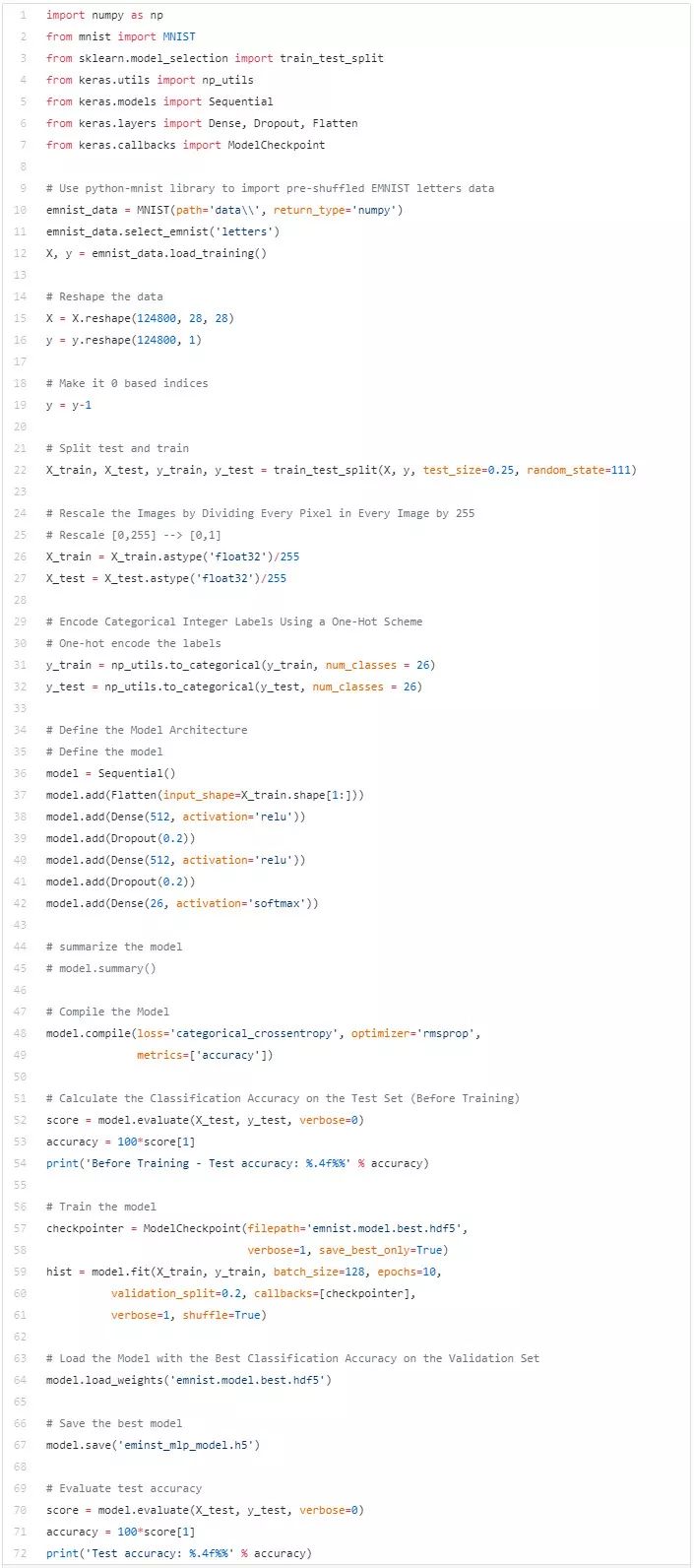
步骤 2:训练一个卷积神经网络模型
2.1 和 2.2 — 加载数据及定义模型
这两步和我们建立多层感知器模型的步骤是完全相同的。
2.3 定义模型
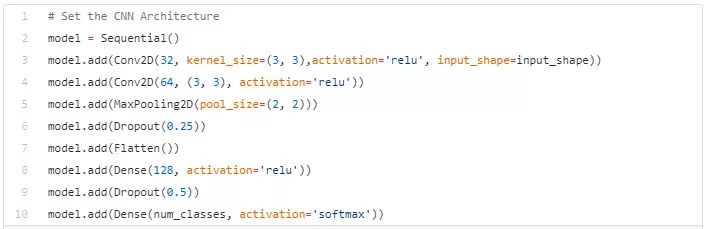
由于部分内容超出了本教程所讲范围,我事先定义了一个 CNN 框架来解决手头的问题。想了解更多有关 CNN 的信息,请访问该教程:
http://cs231n.github.io/convolutional-networks/
2.3 编译模型

