使用VP树和OpenCV构建一个图像哈希搜索引擎
Posted Python程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用VP树和OpenCV构建一个图像哈希搜索引擎相关的知识,希望对你有一定的参考价值。
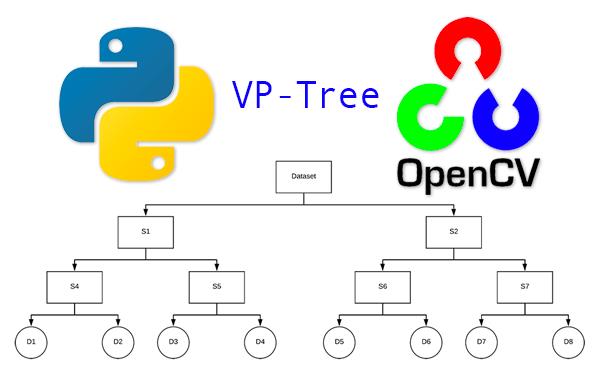
在本教程中,您将学习如何使用OpenCV、Python和VP树构建一个可伸缩的图像哈希搜索引擎。
图像哈希算法被用于:
仅使用单个整数唯一地量化一个图像的内容。
根据计算得到的哈希值,在图像数据集中查找重复或近似重复的图像。
在2017年,我写了一篇关于使用OpenCV和Python进行图像哈希处理的教程(这是本教程的必读内容)。该指南向您展示了如何在一个给定的数据集中找到相同/重复的图像。
然而,在最初的教程中存在一个可伸缩性的问题——即它不具有可伸缩性!
为了找到近似重复的图像,我们的原始图像哈希方法需要我们去执行一个线性搜索,将查询哈希与数据集中的每个图像哈希进行比较。
在一个实际的、现实的应用程序中,这会相当慢——我们需要找到一种方法来将搜索降低到次线性时间复杂度。
但我们如何才能大幅减少搜索时间呢?
答案是一种称为VP树的专用数据结构。
使用VP树,我们可以将我们的搜索复杂度从O(n)降低到O(log n),从而实现我们的次线性目标!
在本教程的其余部分,您将学习如何:
构建一个图像哈希搜索引擎,在一个数据集中查找相同和接近相同的图像。
利用一种专门的称为VP树的数据结构,它可以用于将图像哈希搜索引擎扩展到数百万张图像。
要学习如何使用OpenCV构建您的第一个图像哈希搜索引擎,请继续阅读!
在寻找这篇文章的源代码吗?
直接跳到本文的下载部分。
使用VP树和OpenCV构建一个图像哈希搜索引擎
在本教程的第一部分中,我将回顾一下图像搜索引擎对PyImageSearch的新手来说,到底是什么。
然后,我们将讨论图像哈希和感知哈希的概念,包括如何使用它们来构建一个图像搜索引擎。
我们还将看一下与图像哈希搜索引擎相关的问题,包括算法的复杂性。
注意: 如果您还没有阅读过我关于使用OpenCV和Python进行图像哈希的教程,请确保您现在就去阅读。要继续本教程,该指南是必读的。
在此基础上,我们将简要回顾一下能够显著提高图像哈希搜索引擎效率和性能的优点树(VP树)。
有了这些知识,我们将使用VP树来实现我们自己的自定义图像哈希搜索引擎,然后检查结果。
什么是图像搜索引擎?

图1:一个图像搜索引擎的例子。提供一个查询图像,搜索引擎会在一个数据集中找到相似的图像。
在本节中,我们将回顾图像搜索引擎的概念,并向您介绍一些额外的资源。
PyImageSearch起源于图像搜索引擎——这是我在2014年开始写博客时的主要兴趣。本教程对我来说是一个有趣的分享,因为我在图像搜索方面的知识有所欠缺,尤其是涉及到计算机视觉方面的内容。
图像搜索引擎很像文本搜索引擎,只是我们使用图像而不是文本作为一个查询。
当您使用一个文本搜索引擎时,如谷歌,Bing或DuckDuckGo等,您输入您的搜索查询——一个词或短语。相关的索引化的网站会作为结果返回给您,在理想情况下,您将会找到您要查找的内容。
类似地,对于一个图像搜索引擎,您将提交一个查询图像(不是一个文本单词/短语)。然后,图像搜索引擎仅根据图像的内容返回类似的图像结果。
当然,在任何类型的搜索引擎背后都有很多东西——您只需要记住这个关键的查询/结果概念就可以了,因为我们今天要构建一个图像搜索引擎。
要了解更多关于图像搜索引擎的知识,我建议您参考以下资源:
使用Python和OpenCV构建图像搜索引擎完全指南
——这是一个很棒的指南。
图像搜索引擎博客目录
——这个分类链接会返回PyImageSearch博客上我的所有的图片搜索引擎内容。
PyImageSearch权威教程
——我的旗舰计算机视觉课程有13个模块,其中一个是专门针对于基于内容的图像检索(图像搜索引擎的一个花哨的名字)。
>>> 今日签到口令:3v15 <<<
阅读这些指南,对图像搜索引擎是什么有一个基本的理解,然后回到本文来学习有关图像哈希搜索引擎的知识。
什么是图像哈希/感知哈希?
