OpenCV加速与优化,让代码执行速度飞起来
Posted OpenCV学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV加速与优化,让代码执行速度飞起来相关的知识,希望对你有一定的参考价值。
引子
做OpenCV开发这些年以来,很多人对OpenCV经常说的抱怨有如下两点:
1.OpenCV模块很多,是一个很重量级的视觉框架!
2.OpenCV速度有点问题,不够快!
针对对一个问题,OpenCV开发包包含的东西太多了,大而全,而它们的项目可能需要只是一点点,需要的是小而精,其实这个很容易解决,这个就是要求做好OpenCV的模块裁剪与移植,通过CMake自己编译,关于这个问题,我也写过一篇文章来介绍,感兴趣可以点击这里:
第二个问题,我们可以分为几个部分来说明。
CPU加速
今天我们重点说说第二个问题,OpenCV速度没有达到项目要求怎么办,其实OpenCV发展到今天在不同的架构平台上都有一些底层的指令集支持的加速方法,在Windows系统下,OpenCV编译默认支持加速SSE3 指令集,同时还额外支持SSE4.2、AVX、AVX2等加速指令集,在编译时候CMake配置文件提供了下面选项支持
CPU_BASELINE=SSE2CPU_BASELINE=AVX需要C++编译器支持CPU_DISPATCH=SSE4_2,AVXCPU_DISPATCH=AVXCPU_DISPATCH=AVX,AVX2额外的加速支持,同样需要编译器支持。
早期通过ENABLE的方式已经在OpenCV3.x之后被抛弃,下面这个几个选项是无效选项
ENABLE_AVXENABLE_AVX2ENABLE_POPCNT
ARMv7架构系统下支持
NEON这些方法的加速效果如何,答案是通过编译支持的SSE/AVX加速,基本上可以获得1.3~3.0之间的加速执行。这个也就是为什么有时候我们直接无感的原因,就是加速不够明显!
一般情况下,自己重新编译OpenCV源码,CMake的时候都会生成如下的一些信息:
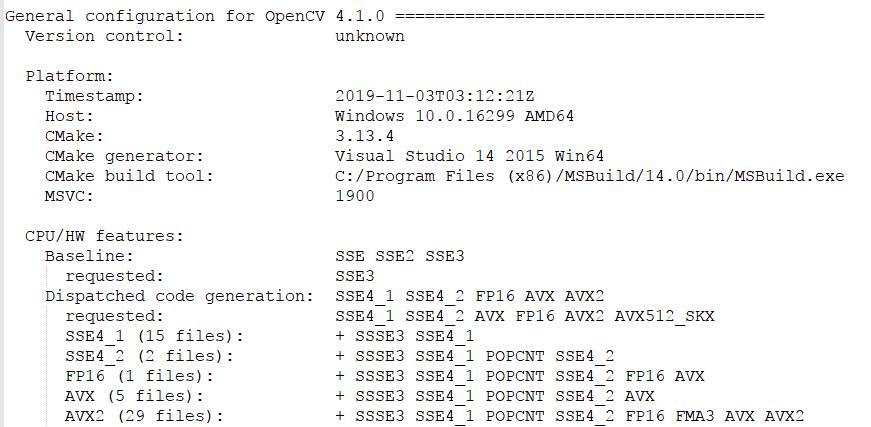
其实这个时候,还有几个比较有用的Flag可以勾选上,会起到明显的加速效果:
WITH_TBB
默认情况下是OFF、勾选可以获得并行处理支持
