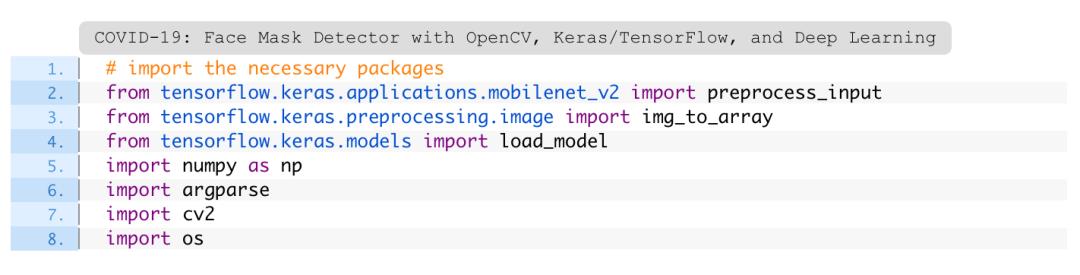
牛逼!大神用OpenCV/Keras/TensorFlow实现口罩检测
Posted CVer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了牛逼!大神用OpenCV/Keras/TensorFlow实现口罩检测相关的知识,希望对你有一定的参考价值。
重磅干货,第一时间送达
作者:Adrian Rosebrock |
编译:安然
新冠肺炎疫情的出现,给刷脸支付行业造成重大打击的同时,也会为其提供新的机遇。关于“戴口罩能否人脸识别检测”的问题,引起了众多的疑虑。
近日,微软大神Adrian Rosebrock在新出的一篇教程中讲述了如何使用OpenCV、Keras/TensorFlow和Deep Learning训练口罩检测器。
在本教程中,我们将讨论二阶段口罩检测器,并详细说明如何实现计算机视觉/深度学习管道。
查看用于训练自定义口罩检测器的数据集,展示如何在数据集使用Keras和TensorFlow上实现Python脚本训练口罩检测器,使用此Python脚本来训练口罩检测器并查看结果。
鉴于训练有素的口罩检测器,将另外两个Python脚本用于:
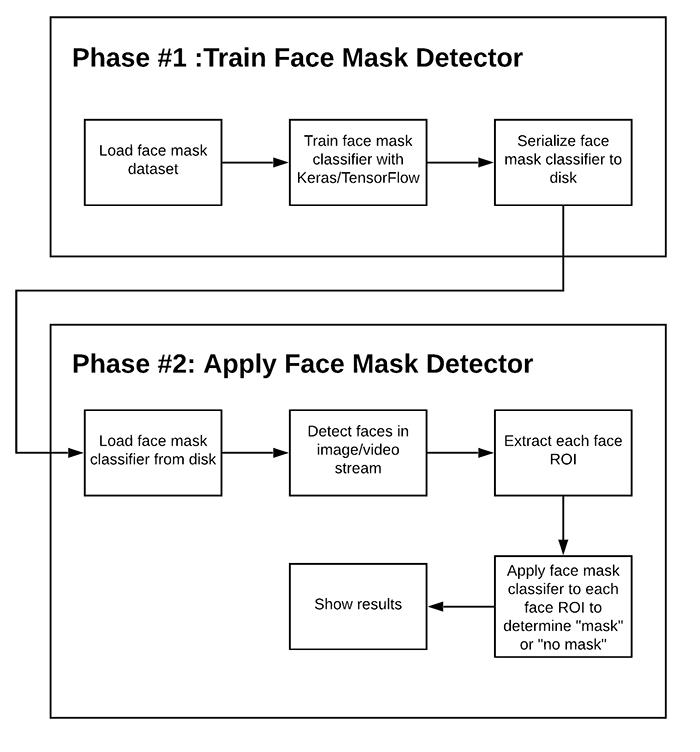
图1:使用Python,OpenCV和TensorFlow / Keras构建具有计算机视觉和深度学习功能的COVID-19口罩检测器的阶段和步骤。
为了训练自定义的口罩检测器,将该项目分为两个阶段,每个阶段都有自己的子步骤(如图1所示):
这里使用的数据集是由PyImageSearch读者Prajna Bhandary创建的。
图2:口罩检测数据集由“带口罩”和“不带口罩”图像组成。使用该数据集构建一个使用Python、OpenCV和TensorFlow/Keras进行计算机视觉和深度学习的口罩检测器。