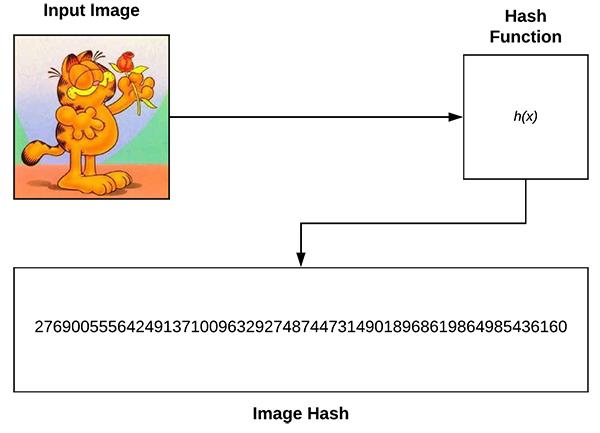
图2:一个图像哈希函数的例子。左上角:一个输入图像。右上角:一个图像哈希函数。底部:生成的哈希值。在本教程中,我们将使用VP树和OpenCV构建一个基本的图像哈希搜索引擎。
图像哈希,也称感知哈希,它是:
检查一个图像的内容。
构造一个哈希值(即一个整数),仅根据图像的内容对输入图像进行唯一的量化。
的过程。
使用图像哈希的好处之一是,用于量化图像的结果存储空间非常小。
例如,假设我们有一个具有3个通道的800x600px的图像。如果我们使用8位无符号整数数据类型将整个图像存储在内存中,那么该图像将需要1.44MB的RAM。
当然,在对一个图像进行量化时,我们很少存储其原始图像像素。
相反,我们将使用一些算法,如关键点检测器和局部不变描述符(即 SIFT、SURF等)。
应用这些方法通常可以为每张图像带来100到1000个特征。
如果我们假设检测到适当的500个关键点,每个关键点会产生一个32位浮点数据类型的128维的特征向量,我们将总共需要0.256MB来存储我们的数据集中每个单独图像的量化结果。
另一方面,图像哈希允许我们仅使用一个32位整数来量化一个图像,它只需要4字节的内存!
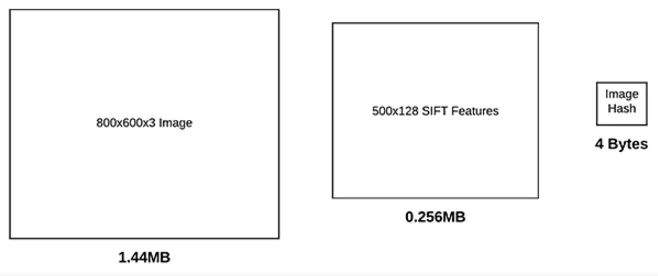
图3:与原始图像位图大小或图像特征(SIFT等)相比,图像哈希需要更少的磁盘空间。我们将使用图像哈希作为一个使用VP树和OpenCV构建的图像搜索引擎的基础。
此外,图像哈希也应该是可比较的。
假设我们计算三个输入图像的哈希,其中两个图像几乎相同:
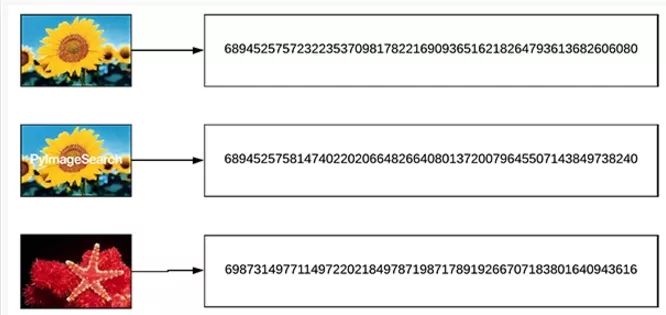
图4:三个具有不同哈希值的图像。前两个哈希之间的汉明距离比第三幅图的汉明距离更近。我们将使用一个VP树数据结构来创建一个图像哈希搜索引擎。
为了比较我们的图像哈希,我们将使用汉明距离。在这个上下文中,汉明距离用于比较两个整数之间的不同位的数目。
实际上,这意味着我们是在两个整数之间取XOR时计算1的个数。
因此,回到我们上面的三幅输入图像,我们的两幅相似的图像之间的汉明距离应该比第三幅不太相似的图像之间的汉明距离要小(表示相似度更高):

图5:显示了图像哈希之间的汉明距离。请注意,前两幅图像之间的汉明距离小于第一幅和第三幅(或第二幅和第三幅)图像之间的汉明距离。图像哈希之间的汉明距离将在我们的使用VP树和OpenCV的图像搜索引擎中发挥作用。
再次注意,两幅图像之间的汉明距离是如何小于第三幅图像之间的距离的:
两个哈希值之间的汉明距离越小,图像就越相似。
相反,两个哈希值之间的汉明距离越大,图像就越不相似。
还要注意相同图像之间的距离(即沿着图5的对角线)均为0 ——如果两个输入图像相同,则两个哈希值之间的汉明距离为0,反之如果距离为>0,则数值越大相似度越小。
图像哈希算法有很多,其中最流行的一种叫做差分哈希,它包括四个步骤:
步骤1:将输入图像转换为灰度图。
步骤2:调整图像到固定的尺寸,N + 1 x N,忽略长宽比。通常我们令N=8或N=16。我们使用N + 1作为行数,以便计算图像中相邻像素之间的差值(因此称为“差分哈希”)。
步骤3:计算差值。如果我们设N=8,那么每一行有9个像素,每一列有8个像素。然后我们就可以计算相邻列像素之间的差值,得到8个差值。8行8个差值(即8×8)得到64个值。
步骤4:最后,我们可以构建该哈希值。在实践中,我们实际上只需要执行一个“大于”操作来比较列,生成二进制值。这64个二进制值被压缩成一个整数,形成我们最终的哈希值。
通常,图像哈希算法用于在大型数据集中查找近似重复的图像。
我已经在这个教程中(https://www.pyimagesearch.com/2017/11/27/image-hashing-opencv-python/ )详细介绍了图像哈希的知识,所以如果您对这个概念还不熟悉,我建议您在继续阅读本教程之前阅读一下该指南。
什么是图像哈希搜索引擎?
