用 Webhook+Python+Shell 编写一套 Unix 类系统监控工具
Posted GitChat精品课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用 Webhook+Python+Shell 编写一套 Unix 类系统监控工具相关的知识,希望对你有一定的参考价值。
本文来自作者 Alinx 在 GitChat 上分享 「用 Webhook+Python+Shell 编写一套 Unix 类系统监控工具」
前言
告警系统是对系统监控必须掌握的技能、不管是用 zabbix、cacti 等监控平台还是其他的监控工具,都需要有一个实时的监控与反馈机制,能让问题、故障实时的通知到工程师的手里,及时得到解决,以最大化的保障业务的正常。
本次编写部署监控是为了更好的学习、经验的总结、也希望能给给位带来一点帮助,在大家刚好需要的时候,这篇文章能帮助你解决你所需要的。
一、shell 原理认识
1. shell 介绍
Shell(计算机壳层),在计算机科学中,shell 俗称壳,是提供使用者使用界面的软件(命令解析器)。它类似于 DOS 下的 command.com 和后来的 cmd.exe。它接收用户命令,然后调用相应的应用程序。
同时它又是一种程序设计语言。作为命令语言,它交互式解释和执行用户输入的命令,或者自动地解释和执行预先设定好的一连串的命令;
作为程序设计语言,它定义了各种变量和参数,并提供了许多在高级语言中才具有的控制结构,包括循环和分支。
基本上 shell 分两大类:
图形界面 shell(Graphical User Interface shell 即 GUI shell)
命令行式 shell(Command Line Interface shell 即 CLI shell)
2. shell 的类型
在 UNIX 中主要有:
Bourne shell ( sh)
Korn shell ( ksh)
Bourne Again shell ( bash)
POSIX shell ( sh)
C shell (包括 csh and tcsh)
C shell ( csh)
TENEX/TOPS C shell ( tcsh)
……
3. shell 原理
在 Unix 类系统之中,一个可执行的程序是一个机器指令及其数据的序列,一个进程是程序运行时的内存空间和设置。
Unix 系统中的内存分为系统空间和用户空间,进程存在于用户空间,用户空间是存放运行的程序和它们数据的一部分内存空间。
建立一个进程时,内核要找到存放程序指令和数据的空闲内存页。内核还要建立数据结构来存放相应的内存分配情况和进程属性。
shell 是一个管理进程和运行程序的程序,Unix 系统有很多可用的 shell。
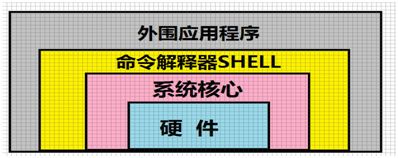
shell 对输入的命令的分析:
在 Linux 中,有一些命令,例如 cd 是包含在 shell 内部的命令,还有一些命令,例如 cp、mv 或 rm 是存在于文件系统中某个目录下的单独的程序。对于用户而言,没必要关心一个命令是在 shell 内部还是在 shell 外部。
shell 对于命令的分析过程如下:
首先,检查用户输入的命令是否是内部命令,如果不是再检查是否是一个应用程序;shell 在搜索路径或者环境变量中寻找这些应用程序;
如果键入命令不是一个内部命令并且没有在搜索路径中查找到可执行文件,那么将会显示一条错误信息;
如果能够成功找到可执行文件,那么该内部命令或者应用程序将会被分解为系统调用传给 Linux 内核,然后内核在完成相应的工作。
二、深入理解 shell
只要有操作系统的地方就有 shell、学习 shell 也可以说是学习它的系统,掌握 shell 也等同于熟练的掌握了系统的使用规则。
Shell、内核、硬件的关系如图所示:
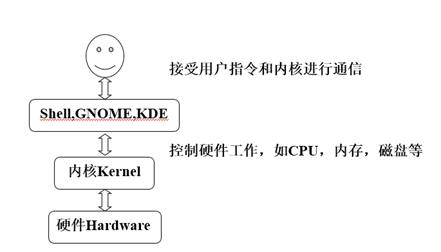
1. 学习 shell 好处
变化小,一旦学会,受用终身
远程控制方面字符界面比 GUI 更节省网络带宽
编程功能可以大大提高系统管理的效率
对 Linux 内部的运行机制有更深入的了解
2. bash 作为管理内核的 Shell,其优点如下:
支持通配符和一些特殊字符
支持输入输出重定向
支持管道操作
命令的记忆与编辑功能
命令的别名设定功能
自动补全功能
强大的编程功能
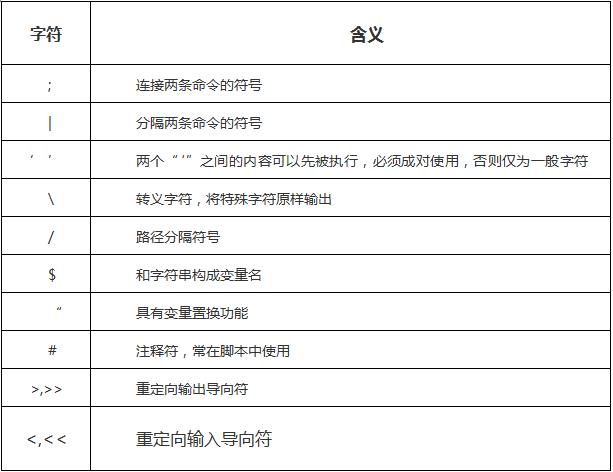
3. Shell 命令的通配符和特殊字符
常用的特殊字符表
利用通配符可以同时引用多个文件,常用的通配符有 * 和 ? ,* 号表示可以匹配任意长度的任何字符,? 号代表了任意一个字符。
例如:
ls *.png ls b? ls b???
