用Linux内核的瑞士军刀-eBPF实现socket转发offload
Posted Linux阅码场
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Linux内核的瑞士军刀-eBPF实现socket转发offload相关的知识,希望对你有一定的参考价值。
我们已经对eBPF将网络转发offload到XDP(eXpress Data Path)耳熟能详,作为Linux内核的一把 “瑞士军刀” ,eBPF能做的事情可不止一件,它是一个多面手。
继之后,我们来看看如何基于eBPF实现socket转发的offload。
socket数据offload问题
通过代理服务器在两个TCP接连之间转发数据是一个非常常见的需求,特别是在CDN的场景下,然而这个代理服务器也是整条路径中的瓶颈之所在,代理服务器的七层转发行为极大地消耗着单机性能,所以,通过代理服务器的七层转发的优化,是一件必须要做的事。
所以,问题来了, eBPF能不能将代理程序的数据转发offload到内核呢? 如果可以做到,这就意味着这个offload可以达到和XDP offload相近的功效:
减少上下文切换,缩短转发逻辑路径,释放host CPU。
这个问题之所以很重要亟待解决,是因为现在的很多机制都不完美:
传统的read/write方式需要两次系统调用和两次数据拷贝。
稍微新些的sendfile方式不支持socket到socket的转发,且仍需要在唤醒的进程上下文中进行系统调用。
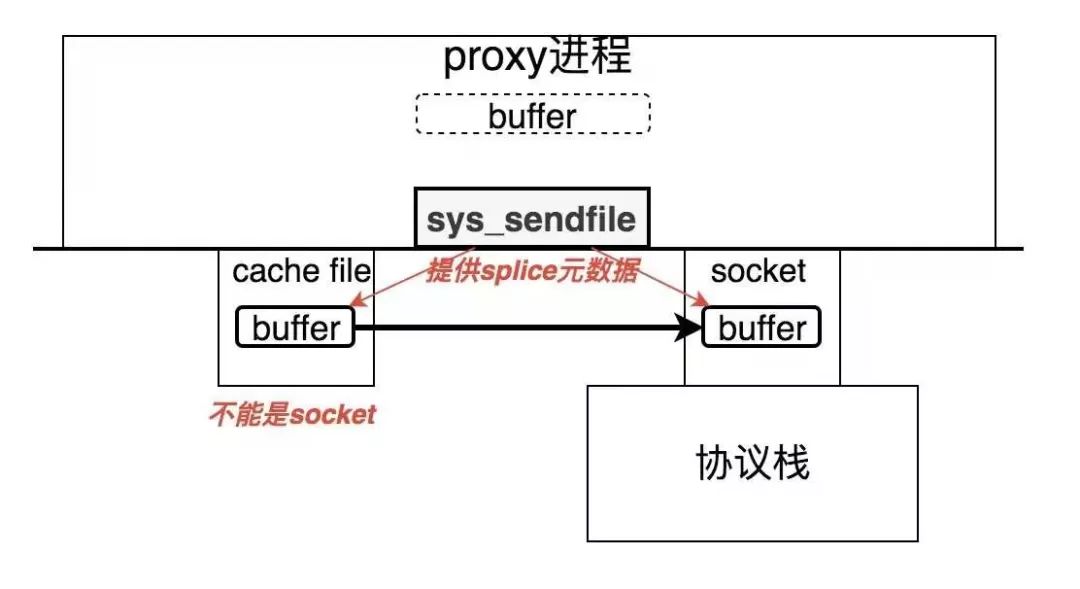
DPDK以及各种分散/聚集IO,零拷贝技术需要对应用进行比较大的重构,太复杂。
...
sockmap的引入
Linux 4.14内核带来了sockmap,详见下面的
lwn:BPF: sockmap and sk redirect support: https://lwn.net/Articles/731133/
还有下面的blog也很不错:
https://blog.cloudflare.com/sockmap-tcp-splicing-of-the-future/
又是eBPF!这意味着用sockmap做redirect注定简单,小巧!