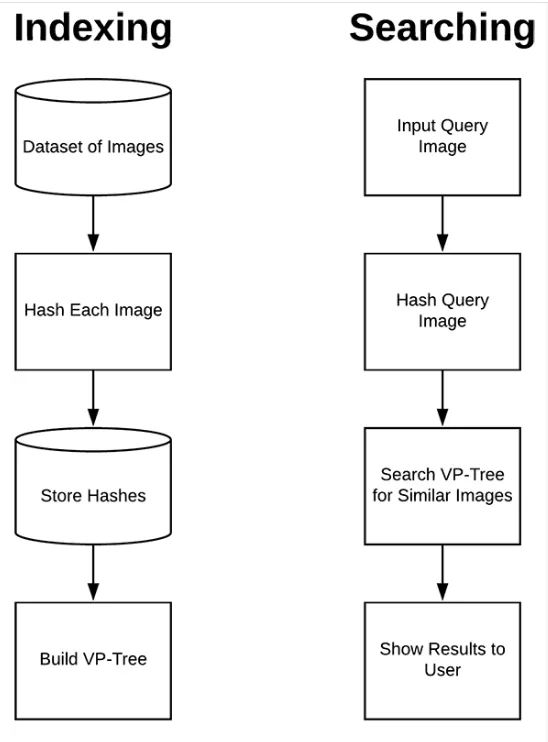
图6:图像搜索引擎由图像、索引器和搜索器组成。我们将通过计算和存储它们的哈希值来索引所有的图像。我们将构建一个哈希值的VP树。搜索器将计算查询图像的哈希值,并在VP树中搜索相似的图像并返回最接近的匹配。使用Python、OpenCV和vptree,我们可以实现我们的图像哈希搜索引擎。
一个图像哈希搜索引擎由两个部分组成:
索引化: 获取一个输入图像数据集,计算其哈希值,并将这些值存储在一个数据结构中来促进快速、高效地搜索。
搜索/查询:从用户接受一个输入查询图像,计算其哈希值,然后在我们索引化的数据集中找到所有接近的图像。
图像哈希搜索引擎的一个很好的例子是TinEye,它实际上是一个反向图像搜索引擎。
一个反向图像搜索引擎:
接受一个输入图像。
在web上找到该图像的所有近似副本,并告诉您可以找到这些近似副本的网站/URL。
使用本教程,您将学习如何建立自己的TinEye!
扩展图像哈希搜索引擎面临的问题?
构建图像哈希搜索引擎的最大问题之一是可伸缩性——拥有的图像越多,执行搜索所需的时间就越长。
例如,假设我们有以下场景:
我们有一个1000000张图像的数据集。
我们已经为这1000000张图像中的每一个都计算了哈希值。
一个用户来访问我们的程序,为我们呈现一张图像,然后让我们找到该数据集中所有接近的图像。
您准备如何执行该搜索呢?
您是否会逐个遍历所有这1,000,000个图像哈希,并将它们与查询图像的哈希进行比较?
不幸的是,这是行不通的。即使您假设每个汉明距离比较需要0.00001秒,总共有1,000,000个图像,完成搜索也需要10秒时间——这对于任何类型的搜索引擎来说都太慢了。
相反,要构建一个可伸缩的图像哈希搜索引擎,您需要利用专门的数据结构。
什么是VP树,它们如何帮助我们扩展图像哈希搜索引擎?