注意:
通配符 * 不能与 . 开头的文件名匹配
利用 [ ]、- 和 ! 组成的字符组模式还可以扩展要匹配的文件范围
[ ] 规定在指定的字符范围任意一个字符都满足匹配
- 规定在某一个区间范围内匹配
! 规定在某一范围之外的匹配
例如:
ls [abc]d ls [abc]* ls [a-f]* ls [!abc]*
4. 输入输出重定向
键盘称为标准输入设备,显示器称为标准输出设备
在 Shell 中,不使用系统的标准输入、输出设备而重新指定其输入输出的方法称为输入输出重定向。
什么时候需要使用重定向?
当屏幕输出的信息很重要,而且需要将它保存的时候,后台执行的程序,不希望它干扰屏幕正常输出结果时;
一些系统的例行性命令的执行结果时;
希望它可以保存下来时;
错误信息和正确信息需要分别输出时;
需要输入的数据通过文件的方式读入时。
重定向符号有:>、1>、2>、>>、<
语法格式:
命令重定向符号设备或文件
根据不同的符号实现的效果可以分为:
与输出相关的重定向
输出重定向
附加输出重定向
错误输出重定向
与输入相关的重定向
输入重定向
标准输出重定向(>)
将命令执行的结果不在标准输出设备上显示,而是保存到某一文件或者通过某一设备进行输出的操作
例如:ls -al >list
说明:
如果 list 文件本身不存在,则系统会自动建立它
如果 list 文件已存在,则系统会先将文件内容清空,然后再将数据写入。即将原有数据覆盖掉了。
可以通过 vi test 来浏览执行的结果信息。
附加输出重定向(>>)
和标准输出重定向不同之处在于前者将输出的内容保存到文件的同时不覆盖文件原有的内容,而是追加到原有内容的后面;
例如:ls -al >>list
错误输出重定向(2>)
例如:find / -name newtxt 2> err.txt
说明:该命令将正确的结果信息显示在屏幕上,将错误的信息输出到 err.txt 文件中
错误输出重定向(2>)
将正确的信息和错误的信息分别输出到不同的文件
find / -name newtxt 1>right.txt 2>err.txt
将正确的信息和错误的信息都输出到同一个文件中
find / -name newtxt 1>result.txt 2>&1
将显示的数据中正确的信息输出到某个文件,错误的信息丢弃
find / -name newtxt 1>result.txt 2> /dev/null
说明:/dev/null 可以视为垃圾设备,专么收集垃圾信息,导入到这里的数据将被清理并消除,将多个命令前后连接起来形成一个管道流。
管道命令执行流程图 :
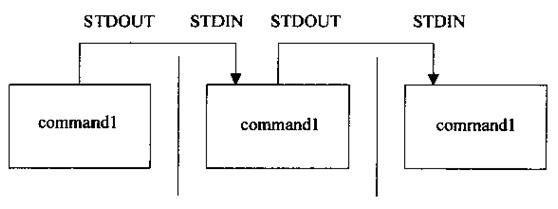
实现管道功能的符号为 |
例如:
要利用管道统计当前目录下所有文件和子目录的数目
ls -l | wc -l
注意:管道操作只能处理前一个命令执行的正确信息,即标准输出的内容,而对错误信息无法处理
三、Python 浅谈
Python 背景:
1. Python 是什么
Python 是一门编程语言,意味着可以用 Python 编写程序,完成一定的功能;
Python 是一种脚本语言,这就是说,Python 程序需要在一个解释器中运行,这个解释器把程序翻译成计算机可执行的二进制代码,Python 的官方解释器叫做 CPython;
2. 安装 Python
所谓安装 Python,实际上主要是安装一个 Python 解释器(CPython,以便使用该解释器执行 Python 程序)和内置类库;除此之外,同时还会安装一个集成开发环境,这个集成开发环境叫做 IDLE。
3. Python 的代码库
Python 的代码库可以分为两类,一类是 Python 内置的代码库,提供了包括网络 / 文件 / GUI / 数据库 / 文本处理等大量的功能,内置代码库在安装 Python 的时候会同时安装;另一类是第三方代码库,在 Python 上有大量的第三方代码库可供使用。
4. 启动 Python
所谓启动 Python,实际上是启动 Python 解释器(CPython),通过在命令行中输入 Python 启动解释器。
Python 解释器有两种模式,一种是交互式模式,在这种模式下,输入的代码在回车后会立即执行,并显示代码执行结果,在命令行中通过输入 Python 进入交互式模式,输入 exit() 退出交互式模式;
另一种是命令行模式,即在命令行中输入 python [文件名. py],直接执行 Python 程序。
这里有一个问题,就是 Python 可以用来编写 web 应用程序,web 应用程序的基本功能是处理 http 请求,Python 程序是如何运行起来(或者说在上面的哪种模式下)处理 http 请求的呢?