使用的数据集包含1,376张图像,这些图像属于两个类别:
我们目标是训练一个自定义的深度学习模型来检测一个人是否佩戴口罩。
Prajna和我一样,对世界的现状感到沮丧和沮丧——每天都有成千上万的人死去,对许多人来说,能做事情的很少。
为了保持精神饱满,Prajna决定通过运用计算机视觉和深度学习来解决现实世界的问题:
程序员、开发人员和计算机视觉/深度学习的实践者,都可以从Prajna的书中有所收获。
为了创建这个数据集,Prajna运用了一个巧妙的解决方案:
然后创建一个自定义的计算机视觉Python脚本,将口罩添加到这些人像的面部,从而创建一个人工(但仍然适用于现实世界)的数据集。
这个方法实际上比听起来要简单得多,只要运用面部landmarks即可。
面部landmarks可自动推断面部结构位置,包括:
要使用人脸landmarks来建立一个戴口罩的面部数据集,首先需要从一个未戴口罩的人像开始:
图3:构建口罩数据集,首先从一张未戴口罩的人像照片开始
图4:应用人脸检测,使用深度学习方法来使用OpenCV进行面部检测
一旦知道了人脸在图像中的位置,就可提取人脸感兴趣区域(ROI)
图5:使用OpenCV和NumPy切片提取人脸ROI
然后从那里应用面部landmarks,定位眼睛,鼻子,嘴巴等:
图6:使用dlib检测面部landmarks,检测口罩放置位置
接下来,需要一张带有透明背景的口罩图像,如下图所示:
图7:口罩示例。由于已知面部landmark位置,因此将口罩自动覆盖在人像面部ROI上
通过使用面部landmarks(即沿着下巴和鼻子的点)来计算口罩的放置位置,旋转、调整口罩的大小,将其自动置于面部。
图8:在该图中,口罩按原帧放置于人脸,很难看出口罩已通过OpenCV和dlib人脸landmarks应用于计算机视觉
然后,可以对所有输入的图像重复该过程,从而创建人工口罩数据集:
图9:一组人工合成的口罩图像, 该集合将成为我们的“有口罩” /“无口罩”数据集的一部分,该数据集将用于使用OpenCV,Keras / TensorFlow和深度学习训练口罩检测器。
但是,在使用此方法人工创建数据集时,需要注意:如果使用一组图像来创建一个戴口罩的人工数据集,不能在训练集中“重复使用”未戴口罩的人像图,仍然需要收集不同的未带口罩的人像图。
如果将用于生成戴口罩的原始图像作为未戴口罩的样本包含在内,模型将会产生严重的偏差,且不能很好地泛化。为了避免这种情况,无论如何都要花时间收集一些未戴口罩的新人像。
使用面部landmarks将口罩放置于面部的方法不在讨论范围之内,但是,如果您想了解更多信息,我建议:
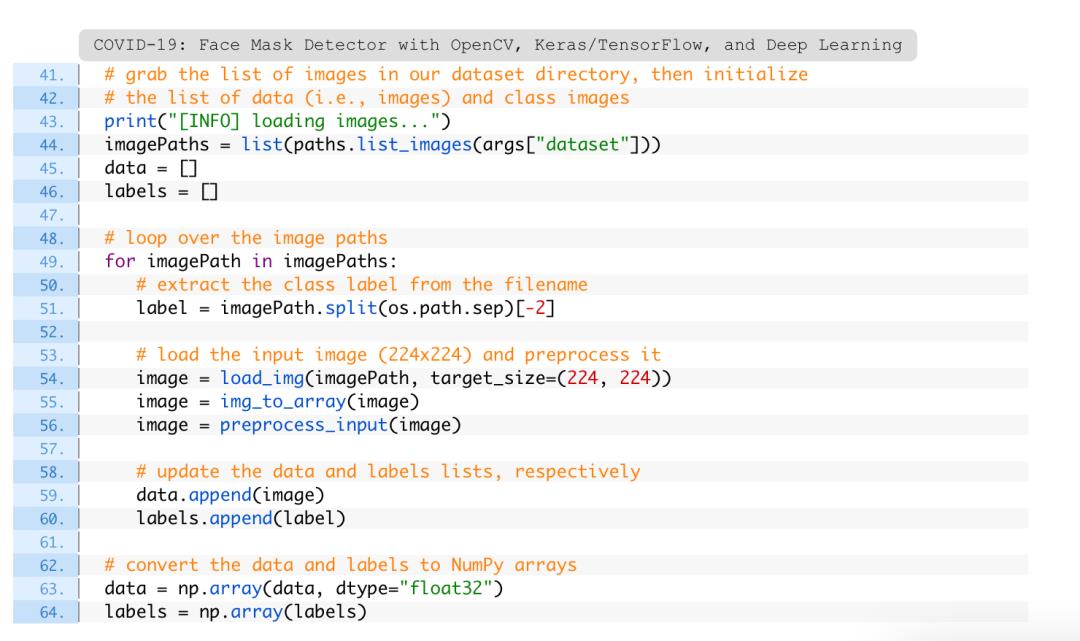
原理与该教程相同,构建一个人工口罩数据集-使用面部landmarks来推断面部结构,旋转并调整口罩大小,然后将其应用于图像。
使用Keras和TensorFlow运行口罩检测器训练脚本
查看口罩数据集后,学习如何使用Keras和TensorFlow训练分类器来自动检测一个人是否戴着口罩。
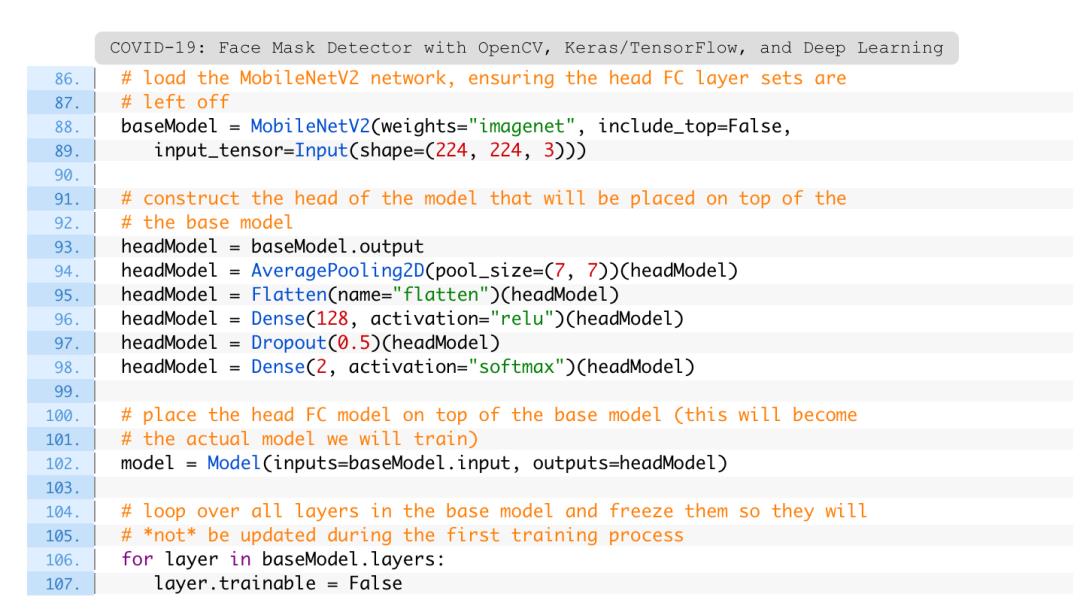
为了完成此任务,对MobileNet V2架构进行微调,该架构是一种高效的架构,可以应用于计算能力有限的嵌入式设备(例如,Raspberry Pi,Google Coral,NVIDIA Jetson Nano等)。
将口罩检测器部署到嵌入式设备可以降低制造此类口罩检测系统的成本,因此这也是选择使用该体系结构的原因。
在目录结构中打开train_mask_detector.py文件,并插入以下代码:
使用scikit-learn (sklearn)对类标签进行二值化,对数据集进行分段,并打印分类报告。
imutils路径实现将帮助在数据集中查找和列出图像。使用matplotlib来绘制训练曲线。