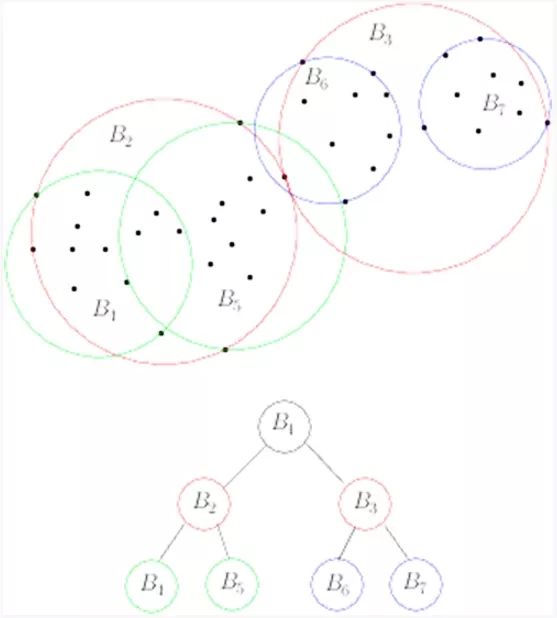
图7:我们将通过Python和OpenCV为我们的图像哈希搜索引擎使用VP树。VP树基于递归算法,计算有利位置和中间值,直到到达包含单个图像哈希的子节点。距离较近的子节点(在我们的例子中是更小的汉明距离)被认为是彼此更相似。(图片来源)
为了扩展我们的图像哈希搜索引擎,我们需要使用一个专门的数据结构,它能够:
将我们的搜索从线性复杂度, O(n) …
…减小到子线性复杂度,理想状况下是 O(log n) 。
为了完成这个任务,我们可以使用优势点树(VP树)。VP树是一种度量树,它通过选择空间中给定的位置(即优势点)在度量空间中进行操作,然后将数据点划分为两个集合:
在有利位置附近的点
远离有利位置的点
然后我们递归地应用这个过程,将这些点分割成越来越小的集合,从而创建一个树,其中的相邻点具有更小的距离。
为了可视化构建一个VP树的过程,我们考虑一下下面的图:
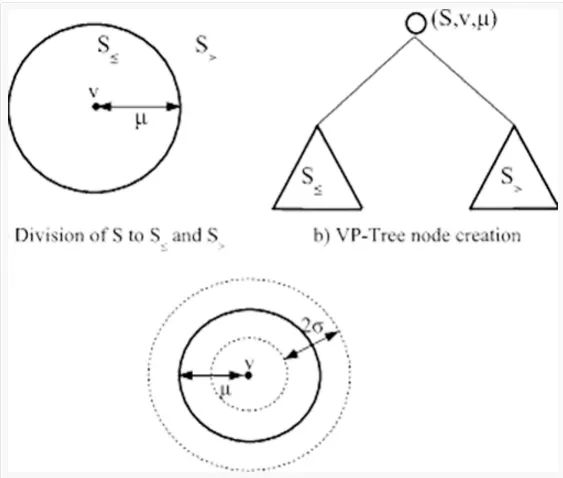
图8:构建VP树(优势点树)过程的一个可视化描述。我们将使用Richard Sjogren提供的VP树 Python实现。(图片来源)
首先,我们在空间中选择一个点(表示为圆心中的v)——我们称这个点为优势点。优势点是树中距父优势点最远的点。
然后我们计算所有点,X,的中位数,μ。
一旦我们有了μ,然后我们就将X分成两个数据子集,S1和S2:
距离<= μ 的所有点,属于S1.
距离> μ 的所有点,属于S1S2.
然后我们递归地应用这个过程,并构建一个树,直到剩下一个子节点。
一个子节点只包含一个数据点(在本例中是一个单独的哈希)。因此,树中距离较近的子节点就有:
它们之间的距离更小。
因此可以假设它们比树中的其他数据点更相似。
在递归地应用了VP树构造方法之后,我们就得到了一个数据结构,正如其名,它是一个树:
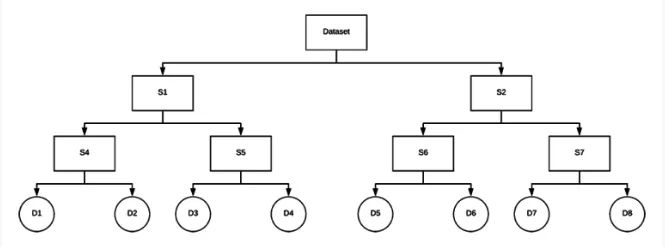
图9:描述了一个示例VP树。我们将使用Python来构建用于图像哈希搜索引擎的VP树。
注意,我们如何递归地将数据集的子集分割为越来越小的子集,直到最终到达子节点。
构建VP树需要的复杂度为O(n logn),但是一旦我们构建了它,一次搜索只需要O(logn)的复杂度,从而将我们的搜索时间减少到次线性复杂度!
在本教程的后面,您将学习使用Python利用VP树来构建和扩展我们的图像哈希搜索引擎。
注意:本节是对VP树的一个简单介绍。如果您有兴趣了解更多关于它们的内容,我建议您(1)查阅一个数据结构教科书,(2)遵循Steve Hanov博客中的这个指南,或(3)阅读Ivan Chen的这篇文章。
CALTECH-101数据集

图10:CALTECH-101数据集包含101个对象类别。我们使用了VP树、Python和OpenCV的图像哈希搜索引擎将使用CALTECH-101数据集作为我们的实际示例。
我们今天要处理的数据集是CALTECH-101数据集,它包含了跨越101个类别的9144张图片(每个类别有40到800张图片)。
该数据集足够大,您可以从介绍图像哈希的角度进行有趣的探索,但它又足够小,以至于您可以运行本指南中的示例Python脚本,而不必等待系统花费大量时间来处理这些图像。
您可以从他们的官方网页下载CALTECH 101数据集,或者您也可以使用以下wget命令:

项目结构
我们来检查一下我们的项目结构:
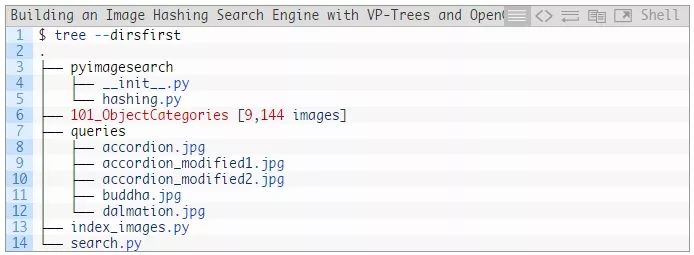
pyimagesearch模块包含hashing.py,该脚本中包含三个哈希函数。我们将在下面的“实现我们的哈希实用程序”一节中回顾这些函数。
我们的数据集在101_ObjectCategories/ 文件夹(CALTECH-101)中,其中包含了101个子目录和我们的图像。请务必阅读前一节以了解如何下载该数据集。
queries/ 目录中有5个查询图像。我们将搜索与这些图像具有相似哈希值的图像。accordion_modified1.jpg 和 accordion_modiied2.jpg图像将给我们的VP树图像哈希搜索引擎带来独特的挑战。
今天项目的核心在于两个Python脚本:index_images.py 和 search.py:
我们的indexer将计算所有9144张图片的哈希值,并将这些哈希值组织到一个VP树中。这个索引将驻留在两个.pickle文件中:(1)一个所有计算出的哈希的字典,和(2)VP树。
searcher将计算一个查询图像的哈希值,并通过汉明距离在VP树中搜索最接近的图像。结果将返回给用户。。
如果您觉得这听起来有点复杂,别担心!本教程将逐步地分解所有内容。
配置您的开发环境
对于这篇博文,您的开发环境需要安装以下软件包:
OpenCV
NumPy
imutils
vptree (VP树数据结构的纯Python实现)
幸运的是,一切都可以通过pip来安装。我的建议是,在您的系统上的虚拟环境中,按照第一个OpenCV链接来pip安装OpenCV。从这里开始,您只需在相同的环境中来pip安装其他所有东西。
它看起来是这样的:
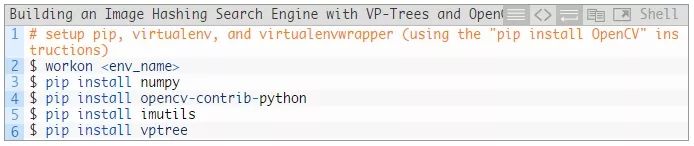
用您的虚拟环境的名称替换<env_name>。workon命令只有在您按照这些说明设置了virtualenv和virtualenvwrapper之后才可用
实现我们的图像哈希实用程序
在构建图像哈希搜索引擎之前,我们首先需要实现几个助手实用程序。
打开项目结构中的hashing.py文件,插入以下代码:
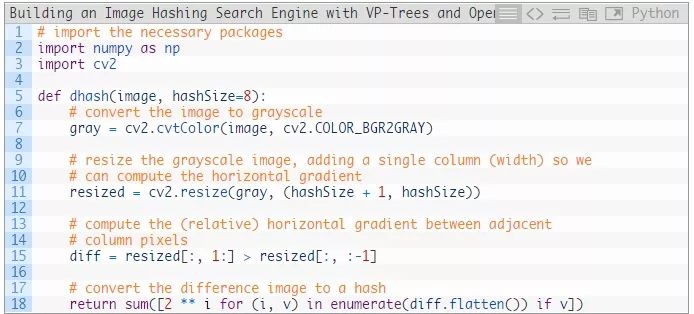
我们从导入OpenCV和NumPy(第2行和第3行)开始。
我们将看到的第一个函数是dhash,它用于计算一个给定输入图像的差异哈希。回想一下,我们的dhash需要四个步骤:(1)转换为灰度图,(2)调整大小,(3)计算差值,(4)构建哈希。让我们进一步分解一下:
第7行将图像转换为灰度图。
第11行将图像大小调整为N + 1行N列,忽略长宽比。这可以确保生成的图像哈希将能够匹配类似的照片,而不管它们的初始空间维度如何。
第15行将计算相邻列像素之间的水平梯度差。假设hashSize=8,将有8行8个差异(有9行允许8个比较)。因此,我们将得到一个64位的哈希,即8×8=64。
第18行将差异图像转换为一个hash。
获取更多细节,请参考这篇博客文章。
接下来,让我们看看convert_hash函数:

当我第一次为本教程编写代码时,我发现我们在内部使用的VP树实现将哈希转换为一个NumPy 64位浮点数。这当然是可以的;然而,哈希值必须是整数,如果我们将它们转换为64位浮点数,它们就会变成一个不可哈希的数据类型。为了克服此VP树实现的局限性,我想出了convert_hash 方法:
我们接受一个输入哈希h。
然后将这个哈希值转换成一个NumPy 64位浮点数。
接着再将这个NumPy浮点数转换回Python的内置整数数据类型。
这种方法可以确保哈希值在整个哈希、索引和搜索过程中表示一致。
然后我们有最后一个辅助方法——hamming,用它来计算两个整数之间的汉明距离:

当在两个整数之间取XOR(^)时,汉明距离就是1的数目的count(第27行)。
实现我们的图像哈希索引器
在执行一次搜索之前,我们首先需要:
对我们的输入图像数据集进行循环。
为每个图像计算差分哈希值。
使用这些哈希值构建一个VP树。
让我们现在就开始这个过程。
打开index_images.py文件,并插入以下代码:
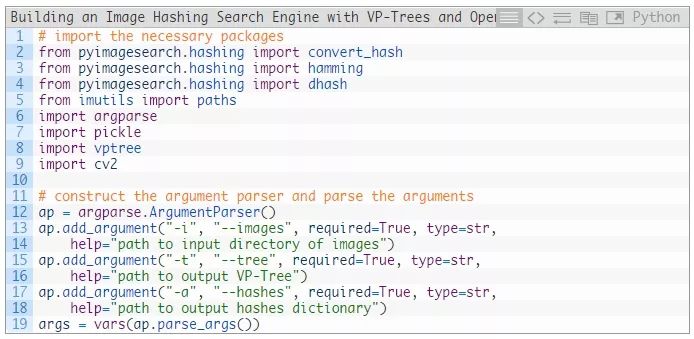
第2-9行导入了此脚本所需的包、函数和模块。特别是第2-4行导入了三个与哈希相关的函数:convert_hash 、hamming 和 dhash。第8行导入了我们将要使用的VP树实现。
接下来,第12-19行解析我们的命令行参数:
--images : 我们将要索引的图像的路径。
--tree :将要序列化到磁盘的输出VP树.pickle文件的路径。
--hashes :将以.pickle格式存储的输出哈希字典的路径。
现在让我们来计算所有图像的哈希值:
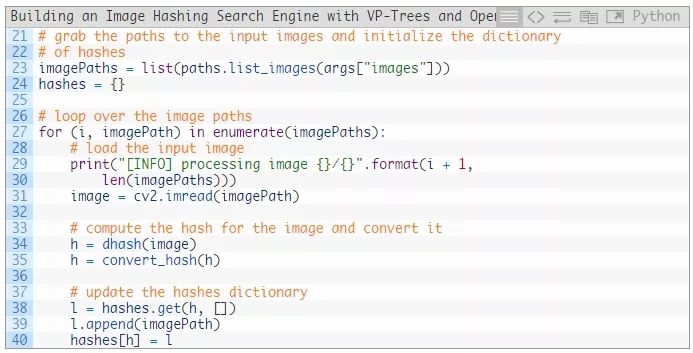
第23和24行获取图像路径并初始化我们的hashes字典。
第27行开始循环所有的 imagePaths。在这个循环内部,我们:
加载 image (第31行)。
计算并转换哈希h(第 34行和35行)。
获取一个所有图像路径的列表l,其中带有同样的哈希值。(第38行)。
将这个imagePath添加到列表l (第39行)。
以哈希值作为键,并以带有相同的对应的哈希值的图像路径列表作为值来更新我们的字典(第40行)。
接着,我们来构建我们的VP树:

为了构造VP树,第44行和第45行传入(1)一个数据点列表(即哈希整数值本身),(2)我们的距离函数(汉明距离方法)到该VPTree构造器。
在内部,该VP树计算所有输入points之间的汉明距离,然后构造VP树,这使得距离较小的数据点(即更相似的图像)在树空间中靠得更近。一定要参考“什么是VP树,以及它们如何帮助我们扩展图像哈希搜索引擎?”章节和图7、8、9。
在填充了hashes字典并构造了VP树之后,我们现在将它们作为.pickle文件序列化到磁盘上:
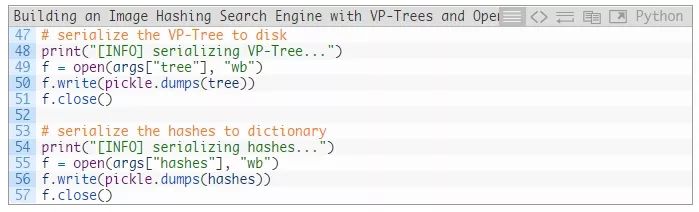
提取图像哈希并构建VP树
现在我们已经实现了我们的索引脚本,让我们开始使用它吧。确保您已经:
使用上面的说明下载了CALTECH-101数据集。
使用本教程的“下载”部分下载了源代码和示例查询图像。
提取了源代码的.zip包并将目录更改为项目目录。
然后,打开终端并发出以下命令:
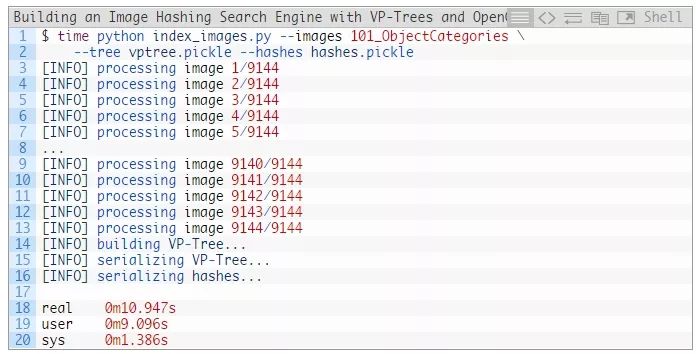
正如我们的输出所示,我们能够在10秒内哈希完所有的9144个图像。
运行脚本后检查项目目录,我们会发现两个.pickle文件:

hashes.pickle (796.62KB)文件包含我们计算得到的哈希值,并将哈希整数值映射到具有相同哈希值的文件路径。vptree.pickle (707.926KB)是我们构建的VP树。
在下一节中,我们将使用这个VP树来执行查询和搜索。
实现我们的图像哈希搜索脚本
图像哈希搜索引擎的第二个组成部分是搜索脚本。该搜索脚本将:
接受一个输入查询图像。
计算查询图像的哈希值。
使用该查询哈希值搜索VP树,找出所有重复/接近重复的图像。
现在让我们实现我们的图像哈希搜索器——打开 search.py文件并插入以下代码:
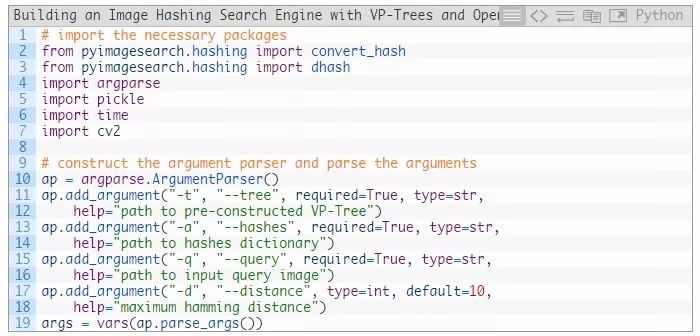
第2-9行导入了我们的搜索脚本所需的组件。注意,我们需要再次使用dhash和convert_hash函数,因为我们必须为我们的--query图像计算哈希值。
第10-19行解析我们的命令行参数(前三个是必需的):
--tree : 我们预先构建的VP树的磁盘路径。
--hashes : 我们预先计算的哈希值字典的磁盘路径。
--query : 我们的查询图像的路径。
--distance :哈希值之间的最大汉明距离,设置有一个default值10。您也可以覆盖它。
需要注意的是--distance越大,VP树将比较的哈希值就越多,因此搜索器的速度就越慢。在不影响结果质量的前提下,尽量保持您的--distance尽可能的小。
接下来,我们将(1)加载我们的VP树+哈希字典,和(2)计算我们的--query图像的哈希值:
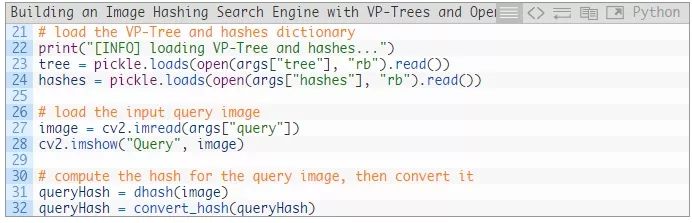
第23行和第24行加载预计算得到的索引,包括VP树和hashes字典。
接着,我们加载并显示--query图像(第27行和第28行)。
然后我们获取查询image并计算queryHash(第31行和第32行)。
此时,是时候使用我们的VP树来执行一次搜索了:
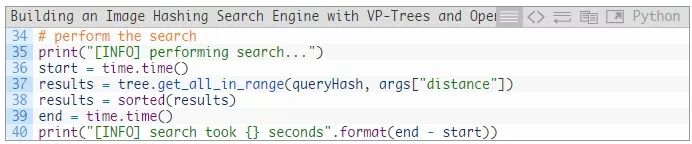
第37和38行通过在VP树中查询相对于queryHash来说汉明距离最小的哈希值来执行一次搜索。然后对results进行排序,使“更相似的”哈希值位于results列表的前面。
为了进行基准测试,这两行中间都有时间戳,其结果通过第40行打印出来。
最后,我们将对results进行循环并显示每一个值:
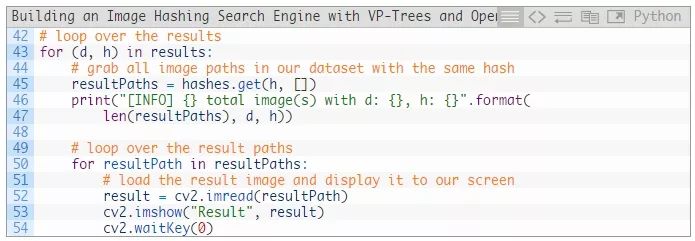
第43行开始对results进行循环:
当前哈希值h的resultPaths被从哈希字典中获取(第45行)。
当键盘上的一个键被按下时,每一个 result图像将被显示(第50-54行)。
图像哈希搜索引擎的结果
我们现在准备测试我们的图像搜索引擎!
但在此之前,请确保您已经:
使用上面的说明下载了CALTECH-101数据集。
使用本教程的“下载”部分下载了源代码和示例查询图像。
提取了源代码的.zip包并将目录更改为项目目录。
运行了index_images.py文件去生成hashes.pickle 和 vptree.pickle文件。
完成以上步骤后,打开终端,并执行以下命令:
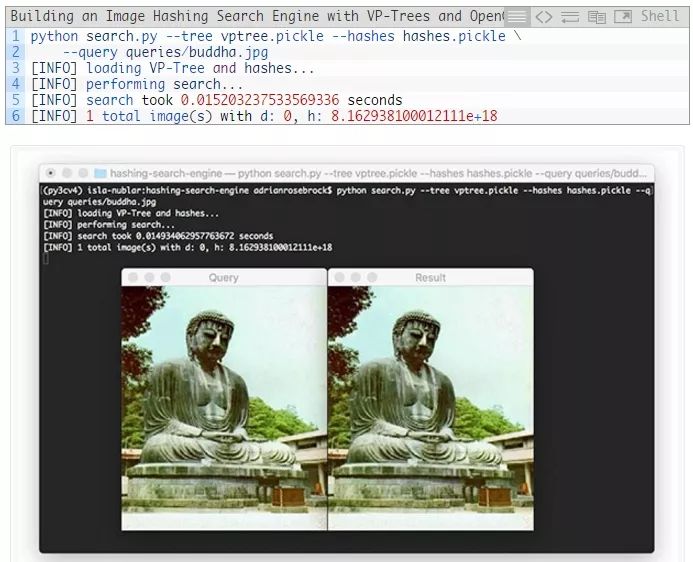
图11:我们的Python + OpenCV图像哈希搜索引擎在0.015秒内就在VP树中找到了一个匹配项!