这是由 web 服务器和框架来启动 Python 程序处理 http 请求的。所有用脚本语言编写的网站后台都是这种由框架启动的模式。
5. Python 语言的输入和输出
Python 用 variable = input() 函数将用户输入保存在变量 variable 中,用 print(‘hello’, variable) 函数产生输出。
6. Python 程序需要保存为 utf-8 编码
在 notepad++ 的 Encoding 菜单中选择 Encode in UTF-8-BOM。
数据类型/变量/语句/运算符
1. 数据类型、变量
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
在 Python 中,变量就是变量,它没有类型,我们所说的”类型”是变量所指的内存中对象的类型。
等号(=)用来给变量赋值。
等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。例如:
#!/usr/bin/python3 counter = 100 # 整型变量 miles = 1000.0 # 浮点型变量 name = "runoob" # 字符串 print (counter) print (miles) print (name)
标准数据类型
Python3 中有六个标准的数据类型:
Number(数字)
String(字符串)
List(列表)
Tuple(元组)
Sets(集合)
Dictionary(字典)
Python3 的六个标准数据类型中:
不可变数据(四个):Number(数字)、String(字符串)、Tuple(元组)、Sets(集合);
可变数据(两个):List(列表)、Dictionary(字典)。
2. 语句
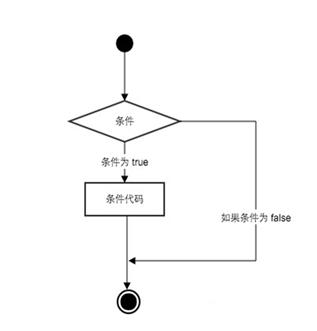
Python 条件语句:
Python 条件语句是通过一条或多条语句的执行结果(True 或者 False)来决定执行的代码块。
可以通过下图来简单了解条件语句的执行过程:
if 判断条件: 执行语句…… else: 执行语句……
Python 循环语句
本节将向大家介绍 Python 的循环语句,程序在一般情况下是按顺序执行的。
编程语言提供了各种控制结构,允许更复杂的执行路径。
循环语句允许我们执行一个语句或语句组多次,下面是在大多数编程语言中的循环语句的一般形式:
循环控制语句
循环控制语句可以更改语句执行的顺序。Python支持以下循环控制语句:

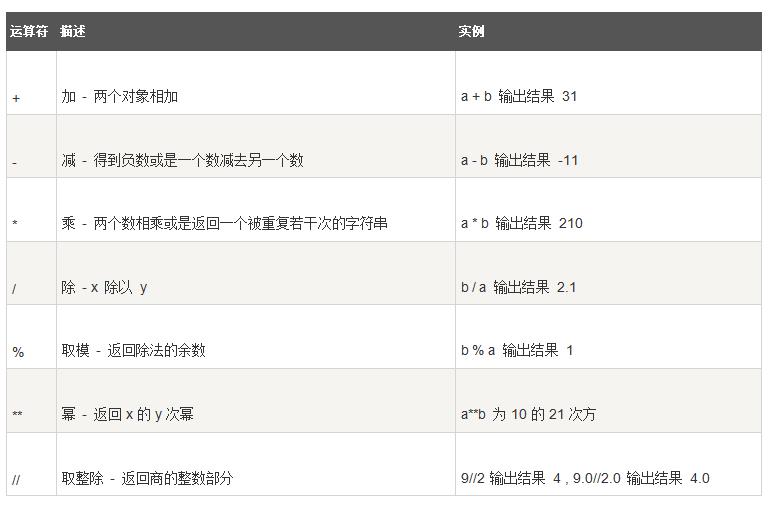
3. 常见运算符
函数
函数的定义:def 函数名( 逗号分隔的参数列表 ): 函数体
函数名:
参数列表:参数无数据类型,用逗号分隔。
返回值:在函数定义中,并不能定义返回值。但在函数体内部用 return 语句结束函数执行,return 语句可带有(多个)返回值,如果没有明确指定返回值,则函数的返回值为 None,有多个返回值的,实际上是返回一个 tuple。
调用函数:
在命令行模式下调用函数:
在交互式模式下调用函数:
再谈函数参数:
位置参数:就是常见的参数形式,没有特别的;
默认参数:
就是参数有一个默认值,在调用函数时,如果没有为有默认值的参数指定值,则该参数使用此默认值,如:函数 power( x, n = 2 ),n 即为有默认值的参数;
如果有多个有默认值的参数,那么调用此函数的时候,要么全部省略实际参数,要么依顺序提供实际参数,如果需要省略位于较前位置的实际参数值,那么为较后位置的参数提供实际参数时,要使用命名参数的形式,即“参数名 = 值”的形式;
默认参数的“坑”:
可变参数:是说函数参数的个数是不固定、可变的。定义可变参数的语法是在参数名前添加一个,如:def calc( numbers );实际上可变参数和类型为 tuple 的参数,效果是一样的,只是可变参数使得代码更简洁一些(可以认为是个语法糖),在调用函数的时候可以提供任意个参数;
关键字参数:也是函数参数的个数不规定、可变的,只是在调用函数时使用“参数名 = 值”的方式提供多个参数,这些“参数名 = 值”在函数内部将作为形式参数的元素加入到形式参数中(这个形式参数将转变为 dict),定义关键字参数的语法是在形式参数名前添加两个,如:`def calc( *numbers )`。
命名关键字参数:
在 Python 中,调用函数的时候,不能传入未经定义的实参(这一点和 javascript 不一样,后者可以传入任意多的实参,如果在函数定义中无对应的形参,则多余参数将被忽略);
高级特性