在这里,我指定了超参数常量,包括初始学习率,训练次数和批量大小。稍后将应用学习率衰减时间表,这就是为什么将学习率变量命名为INIT_LR。
上面的代码行是假定数据集适合内存。如果数据集大于可用的内存,则建议使用HDF5,
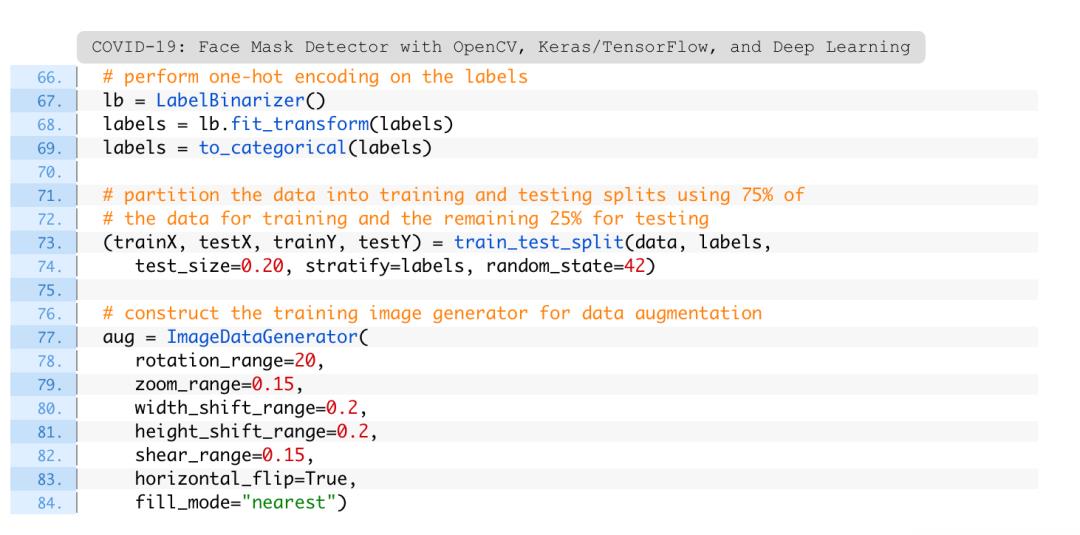
数据准备工作尚未完成。接下来,将对标签进行编码,对数据集进行分区,并为数据扩充做准备:
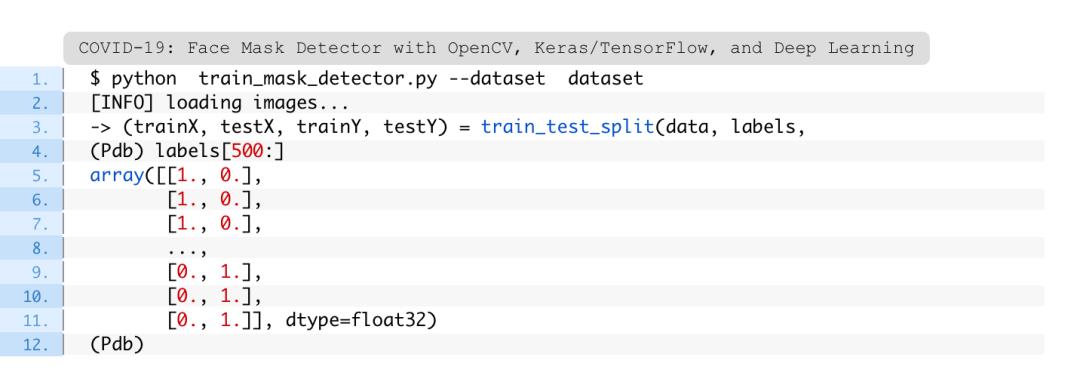
第67-69行单行编码类标签,这意味着数据将采用以下格式:
标签数组的每个元素都由一个数组组成,其中只有一个索引是“hot”(即1)。
第73行和第74行使用scikit-learn将数据划分为80%的训练数据和20%的测试数据。
在训练期间,在图像中应用动态突变,以提高泛化能力。这被称为数据增强,其中在第77-84行建立了随机旋转、缩放、剪切、移位和翻转参数,在训练时使用aug对象。
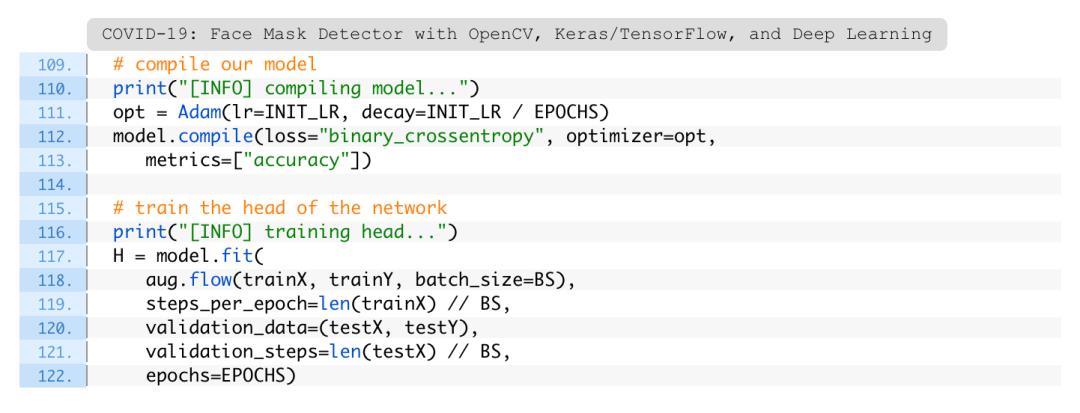
准备好数据和模型架构进行微调后,就可以编译和训练口罩检测器网络了:
第111-113行使用Adam优化器,学习率衰减时间表和二进制交叉熵来编译模型。
如果使用大于2训练脚本进行构建,请确保使用分类交叉熵。
口罩训练是通过117-122行启动的。请注意,数据增强对象(aug)将如何提供批量的突变图像数据。
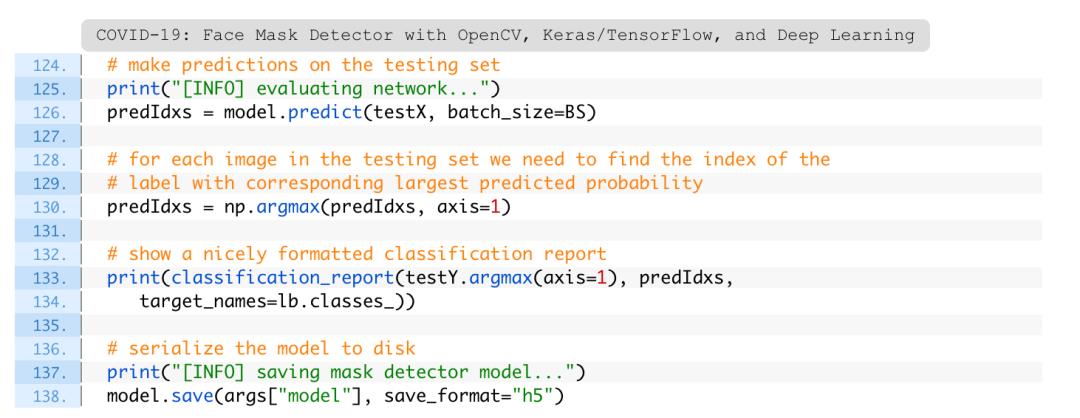
第126-130行对测试集进行预测,获取最高概率的类标签索引。然后在终端打印一份分类报告进行检验。
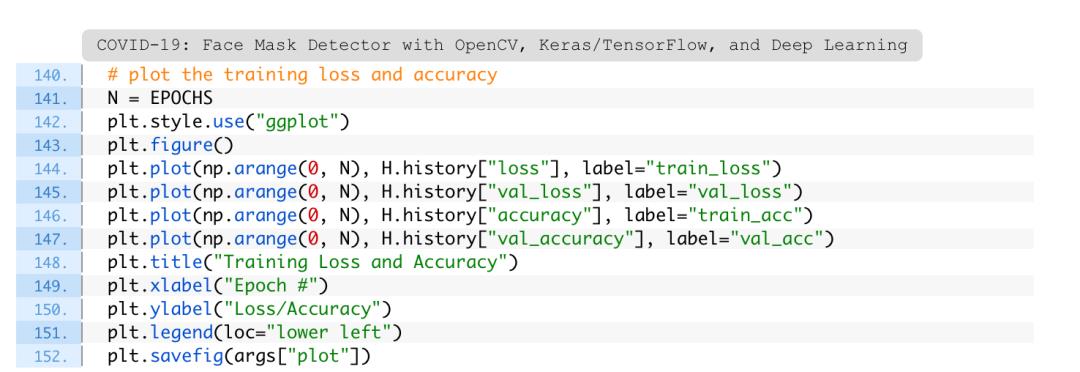
准备好图,第152行使用——plot文件路径将图保存到硬盘。
使用Keras/TensorFlow对口罩检测器进行训练
现在,使用Keras,TensorFlow和Deep Learning训练口罩检测器。