与 MLP 模型不同,这次我将使用 ADADELTA 优化器。
2.4 拟合模型
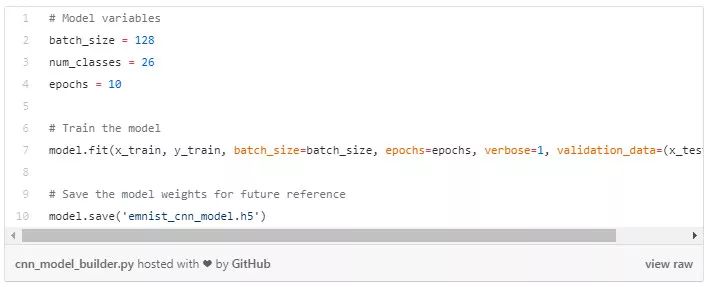
想要了解模型参数 batch_size 和 epochs 是如何影响模型性能的,可访问这里:
https://towardsdatascience.com/epoch-vs-iterations-vs-batch-size-4dfb9c7ce9c9
2.5 评估模型

此模型在数据集 EMNIST 上的测试准确率为 93.1%。
2.6 小结
综上,我们获得了用来构建良好 CNN 模型所需的完整代码,此模型是在 EMNIST 数据集上训练的。

步骤 3:初始化
在研究识别代码前先要进行初始化步骤。
首先,加载前面步骤中构建的模型。然后创建一个字母字典,使用 blueLower 和 blueUpper 边界来检测蓝色瓶盖,Kernal 沿着路径做平滑操作,使用空的 blackboard 将文字储存为白色(就像 EMNIST 数据集中的字母表),使用 Deque 来存储笔生成的所有点(蓝色瓶盖),并定义一对默认变量值。

步骤 4:识别文字
一旦开始逐帧读取输入的视频,尝试找到蓝色瓶盖并将其用作笔。我们使用 OpenCV 的 cv2.VideoCapture() 方法逐帧(使用 while 循环)从视频文件或网络摄像头实时读取视频。在这种情况下,我们将 0 传递给函数以此进行网络摄像头读取。以下代码演示了相同的内容。
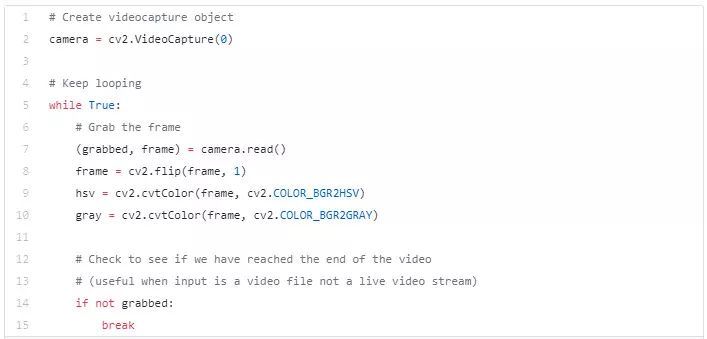
一旦开始读取网络摄像头传入的数据,我们就用 CV2.inRange() 不断寻找框架中的蓝色物体,并使用预先初始化的 BlueUpper 和 BlueLower 变量。一旦找到轮廓,就进行一系列的图像处理使其平滑,平滑会让后续的操作更容易。如果你想知道更多关于这些运算的知识——腐蚀,变形和膨胀,点击这里。