切片(slice):切片是指获取 list 或 tuple 的一部分(或一个子集),不能对 dict 或 set 进行切片操作(因为其中的元素不是按顺序存储的)。
切片的语法是:list[n1:n2:n3],其中 n1 为切片的起始索引,如果省略则为从 0 开始;n2 为结束索引,若省略则为最后一个;n3 则表示在起始索引和结束索引的范围内每 n3 个取一个元素,若省略,则每个元素都取。这个切片就像字符串的 substring 方法一样。
可迭代对象及迭代:迭代就是使用 for 循环依次访问可迭代对象中的每个元素。
什么是可迭代对象?
如何迭代 list/dict/tuple/set/ 字符串
Python 的 for 循环非常特别,在for循环中可以引用多个变量,形如:for i, j, k in …,这是要求 in 后的可迭代对象中也要有分别对应 i,j,k 多个变量的内容。
列表生成式 list Comprehensions:专门用来生成一个(复杂的)list 的机制。语法为:[ 对 for 中变量进行计算的表达式 for 变量列表 in 可迭代对象 if 对 for 中变量筛选的表达式],如:[ k + ‘ = ‘ + v for k, v in dict.items() if v % 2 == 0],这个语法真是足够灵活。
生成器 generator:生成器可以认为是表示生成一个 list 的算法(而不像列表生成式那样直接生成了一个列表),list 中的元素在需要时(比如访问这个元素时)才会生成(不需要时不生成,减少了内存占用,可表示无限集)。
创建生成器:方法一:把列表生成式语法中的 [] 替换为 (),即创建了一个生成器;方法二:使用函数来创建生成器,但是用来创建生成器的函数,除了其中要有 yield 语句外,还是与一般的函数不同。不同之处在于在这个函数中,yield 还需要放在一个循环语句中,这样,这个生成器才能生成多个列表元素。
访问生成器 generator 中的元素:因为 generator 也是可迭代对象,所以可以使用 for 来访问 generator 中的元素: for n in g: print(n)
函数式编程
所谓函数式编程,就是语言中的“函数”也是数据,可以被赋值给变量、作为另一个函数的参数等,总之是在使用数据的场合都可以使用“函数”。
高阶函数:就是可以将其他函数作为参数的函数。Python 内置的几个高阶函数有(这些高阶函数和C#中在集合上定义的扩展方法非常类似,它们的参数都是一个函数和一个可迭代对象,然后将函数作用于可迭代对象中的每个元素,产生结果):
map(f, list):传入 map 的函数仅有一个参数,将此函数单独作用在可迭代对象的每个元素上(也就是依次用可迭代对象中的每个元素作为此函数的参数调用,需要注意的是,在函数中没有有关此元素在list中的位置信息,所以如果遇到需在函数中使用元素的位置信息的时候,不要使用高阶函数),其返回值是一个迭代器(可以转变为list而不直接返回list);
reduce(f, list):传入 reduce 的函数有两个参数,达到的效果是:reduce(f, [x1, x2, x3, x4]) = f( f( f( x1, x2 ), x3 ), x4 ),reduce的返回结果,是函数的计算结果,而不再是一个迭代器或list;
filter():传入 filter 的函数仅有一个参数,此函数依次作用于可迭代对象的每个元素时返回一个 bool 结果。整个 filter 的运算结果是一个迭代器,但排除了上面运算结果为 false 的元素;
sorted():
函数作为返回值和闭包:大概了解是怎么回事,但是还是有些说不清楚,也很难应用起来。
匿名函数(在 python 中就是 lambda 表达式):语法是:lambda 逗号分隔的参数列表:表达式。匿名函数的返回值就是 lambda 表达式的值。python 中,这里的“表达式”只是一个简单的表达式,不支持复杂的语句块;
装饰器:类似于 OOP 中的装饰器模式,Python 直接从语言层面上支持此模式。Python 中的装饰器可以为一个函数临时增加一些功能。Python 是通过下面的步骤实现此模式的:
定义一个参数为函数、返回值也是函数的函数,即装饰器函数,在返回的函数中调用传入的参数函数及添加其他功能,也就是返回的函数成为了参数函数的一个包装器;
在定义需要临时增加一些功能的函数时,在函数前使用“@装饰器函数名”语法修饰该函数,则在调用此函数时,会转为调用在装饰器函数中定义的包装函数,从而达到临时增加功能的目的;