确保已使用本教程的“下载”部分来下载源代码和口罩数据集。
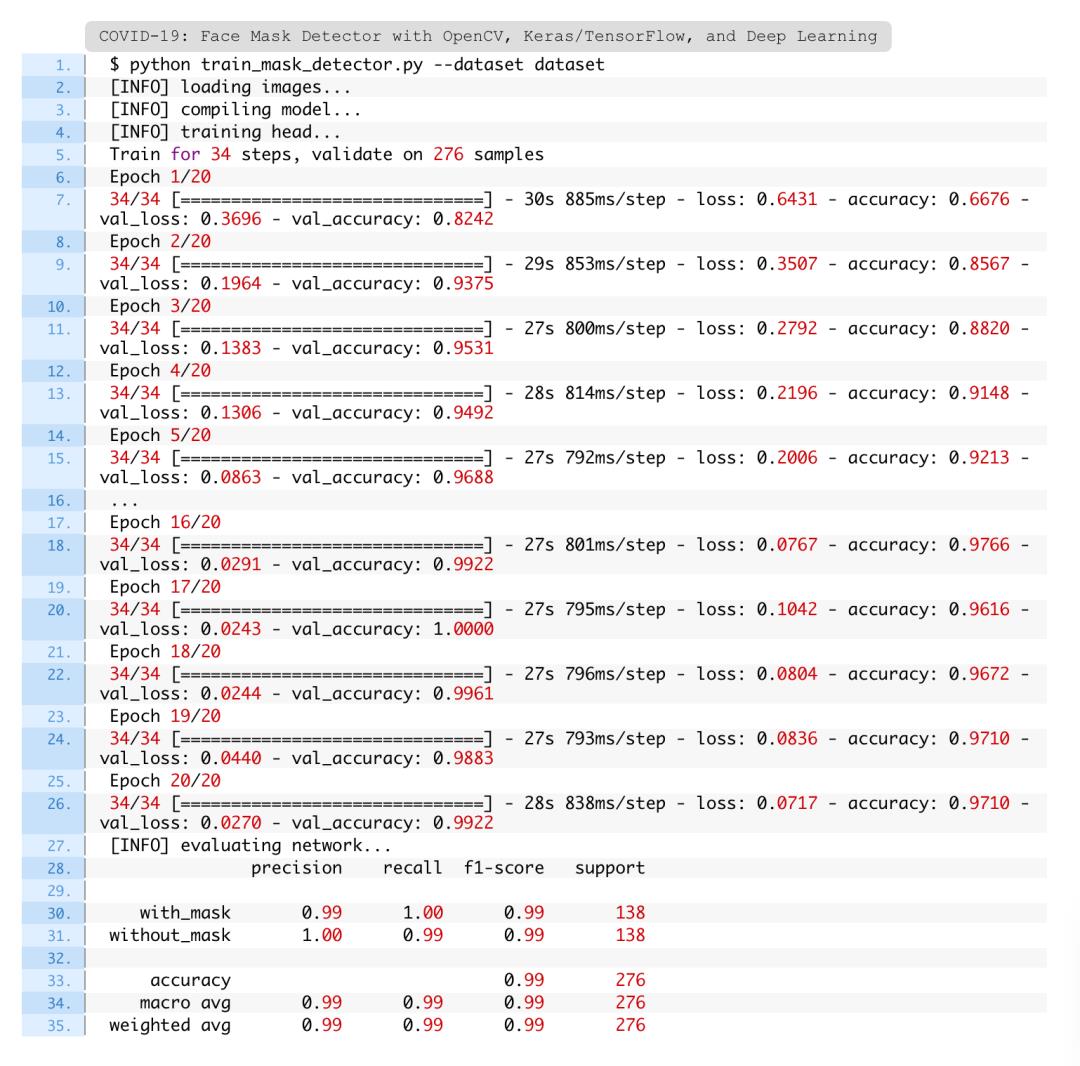
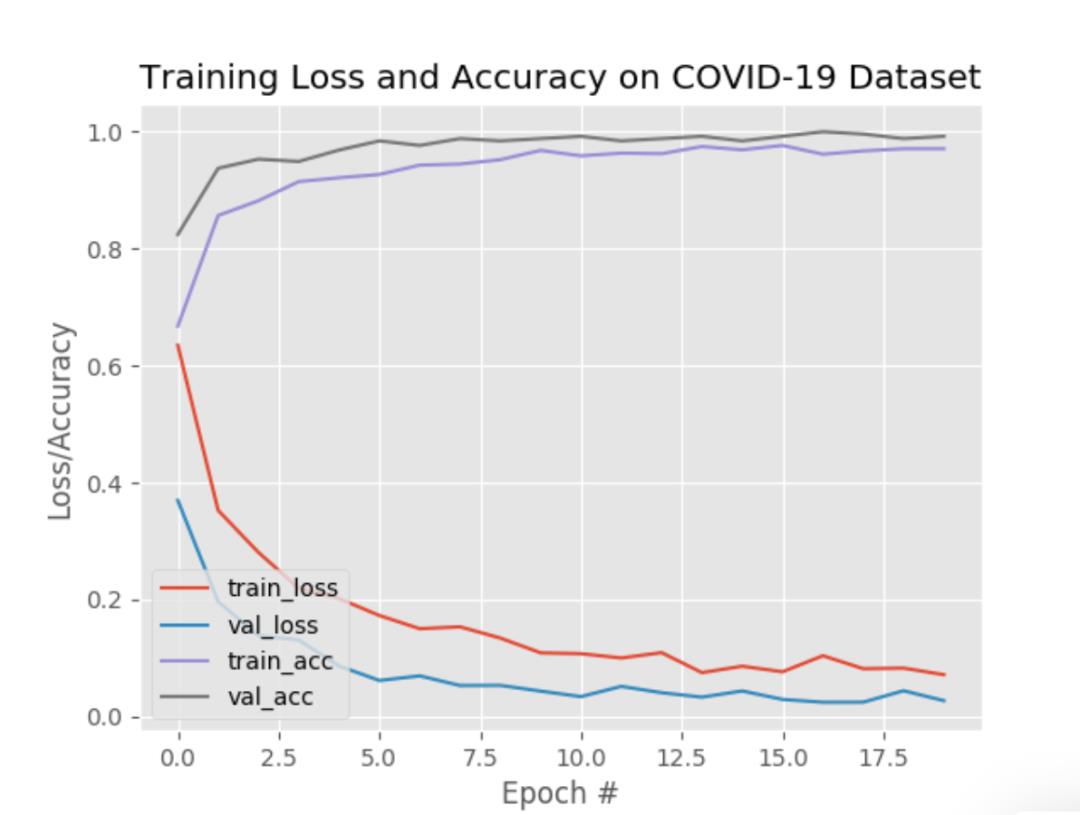
图10:COVID-19口罩检测器的训练精度/损耗曲线显示出高精度,并且在数据上几乎没有过度拟合的迹象。现在,使用Python,OpenCV和TensorFlow / Keras应用计算机视觉和深度学习知识来执行面部口罩检测。
如图10,可以看到有一些过度拟合的迹象,验证损失低于训练损失
鉴于这些结果,希望模型能够很好地推广到训练和测试集以外的图像。
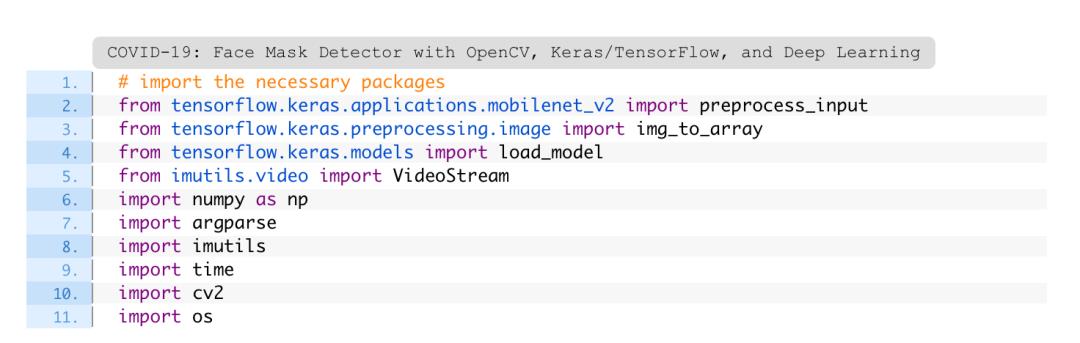
打开目录结构中的detect_mask_image.py文件:
驱动程序脚本需要三个TensorFlow / Keras导入才能加载MaskNet模型和预处理输入图像。
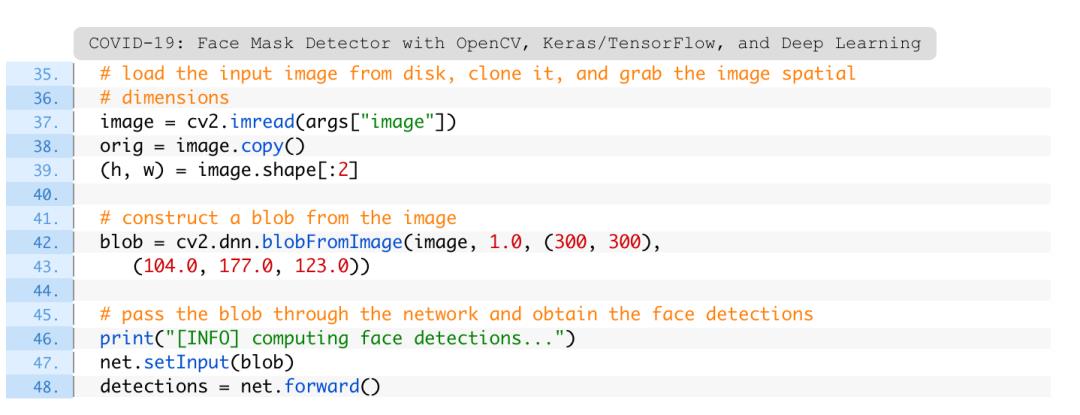
有了深度学习模型,下一步就是加载和预处理输入图像:
从硬盘加载image(第37行)之后,复制并获取帧尺寸,以便将来进行缩放和显示(第38行和第39行)。
预处理由OpenCV的blobFromImage函数处理(第42行和第43行)。如参数所示,将大小调整为300×300像素,并执行均值减法。
第47行和第48行执行人脸检测,以定位图像中所有人脸的位置。
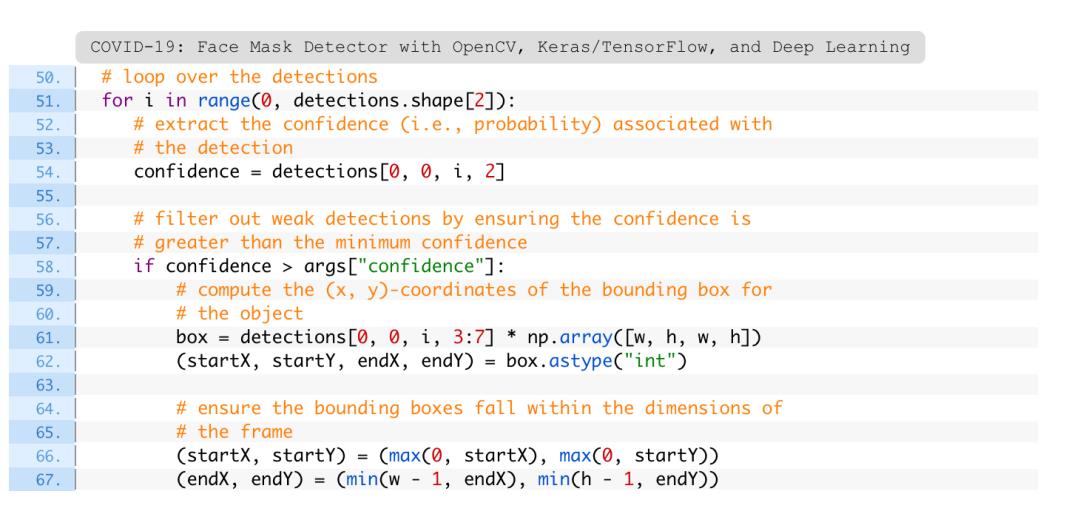
一旦知道图像中脸的预测位置,确保它们在提取面部ROIs之前达到置信阈值:
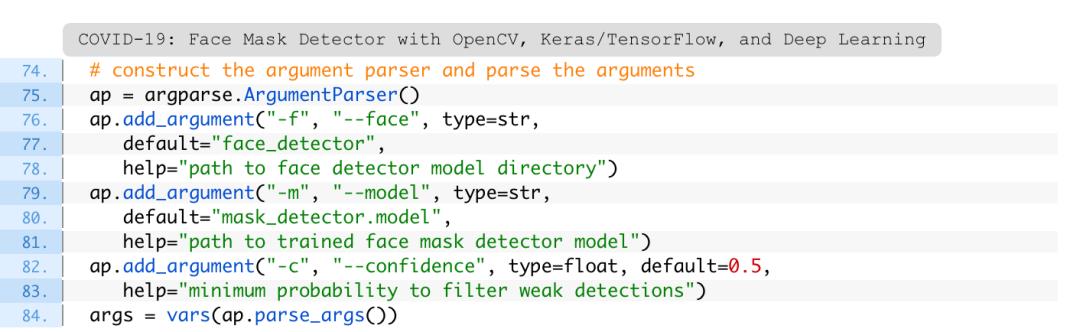
在这里,遍历检测结果,并提取置信度以针对置信阈值进行测量(第51-58行)。
然后,计算特定面部的边界框值,并确保该框位于图像的边界内(第61-67行)。