在TBB开启支持的情况下,可以通过下面的两个API设置线程数目,尝试获得并行执行能力。
setNumThreads() // 设置线程数目getNumThreads() // 查询线程数目,为0表示顺序执行
CV_ENABLE_IPP
默认情况下是OFF、早期的OpenCV版本可以这么干,现在的OpenCV版本不支持
GPU加速
OpenCV CUDA支持下面的模块的加速运行
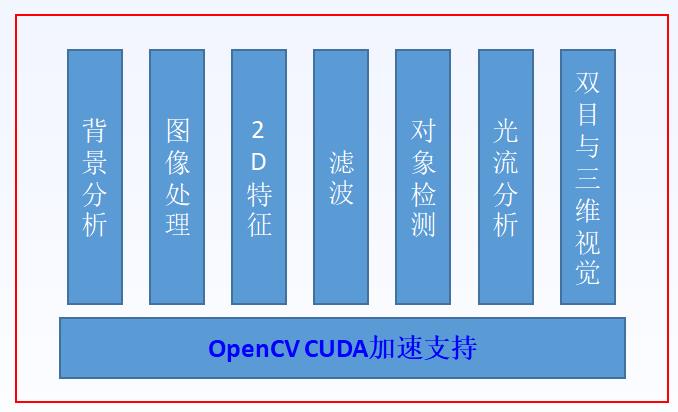
这个OpenCV默认是不支持,需要自己重新编译OpenCV源码,如何编译,参考我在B站的视频教程:
https://www.bilibili.com/video/av71643385
OpenCV中深度神经网络模块之前一直不支持CUDA作为计算后台的加速运行,就在前几天,OpenCV社区刚刚完成此项支持,所以OpenCV DNN模块在后续下个版本中将可以使用CUDA加速。简单点说,OpenCV DNN模块将会获得更大的速度优势。OpenCV也必将在更多边缘设备上得到应有。
OpenVINO加速
英特尔从去年推出视觉加速框架,对OpenCV所有的模块都有加速,特别是对深度神经网络模块,支持CPU/GPU(HD显卡)/加速棒等硬件加速,特别值得一提的是其CPU基本的加速,对人脸检测、对象检测等深度神经网络均可以达到实时运行级别,本人也写过一系列的OpenVINO SDK开发的相关技术文章。OpenVINO的安装与配置,代码演示,可以观看我在B站的视频教程:
https://www.bilibili.com/video/av71979782
相关技术文章汇总在这里:
总结与后记
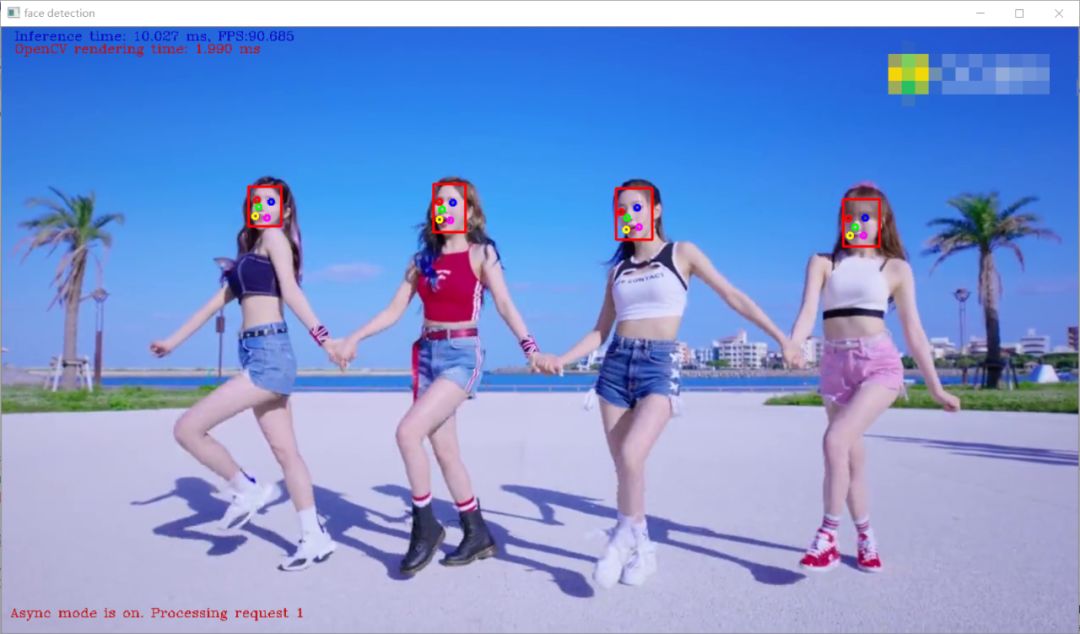
上述各种加速手段,都有一定的限制,只有选择适合应用场景的加速方法才是正确的解决问题之道。另外OpenCV在开发阶段,不同代码写法与实现效率有时候会有云泥之别!这个更加体现开发者本身的技术水准。最后放两张图,看一下,OpenCV加速效果,分别是传统的图像处理方式与深度学习模型加速视频演示,帧率分别超过 199与90 FPS 以上!


往期精选
告诉大家你在看
善始者实繁
克终者盖寡
以上是关于OpenCV加速与优化,让代码执行速度飞起来的主要内容,如果未能解决你的问题,请参考以下文章