实际上包装器函数和原函数的一些属性还是不同的,如name属性等,但 python 通过 functools 模块中的wraps函数可以将原函数的属性复制给包装器函数,所以在装饰器函数中要求这么一句@functools.wrap(原函数名);
总结起来,装饰器函数有这么几个特征:
(1)其参数为一个函数;
(2)返回值也是一个函数;
(3)在返回值函数中调用参数函数并添加其他功能,达到为参数函数临时增加功能的目的;
(4)通过“@装饰器函数名”的方式修饰其他函数,从而为该函数增加装饰器中增加的临时功能;
(5)装饰器函数中要有这样一个语句:@functools.wrap(原函数名),用于将原函数属性复制给包装器函数;这也太笨拙了吧?
偏函数:就是通过为一个函数中的某些参数指定默认值,从而形成一个新函数,这个新函数成为原函数的偏函数。python是通过functools模块中的partial方法做到这一点的,这个作用不太大,等到用到的时候在详细查看其语法吧。
模块
模块是 Python 中组织源代码的一种机制,一个 .py 文件就是一个模块,模块名是该 .py 文件所在的文件夹名与文件的组合,用 . 分隔,即“文件夹名 . 文件名”;
用文件夹来组织模块的方式,称为“包(Package)”。可以作为包的文件夹中必须包含一个 __init__.py 文件(这个 __init__.py 文件本身可以为空,也可以包含代码,它本身也是一个模块,但它的模块名不是 __init__,而是它所在文件夹的名称),否则该文件夹只是一个普通的文件夹而非“包”(“包”类似 C# 中命名空间的机制)。
使用内置模块
只要安装了 Python,内置模块就可以使用。使用模块的第一步是导入模块,语法为 import 模块名,如:
import sys
导入模块后,将相当于定义了一个与模块同名的变量 sys,使用该变量来引用该模块,如 sys.argv,就是引用模块 sys 中定义的变量 argv。
使用第三方模块
使用第三方模块之前,需要首先进行安装。在 Python 中,是通过包管理工具 pip 完成第三方模块管理的。
pip命令:
pip search param pip install param pip uninstall param pip list 等
面向对象编程
面向对象编程的内容:类、对象、类和对象的成员、封装、继承、多态;类及其成员的可访问性 public/private/protected;构造函数
class Student(object): def __init__(self, name, score): self.name = name self.score = score
创建类的实例:
student = Student()
定义类的语法:class 类名( 基类 ):,object 是所有类的基类,如果上面的定义中省略了基类,则默认从 object 继承,如:class Student( object ):;
构造函数及创建对象:如果定义类时,未显式定义类的构造函数,则类默认拥有一个无参数的构造函数,如果显示定义了构造函数,则此默认构造函数就不再存在。类的构造函数名必须是__init__。创建对象时,传入的参数必须与类的构造函数的参数匹配(self 参数除外);
类和对象的属性:
类属性:
可以为类动态添加属性,如:Student.score = 90,这样的属性相当于C#的静态成员,为类动态添加的属性会立即体现在类的对象中;
以__开头的属性是 private,不能直接访问(这不是约定,而是 Python 的限制),如果需要访问,则需要定义对应的 get/set 方法;
类似__xxx__的属性都是类的特殊变量,但不是 private 的;
对象属性:
可以为对象动态添加属性,如 student1.score = 80;如果对象的属性与类的属性重名,则对象的属性覆盖类的属性;这个可能和 javascript 的属性访问机制一样,即从底层开始,找到后即不在继续向上层查找;
类的方法:(1)与普通函数的区别在于,类的方法,其第一个参数永远是 self (语法是:def methodname(self)),但在调用时不必传入该参数;(2)也可以为类动态添加方法,先定义一个第一个参数是 self 的方法,动态添加方法的语法是:类名.方法名 = MethodType( 方法名, 类名 )
继承和多态:继承和多态总体上来讲和 C# 一样,区别在于:python 中在子类中定义的与父类同名的方法,自动全部是多态的(以__开头的方法除外,C#有覆盖和复写的区别,python 没有?),python 中有无类似 abstract 机制?python 中有没有 protected/protected internal 的机制?