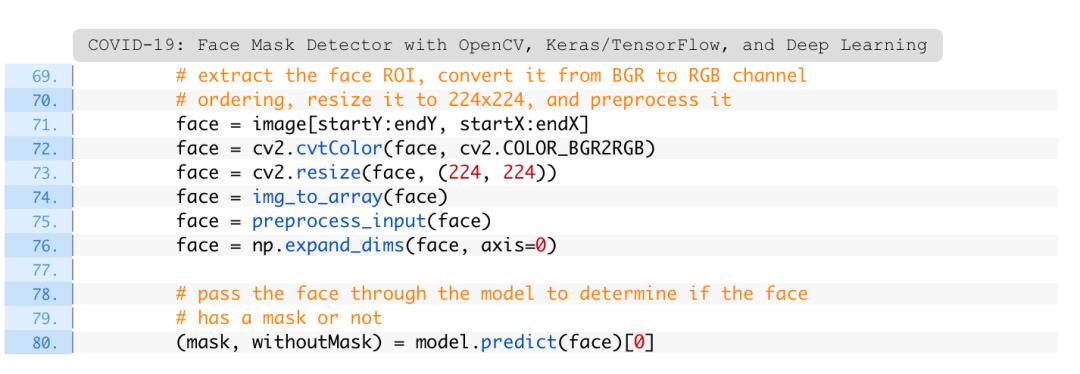
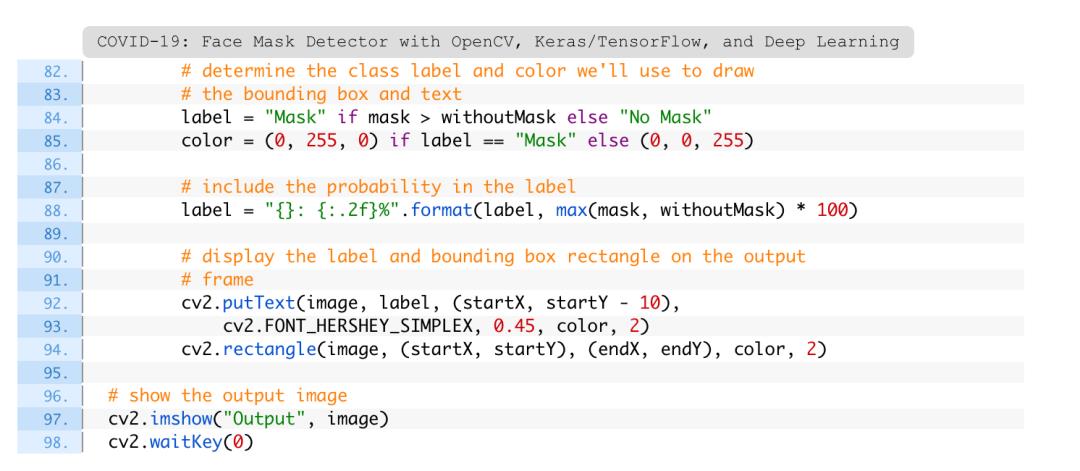
首先,根据口罩检测器模型返回的概率来确定类标签(第84行),并为注释分配一个关联的颜色(第85行)。
戴口罩的颜色为“绿色”,未戴口罩的颜色为“红色”。
然后,使用OpenCV绘图函数(第92-94行)绘制标签文本(包括类和概率),以及用于face的包围框矩形。
一旦所有的检测都处理完毕,第97行和第98行显示输出图像。
确保已使用本教程的“下载”部分来下载源代码,示例图像和预训练的口罩检测器。
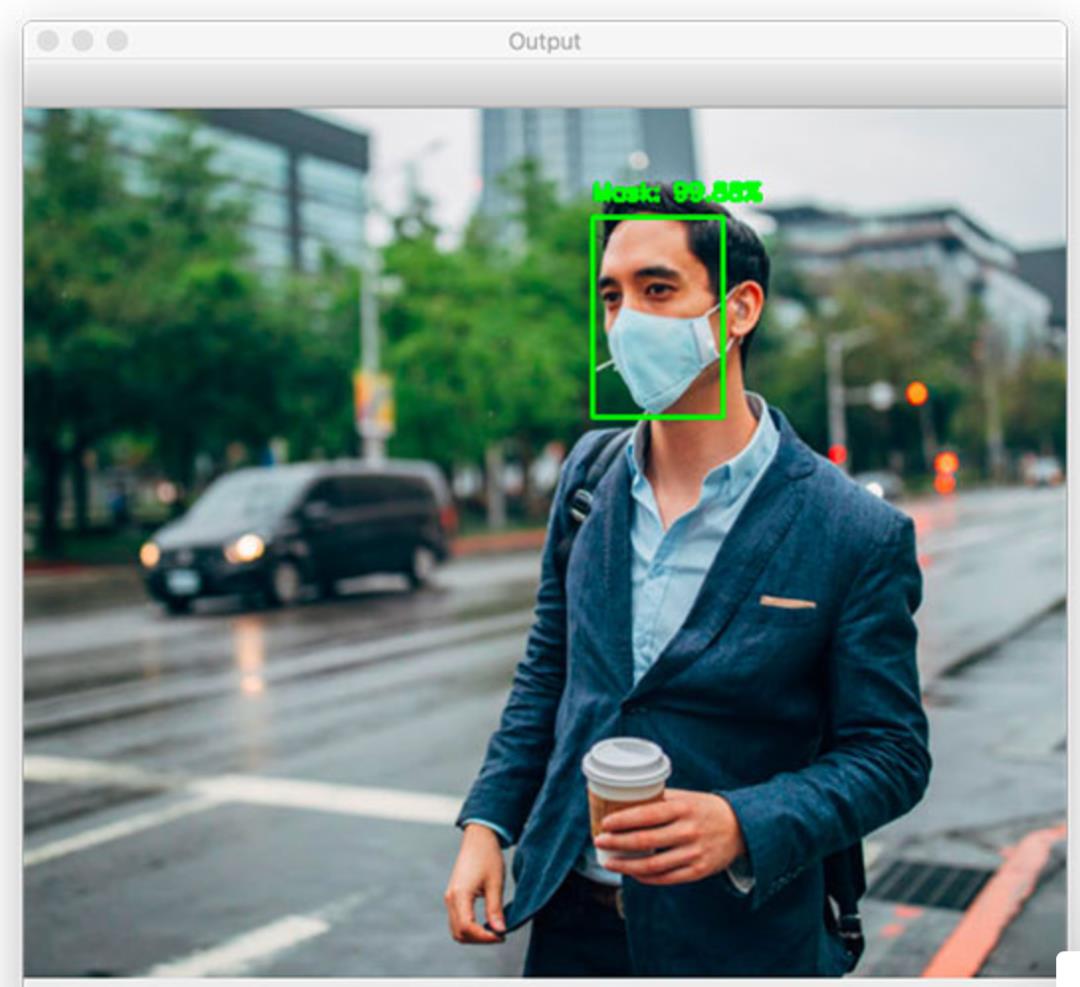
图11:此人是否在公共场合戴口罩?是的。使用Python,OpenCV和TensorFlow / Keras的计算机视觉和深度学习方法使自动检测口罩成为可能。
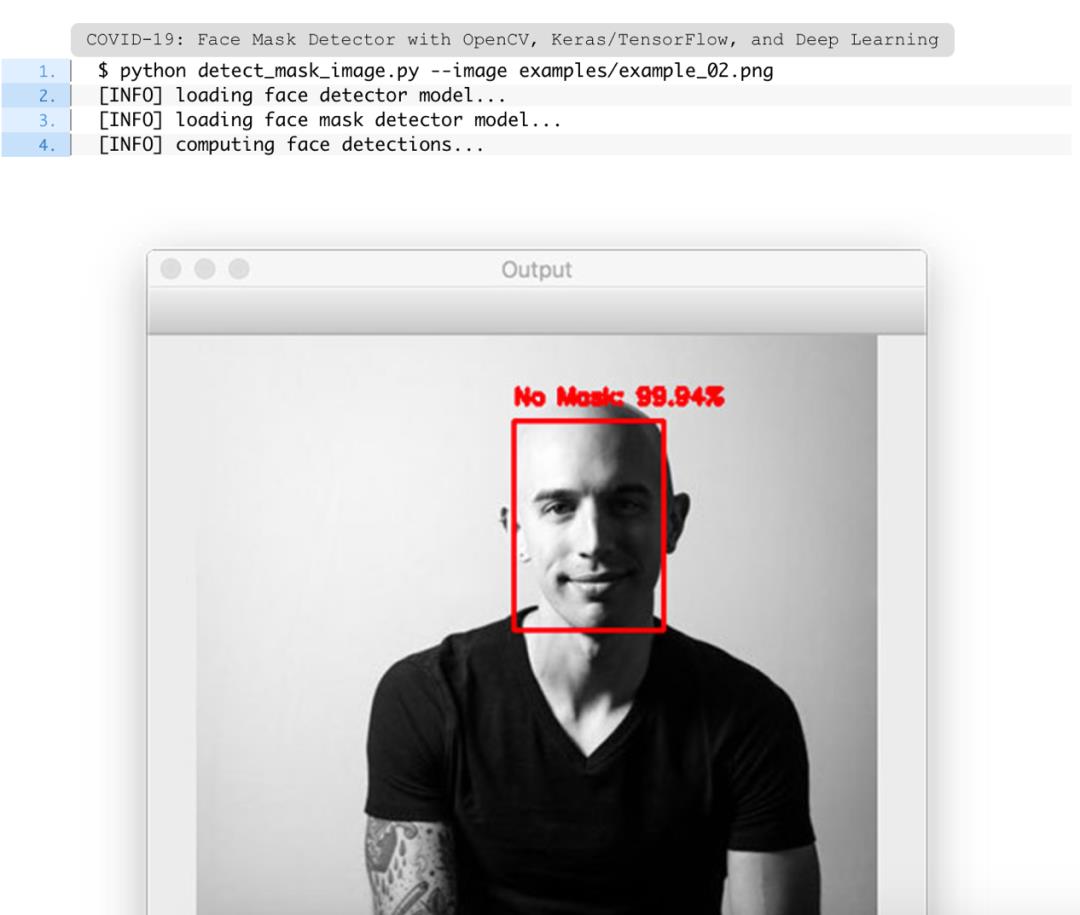
图12:这张照片中的人没有戴口罩。使用Python,OpenCV和TensorFlow / Keras,系统已正确检测到脸部“无口罩”。
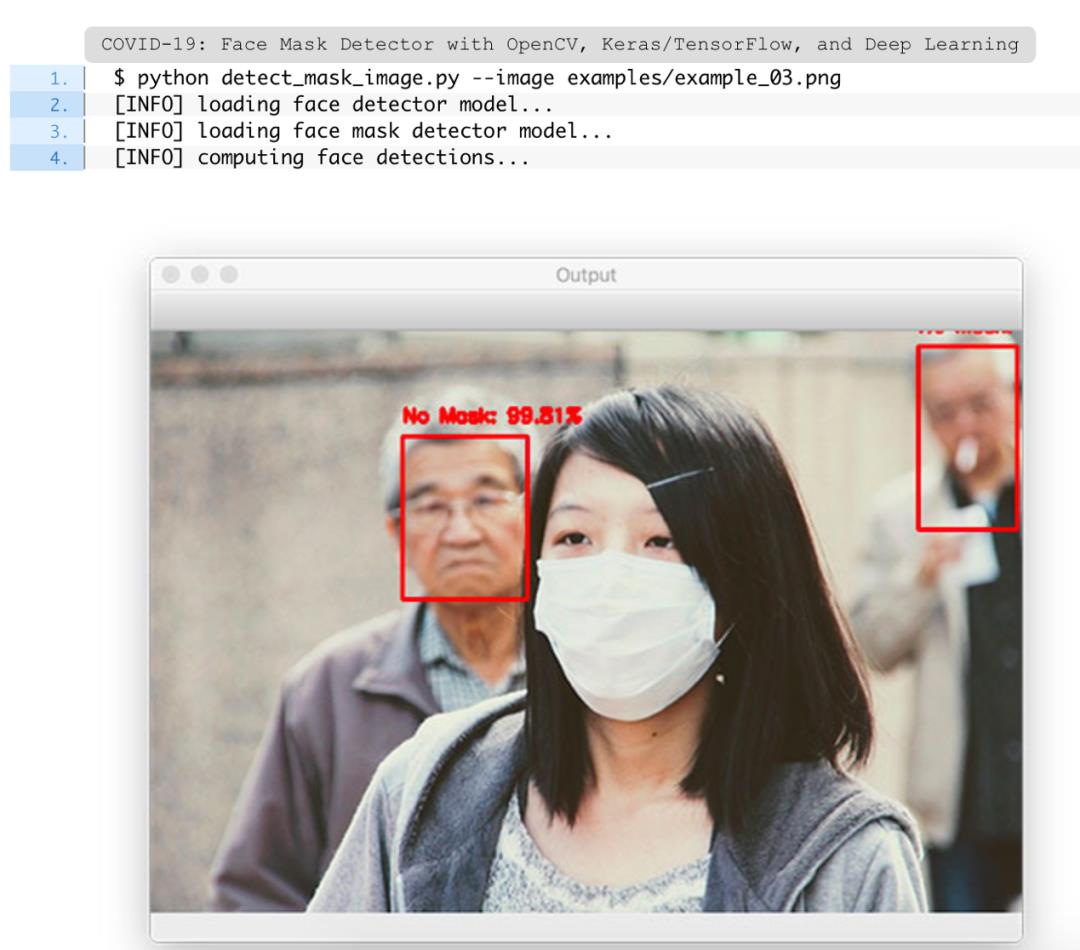
图13:这个结果中发生了什么?为什么前景中的女士没有被检测到戴着口罩?使用Python、OpenCV和TensorFlow/Keras构建的具有计算机视觉和深度学习功能的口罩检测器是否让我们失望了?
为什么能够检测到背景中两位先生的脸,并为他们正确地分类戴口罩/未戴口罩,但却无法检测到前景中的女人?
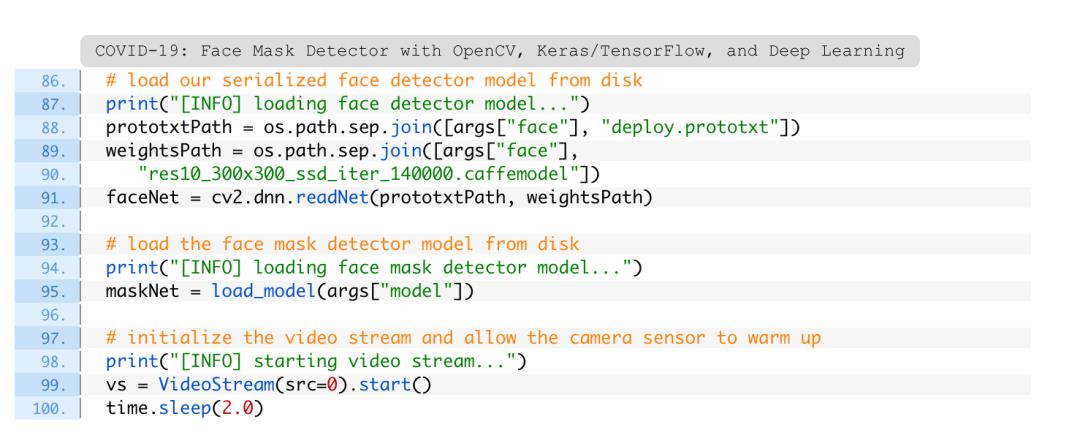
在本教程后面的“进一步改进的建议”一节中讨论了这个问题的原因,但是要点是过于依赖两阶段过程。
请记住,为了区分一个人是否戴着口罩,首先需要进行人脸检测——如果没有找到一张脸(在这张图片中发生了什么),那么就不能使用口罩检测器!