在左侧,您可以看到我们的佛陀输入查询图像。在右边,您可以看到我们已经在我们索引的数据集中找到了重复的图像。
搜索本身只花了0.015秒。
此外,请注意输入查询图像和数据集中哈希后的图像之间的距离为零,这表明这两幅图像是相同的。
让我们再试一次,这次是一张达尔马提亚犬的图像:
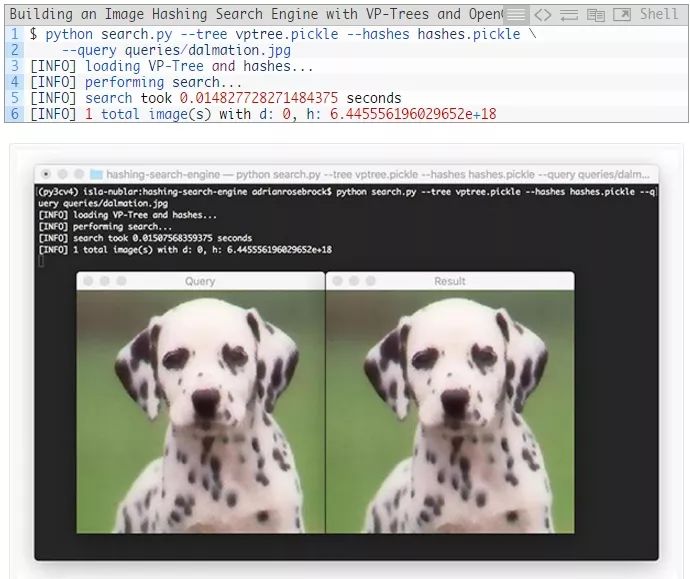
图12:在汉明距离为0的情况下,达尔马提亚犬查询图像生成了数据集中一个相同的图像。我们成功地使用VP树构建了一个OpenCV + Python图像哈希搜索引擎。
同样,我们看到我们的图像哈希搜索引擎已经在我们索引后的数据集中找到了相同的达尔马提亚犬(由于汉明距离为零,我们知道两张图像是相同的)。
下一个例子是一个手风琴:
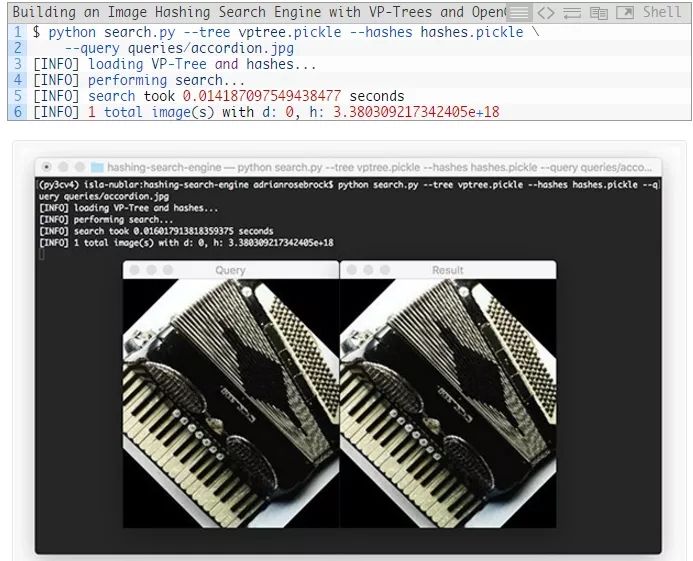
图13:使用由Python和OpenCV创建的图像哈希搜索引擎提供一个查询图像并查找最佳结果图像的示例。
我们再次在索引后的数据集中找到了相同的匹配图像。
现在,我们知道我们的图像哈希搜索引擎对相同的图像来说运行的很棒…
...但是对稍微修改过的图像又怎样呢?
我们的哈希搜索引擎还会有好的表现吗?
让我们试一试:
图14:我们的图像哈希搜索引擎仍然能够找到匹配的图像,尽管对查询图像进行了修改(红方块)。
这里,我在手风琴查询图像的左下角添加了一个小红方块。这个添加将改变成不同的哈希值。
但是,如果您查看输出结果,您会看到我们仍然能够检测到接近重复的图像。
通过比较哈希值之间的汉明距离,我们能够找到近似重复的图像。哈希值的差异是4,表示两个哈希值之间有4位不同。
接下来,让我们尝试第二个查询,这个查询比第一个修改得多:
图15:左边是带有VP树的图像哈希搜索引擎的查询图像。它已经被我们用黄色和紫色的形状以及红色的文字修改了。该图像哈希搜索引擎在0.0137秒内从索引9,144处返回了正确的结果图像(右),这证明了我们的搜索引擎系统的健壮性。
尽管通过添加一个大的蓝色矩形、一个黄色圆圈和文本来极大地改变了查询,但我们仍然能够在0.014秒内在数据集中找到几乎相同的图像!
当您需要在一个数据集中找到重复或接近重复的图像时,一定要考虑使用图像哈希和图像搜索算法——如果使用正确,它们可以非常强大!
总结
在本教程中,您学习了如何使用OpenCV和Python构建一个基本的图像哈希搜索引擎。
要构建一个可伸缩的图像哈希搜索引擎,我们需要使用VP树,这是一种特殊的度量树数据结构,它递归地划分一个数据集的点,使得距离较近的树节点比距离较远的节点更相似。
通过使用VP树,我们能够构建一个图像哈希搜索引擎,它能够在0.01秒内在一个数据集中找到重复和接近重复的图像。
此外,我们还演示了哈希算法和VP树搜索的组合能够在我们的数据集中找到匹配项,即使我们的查询图像被修改、损坏或改变!
如果您曾经构建过一个需要在大型数据集中快速查找重复或近似重复图像的计算机视觉应用程序,那么您一定要尝试一下这种方法。
下载
英文原文:https://www.pyimagesearch.com/2019/08/26/building-an-image-hashing-search-engine-with-vp-trees-and-opencv/
译者:一瞬
以上是关于使用VP树和OpenCV构建一个图像哈希搜索引擎的主要内容,如果未能解决你的问题,请参考以下文章