获取对象信息,使用以下函数:
type():用来判断对象的类型。python 的设计不严谨,这个 type() 函数就是个很好的例子。type() 函数返回值的类型是什么呢?是类。那是什么类呢?他可以和 int/str/bool/bytes(对于基本数据类型)、类名(对于一般类)、types 模块中定义的常量(如:FunctionType等)比较。是不是太灵活了?
isinstance():判断某个变量是否为某种或某几种类型,返回值为 True 或者 False;
dir():获取一个对象所有的属性和方法,返回值是一个包含对象所有属性和方法名的 list;
hasattr()/getattr()/setattr():用于判断一个属性/方法名(字符串表示)是否为一个对象的属性/方法。
四、Webhook
1. 概述
Webhook 是一个 API 概念,并且变得越来越流行。我们能用事件描述的事物越多,Webhook 的作用范围也就越大。Webhook 作为一个轻量的事件处理应用,正变得越来越有用。
准确的说 Webhook 是一种 web 回调或者 http 的 push API,是向 APP 或者其他应用提供实时信息的一种方式。
Webhook 在数据产生时立即发送数据,也就是你能实时收到数据。这一种不同于典型的 API,需要用了实时性需要足够快的轮询。
这无论是对生产还是对消费者都是高效的,唯一的缺点是初始建立困难。Webhook 有时也被称为反向 API,因为他提供了 API 规则,你需要设计要使用的 API。
Webhook 将向你的应用发起 http 请求,典型的是 post 请求,应用程序由请求驱动。
2. 使用 Webhook
消费一个 Webhook 是为 Webhook 准备一个 URL,用于 Webhook 发送请求。这些通常由后台页面和或者 API 完成。这就意味你的应用要设置一个通过公网可以访问的 URL。
多数 Webhook 以两种数据格式发布数据:JSON 或者 XML。另一种数据格式是 application/x-www-form-urlencoded or multipart/form-data。这两种方式都很容易解析,并且多数的 Web 应用架构都可以做这部分工作。
3. Webhook 调试
调试 Webhook 有时很复杂,因为 Webhook 原则来说是异步的。你首先要触发它,然后等待,接着检查是否有响应,枯燥并且相当低效。幸运的是还有其他方法:
明白 webhook 能提供什么,使用如 RequestBin 之类的工具收集 webhook 的请求;
用 cURL 或者 Postman 来模拟请求;
用 ngrok 这样的工具测试你的代码;
用 Runscope 工具来查看整个流程。
4. Webhook 安全
因为 Webhook 发送数据到应用上公开的 URL,这就给其他人找到这个 URL 并且发送错误数据的机会。你可采用技术手段,防止这样的事情发生。最简单的方法是采用 https(TLS connection)。除了使用 https 外,还可以采用以下的方法进一步提高安全性:
首先增加 Token,这个大多数 Webhook 都支持;
增加认证;
数据签名。
5. 重要的问题
当作为 Webhook 的消费者时有两件事需要铭记于心:
Webhook 通过请求发送数据到你的应用后,就不再关注这些数据。也就是说如果你的应用存在问题,数据会丢失。许多 Webhook 会处理回应,如果程序出现错误会重传数据。如果你的应用处理这个请求并且依然返回一个错误,你的应用就会收到重复数据。
Webhook 会发出大量的请求,这样会造成你的应用阻塞。确保你的应用能处理这些请求。
五、Python 脚本
1. 添加钉钉的机器人并编写告警脚本
使用 Python 来编写 Python 告警脚本,结合 Webhook 技术:
钉钉内部申请机器人:
(1)新建群聊
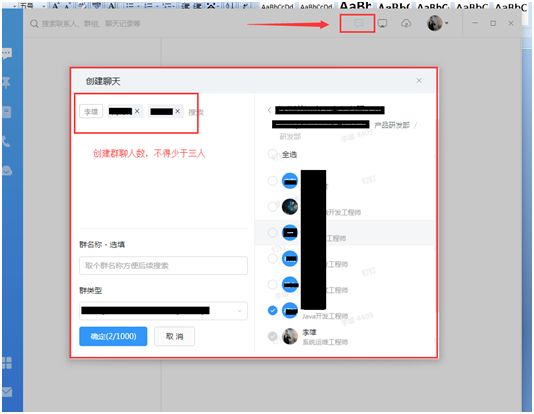
(2)创建群机器人