因此,如果面部的大部分被遮挡,口罩检测器很可能无法检测到面部。
同样,在本教程的“进一步改进的建议”一节中更详细地讨论这个问题,包括如何提高口罩检测器的精度。
至此,该系统可以对静态图像应用口罩检测了,但是实时视频流又如何呢?
在目录结构中打开detect_mask_video.py文件,并插入以下代码:
这个脚本的算法是相同的,但它是拼凑在一起,以允许处理网络摄像头的每一帧。
因此,当涉及到导入时,惟一的区别是需要一个VideoStream类和时间。这两种方法都可以处理流。还将利用imutils的方面感知尺寸调整方法。
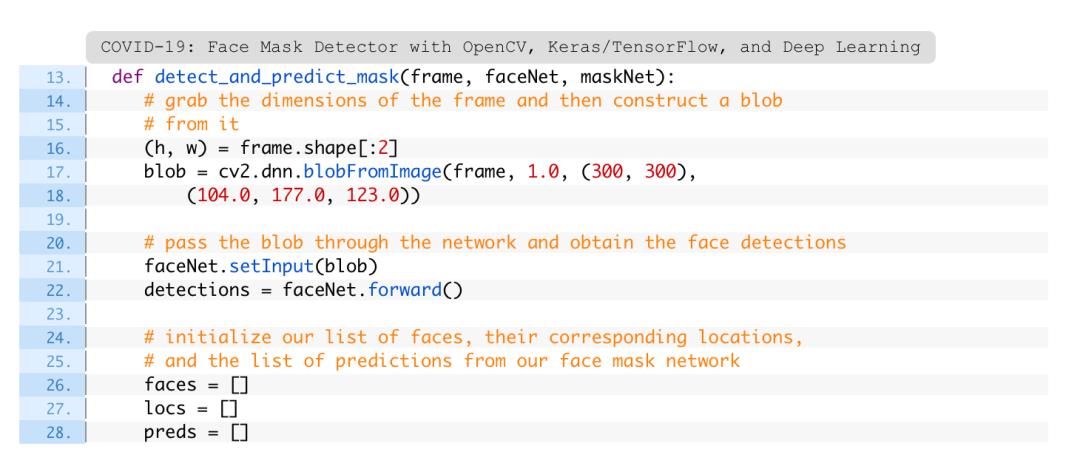
人脸检测/口罩预测逻辑是在detect_and_predict_mask函数:
通过在此处定义此功能,帧处理循环将在以后更易于阅读。
此功能可检测面部,然后将口罩分类器应用于每个面部ROI。这样的功能巩固了代码,它甚至可以移动到单独的Python文件中。
detect_and_predict_mask函数接受三个参数:
在内部,构建一个Blob,检测人脸并初始化列表,其中两个函数设置为返回。这些列表包括面孔(即ROI),位置(面部位置)和preds(口罩/无口罩预测列表)。
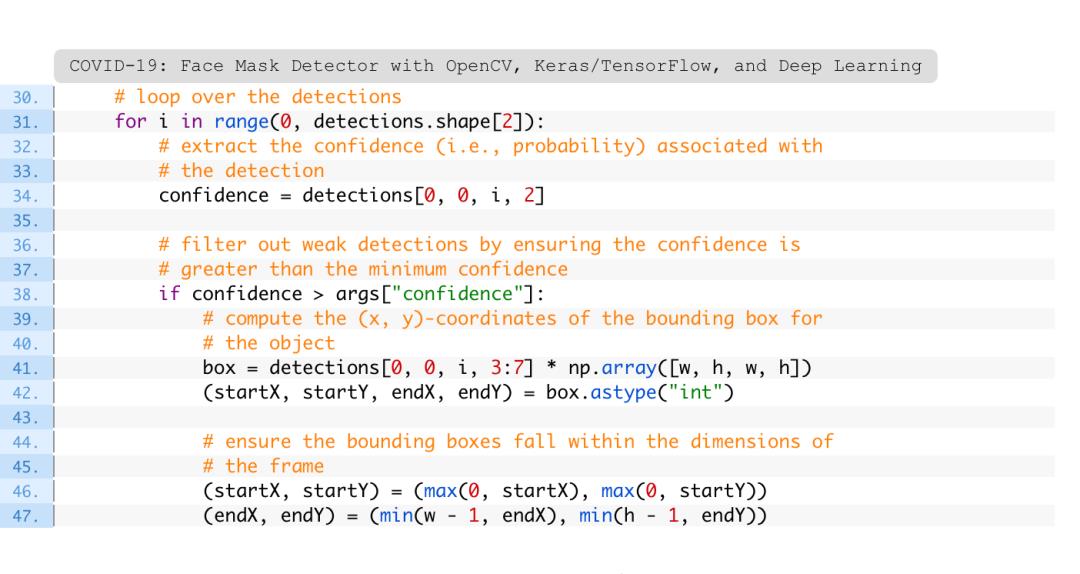
在遍历内部,过滤掉弱检测(第34-38行)并提取边界框,同时确保边界框坐标不会超出图像的边界(第41-47行)。
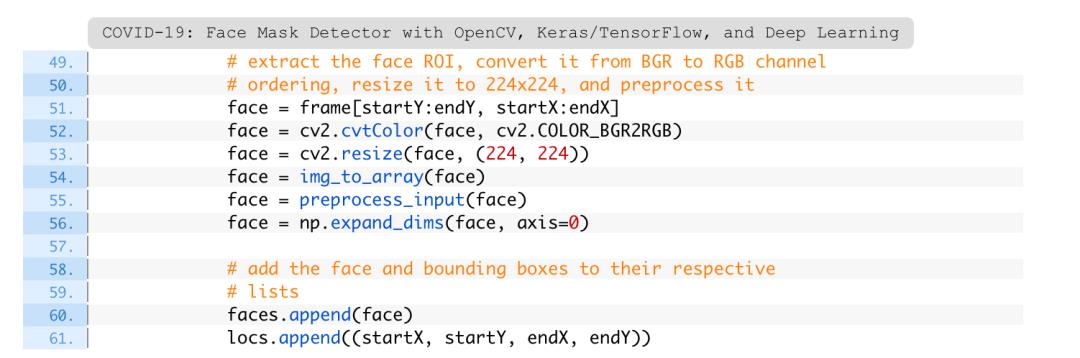
在提取了面部ROI并进行了预处理(第51-56行)之后,将面部ROI和边界框附加到它们各自的列表中。
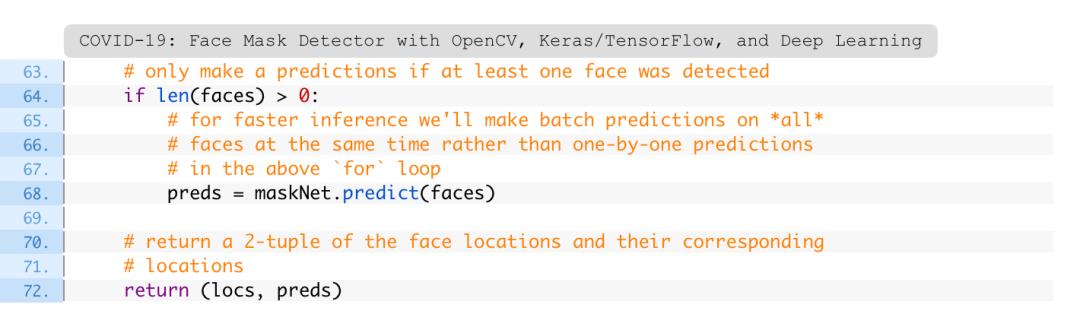
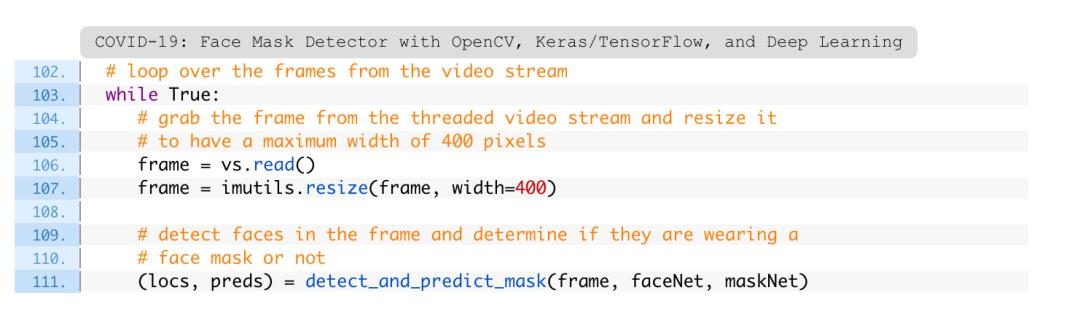
这里的逻辑是为速度而构建的。首先,确保至少检测到一张脸(第64行)——如果没有,将返回空的preds。
其次,要对框架中整个面部进行推理,以使pipeline更快(第68行)。由于内存的原因,编写另一个遍历来分别对每个面孔进行预测是没有意义的。批量执行预测更为有效。
第72行将面部边界框位置和相应的口罩/无口罩预测返回给调用者。
准备好导入,便捷功能和命令行参数后,在循环遍历帧之前,只需要处理一些初始化工作:
从103行开始。在内部,从流中获取一个框架并调整它的大小(第106行和第107行)。
用Python,OpenCV和TensorFlow / Keras进行深度学习来实现实时口罩检测器真是太好了!