一旦找到轮廓(找到轮廓时,if条件通过),我们用轮廓(蓝色瓶盖)的中心在移动屏幕上绘制。 以下代码也是如此。

上面的代码检查是否找到轮廓,找到了则取其最大轮廓(假设它是瓶盖),使用 cv2.minEnclosingCircle() 和 cv2.circle() 方法在它周围画一个圆圈,并用 cv2.moments() 找轮廓中心。最后把中心存储在命名点的双端队列中,以便我们可以将它们全部加入完整轮廓中。
在 frame 和 blackboard 上显示此图形。一个用于外部显示另一个用于将其传递给模型。
注意:我已经写了一个关于设置绘图类型环境的简短教程,它允许我们在绘图应用程序中进行绘制,点击此处以了解最新情况(https://medium.com/@akshaychandra21/tutorial-webcam-paint-opencv-dbe356ab5d6c)。
步骤 5:重构绘制并将其传递给模型
一旦用户完成绘制,我们将获取之前存储的点连接起来,将它们放在 blackboard 上并将其传递给模型。
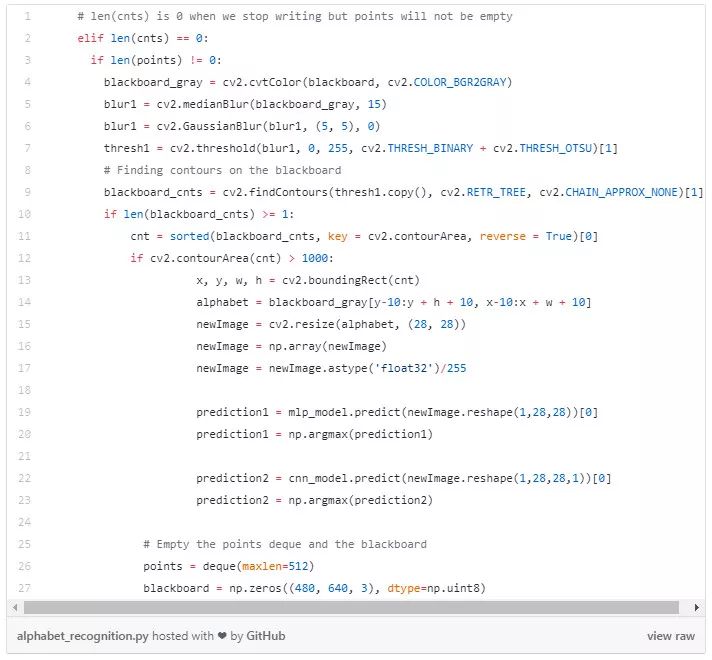
当我们停止写入时程序进入 ELIF 模块(因为没有检测到轮廓)。一旦我们验证了点集 deque 不为空就认为写入已完成。取出 blackboard 图像再做一次快速轮廓搜索(涂掉后再显示)。一旦找到,通过切割来调整使满足我们构建模型的输入尺寸要求,即 28×28 像素,并把它传递给两个模型!
步骤 6:显示模型预测
在框架窗口上显示此模型所做的预测,使用方法 cv2.imshow() 将其显示出来。在退出 while 循环后进入网络摄像头读取数据停止相机并关闭所有窗口。
执行
1. 下载数据
从这里下载数据文件夹并将其作为项目目录:
https://github.com/akshaychandra21/Alphabet_Recognition_RealTime/tree/master/data
2. 建立 MLP 模型

3. 建立 CNN 模型
4. 运行引擎文件
5. 捕捉蓝色瓶盖
玩得开心!
结论
在本教程中,我们构建了两个使用著名的 EMNIST 数据进行训练的深度学习模型,一个 MLP 模型和一个 CNN 模型。并使用这些模型来实时预测我们感兴趣的对象所写的字母。我鼓励您通过调整这两个模型的架构来看看它们会如何影响您的预测。希望本教程很有趣,谢谢阅读。
原文链接:
https://towardsdatascience.com/tutorial-alphabet-recognition-deeplearning-opencv-97e697b8fb86
想阅读更多计算机视觉文章?
欢迎点击“阅读原文”
或者移步 AI 研习社社区~
以上是关于实时识别字母:深度学习和 OpenCV 应用搭建实用教程的主要内容,如果未能解决你的问题,请参考以下文章
五分钟快速搭建一个实时人脸口罩检测系统(OpenCV+PaddleHub 含源码)