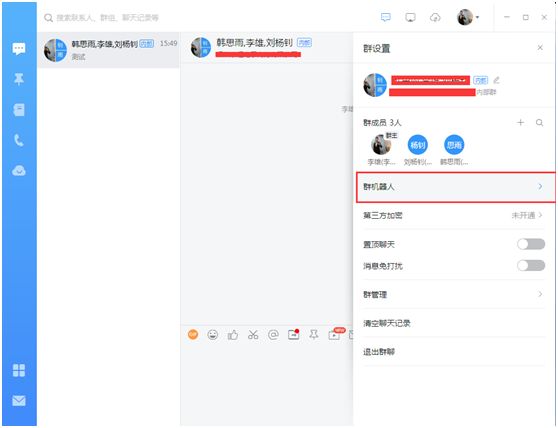
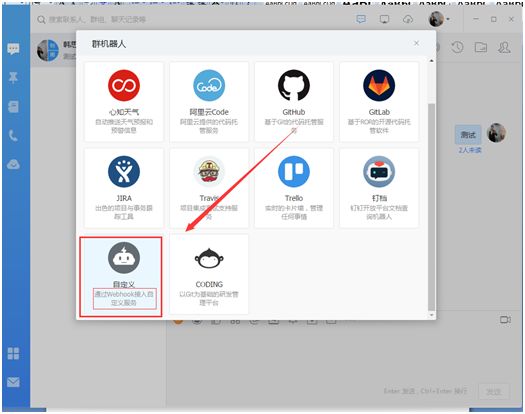
(3)选择通过 Webhook 接入的自定义服务
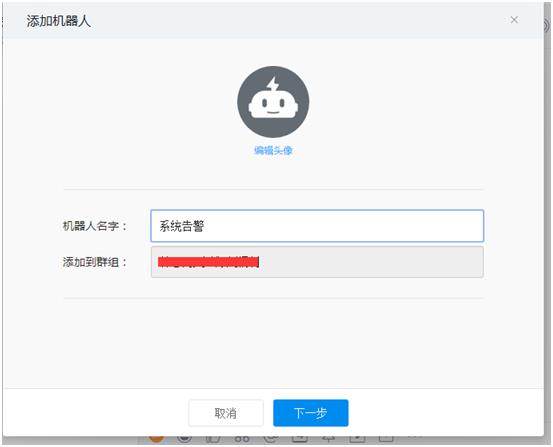
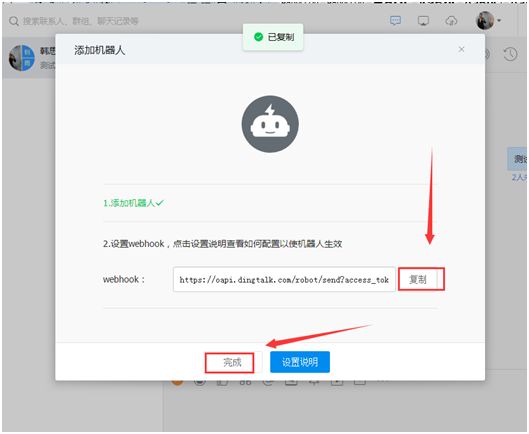
https://oapi.dingtalk.com/robot/send?access_token=713f8d422336b8131a4829fa752293f2dd9c963c8d185e31a1a1799cfc5ffa35
告警脚本:
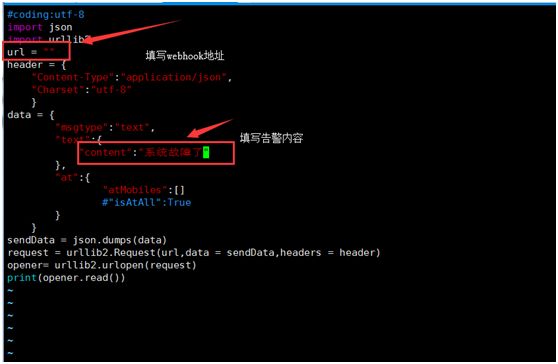
代码如下:
import json import urllib2 url = "" header = { "Content-Type":"application/json", "Charset":"utf-8" } data = { "msgtype":"text", "text":{ "content":"系统故障了" }, "at":{ "atMobiles":[] #"isAtAll":True } } sendData = json.dumps(data) request = urllib2.Request(url,data = sendData,headers = header) opener= urllib2.urlopen(request) print(opener.read())
六、编写 Shell 监控监本
我们这里结合 Python 的高级脚本来调用 Shell 脚本来给服务器的服务做好监控服务,并输出信息。
1. 编写线上监控 shell 脚本
监控程序正常与否(服务状态、使用状态、连接状态、安全……)
例子:
现在我们编写一个监控 Java 程序的脚本,并且让它能自启动。
思路:
监控程序(状态)>>> 程序正常 >>> 结束 ; ↓ 程序异常(自启动/修复)>>> 程序正常 >>> 结束; ↓ 程序异常发送告警(需要手动处理);
告警我们使用 Python 来回调 Webhook 的参数发送到钉钉的群消息当中。
监控脚本 1:
Apache 监控脚本:
vim check_apache.sh #!/bin/bash app=httpd ps aux|grep -v grep | grep httpd > /opt/jar/sys.log && grep "$app" /opt/jar/sys.l if [ $? -eq 0 ];then echo "[ `date -d today +"%Y-%m-%d %H:%M:%S"` ]- [app $app is runing!]" >> /opt/jar/app.log else echo "[ `date -d today +"%Y-%m-%d %H:%M:%S"` ]- [app $app is error!]" >> /opt/jar/app.log python /jenkins/python/sys1.py systemctl start httpd & `sleep 5` if [ $? -eq 0 ];then python /jenkins/python/sys.py echo "[ `date -d today +"%Y-%m-%d %H:%M:%S"` ]- [app $app is runing!]" >> /opt/jar/app.log else echo "[ `date -d today +"%Y-%m-%d %H:%M:%S"` ]- [app $app is error!]" >> /opt/jar/app.log fi
将写好的脚本放到我们的计划任务当中,让它每分钟去执行这监控脚本;
计划任务:
crontab –e * * * * * /bin/sh /jenkins/app.sh &>/dev/null
杀掉程序后,将会自动重启程序,并发送重启状态告警通知!