要查看运行中的实时口罩检测器,请确保使用本教程的“下载”部分下载源代码和预训练的口罩检测器模型。
然后,可以使用以下命令在实时视频流中启动口罩检测器:
这里,可以看到口罩检测器能够实时运行(并且其预测也是正确的)。
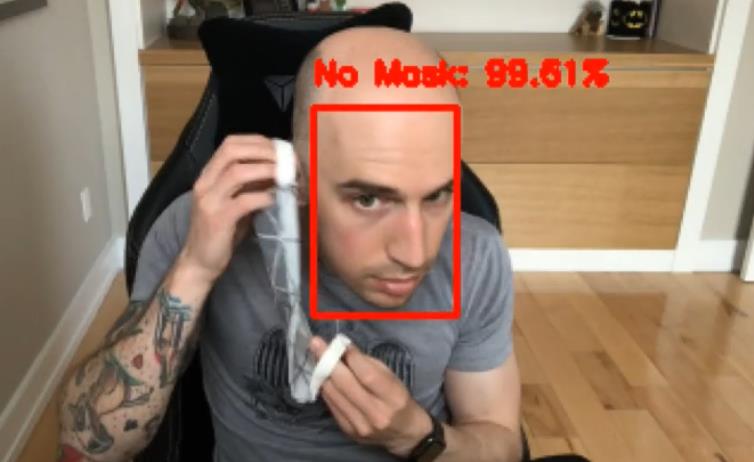
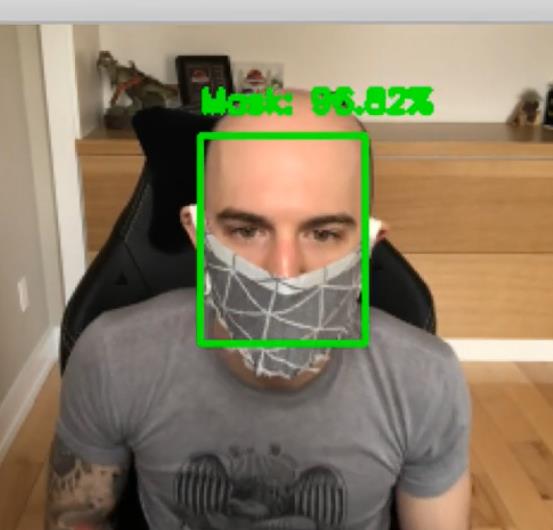
从上面的结果部分可以看到,尽管存在以下情况,口罩检测器仍能很好地工作:
为了进一步改善口罩检测模型,应该收集戴口罩的人的真实图像(而不是人工生成的图像)。
虽然人工数据集在这种情况下效果很好,但无法代替真实的东西。
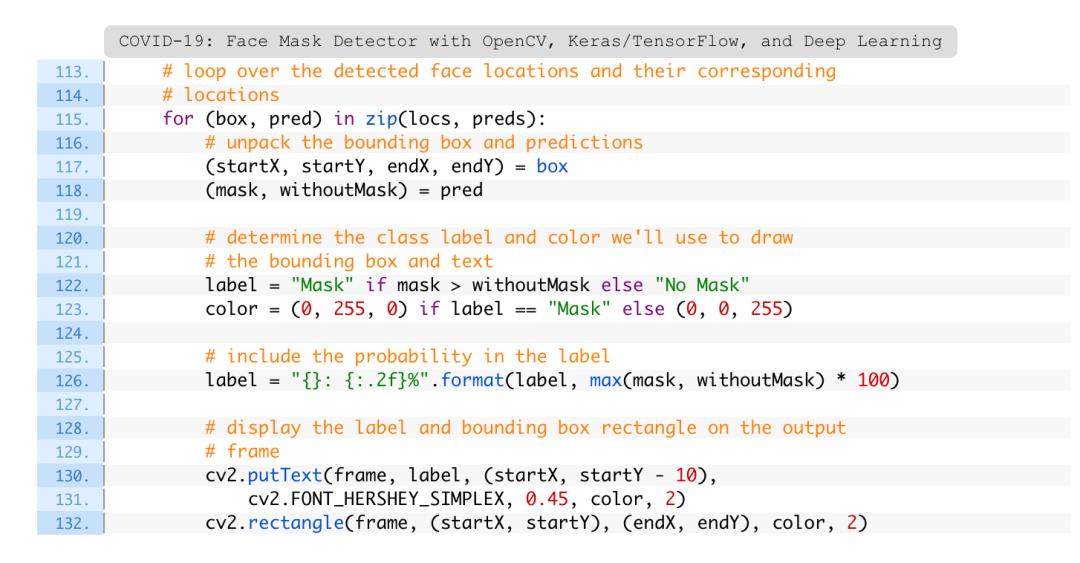
其次,还应该收集可能使分类器“混淆”认为该人实际上戴着面具的人的图像,包括裹在脸上的衬衫,嘴上的头巾等。
所有这些都是口罩检测器可能会将其混淆为口罩的示例。
最后,应该考虑训练专用的两类对象检测器,而不是简单的图像分类器。
这种方法的问题在于,根据定义,口罩会遮盖脸部的一部分。如果遮挡了足够多的脸部,则无法检测到脸部,因此将无法使用口罩检测器。
为了避免该问题,应该训练一个两类对象检测器,该对象检测器由戴口罩类和未戴口罩类组成。
将对象检测器与专用的戴口罩类结合使用将在两个方面改进模型。
首先,物体检测器将能够自然地检测戴着口罩的人,否则由于面部过多被遮盖,检测器将无法检测到这些对象。
其次,这种方法将计算机视觉流程简化为一个步骤-而不是应用面部检测,然后再应用口罩检测器模型,我们要做的就是应用对象检测器为网络中的戴口罩和未戴口罩的人提供边界框。
在本教程中,讲述了如何使用OpenCV、Keras/TensorFlow和Deep Learning创建口罩检测器。
为了创建口罩检测器,训练了两个类:戴口罩的人和不戴口罩的人。
在戴口罩和不戴口罩的数据集上对MobileNetV2进行了微调,并获得了一个精度约为99%的分类器。
口罩检测器是准确的,因为使用了MobileNetV2架构,它的计算效率也很高,使得模型更容易部署到嵌入式系统(Raspberry Pi、谷歌Coral、Jetosn、Nano等)。
https://www.pyimagesearch.com/2020/05/04/covid-19-face-mask-detector-with-opencv-keras-tensorflow-and-deep-learning/
重磅!CVer-OpenCV&TF 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-OpenCV或者TensorFlow 微信交流群,目前已汇集1300人!涵盖语义分割、实例分割和全景分割等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、TensorFlow和PyTorch等群。
一定要备注:研究方向+地点+学校/公司+昵称(如OpenCV+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群
请给CVer一个在看!
以上是关于牛逼!大神用OpenCV/Keras/TensorFlow实现口罩检测的主要内容,如果未能解决你的问题,请参考以下文章
python自学攻略:教你如何从零基础小白飞升牛逼大神
比较牛逼的blog
程序员的四个等级:菜鸟普通大牛大神,你属于哪一个?
Fiddler前端页面调试工具简易入门
牛逼,全球首个开源图像识别系统上线了!
翻译系列-- 2019 国外大神收费XSS 技巧