或者因为其他的原因【程序故障(攻击、bug、模块编译失败、)、服务器、数据库、接口异常、网络问题…… 】发送的告警通知!
七、结合钉钉的 Webhook 实现自动告警
结合 webhook/shell 脚本,基于第五章的 Python 脚本优化,去调用 shell 监控脚本,并发送 shell 程序的返回信息到钉钉告警。
脚本如下:
编写好 shell 脚本后对接到 Python 脚本:
vim check.sh #!/bin/bash #检测服务器所有服务状态,使用函数来涵盖 serverOne(){ echo "检测中..." #mysql netstat -ntlp | grep "3306" &> /dev/null if [ $? -eq 0 ];then echo "Mysql 服务正常" else echo "Mysql 服务异常" fi #fastdfs ps aux| grep -v grep |grep "/usr/local/bin/fdfs_trackerd /etc/fdfs/tracker.conf" &>/dev/null && ps aux| grep -v grep | grep "/usr/bin/fdfs_storaged /etc/fdfs/storage.conf start" &>/dev/null if [ $? -eq 0 ];then echo "FastDFS 服务正常" else echo "FastDFS 服务异常" fi #Redis ps aux | grep -v grep | grep "0.0.0.0:65379" &>/dev/null if [ $? -eq 0 ];then echo "Redis 服务正常" else echo "Redis 服务异常" fi
结果为:

可以结合告警来监控所有的程序。
八、总结
从认识 shell、认识 python、认识 webhook、编写 shell 脚本、编写 python 程序、使用 webhook 的这一系列的学习都需要一个的过程,且众所周知学习是循序渐进的,如果有那个章节不清楚的,请大家加群一起来讨论发问。但是对于本章就算没有扎实的基础也可以写出一套强大的监控系统。
我曾经会非常急促的去学过很多东西,去追逐过很人,到头来,结果都显而易见,完成度非常低,效率非常低,回应都不是肯定的。
如果你喜欢 IT 技术,或者你需要它来支撑某些东西,那么请继续前进,或许唯有这样我们才能走的更远。送给正努力进步的我们!
九、常见服务脚本思路
常见服务监控脚本
在编写脚本之前,我们首先要知道的就是脚本存在的意义,为什么要编写脚本,否则那将毫无意义!
监控脚本编写思路:
现在我们监控 MySQL 服务:MySQL 是关系型数据库,在性能、安全性、运行状态、使我们关注的关键,如果可以在这些关键做好监控 这样不就可以对数据库有一个比较全面的管理控制监控;
同理其他服务也可以针对他的应用场景去编写针对性的脚本来做好监控。
十、常见问题总结
问题1:思路很重要
就算不知道程序本身代码实现的所有的代码表达的意思,但是需要知道的就是代码实现的思路,这样的对整个监控的理解将会有不一样的感觉。
不管是 Python 脚本还是 Shell 脚本都是可以实现我们的功能,但是本章节使用的是 Shell+Python 的形式去实现的。
那么问题来了,为什么不用一个语言去实现呢, 而是用两个结合起来使用,对于 Linux 系统而言,Shell 本身的还是非常优秀的,是 Python 无可替代的。
问题2:有思路后编写与实现
当具备了思路,如何去编写和实现就是一个很有趣的问题了,你可以用你熟悉的任何语言来编写你的脚本(本文推荐用shell+python)最佳。
问题3:Webhook 地址对接后无法收到告警信息
问题4:Shell 脚本对接 Python 脚本,导入的模块等问题
就算不知道如何编写或者调用,都是没有关系,在文中的脚本是现成的直接复制过去使用即可。
以上是关于用 Webhook+Python+Shell 编写一套 Unix 类系统监控工具的主要内容,如果未能解决你的问题,请参考以下文章
python 用Python编写的简单shell脚本来创建sbt目录结构。