我们先看下sockmap相对于上述的转发机制有什么不同,下面是个原理图: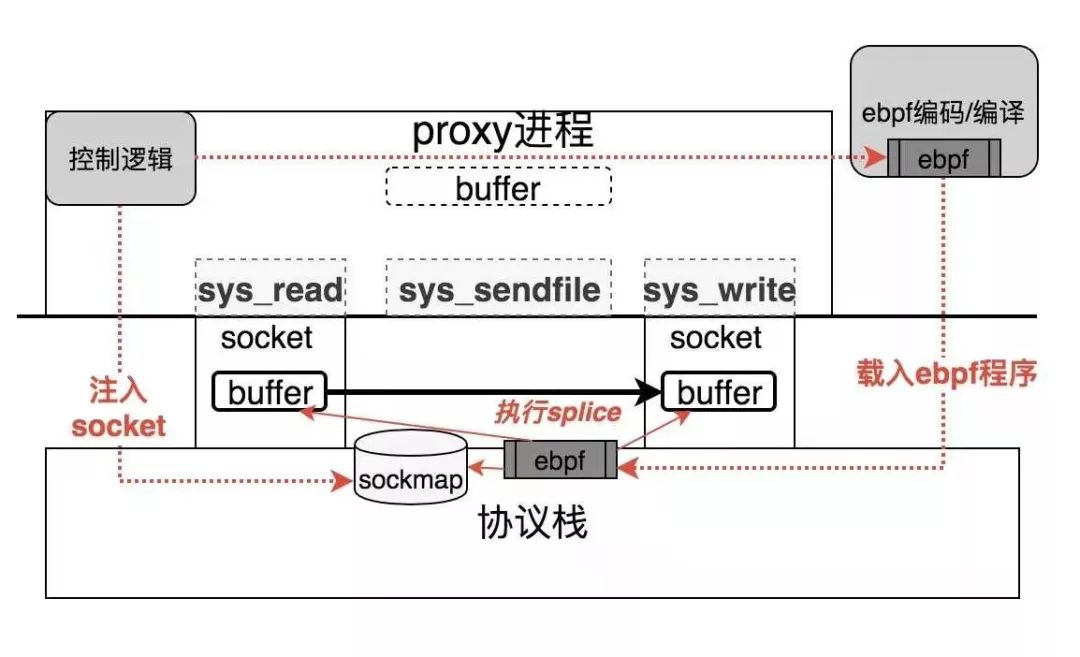
sockmap的实现非常简单,它通过替换skdataready回调函数的方式接管整个数据面的转发逻辑处理。
按照常规,skdataready是内核协议栈和进程上下文的socket之间的数据通道接口,它将数据从内核协议栈交接给了持有socket的进程: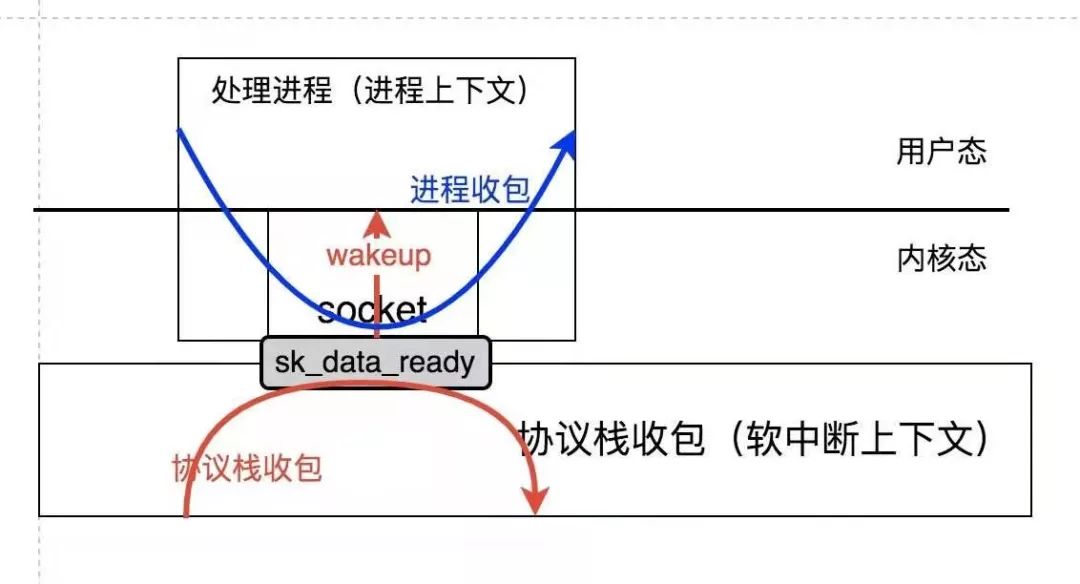
常规处理的skdataready回调函数的控制权转移是通过一次wakeup操作来完成的,这意味着一次上下文的切换。
而sockmap的处理与此不同,sockmap通过一种称为 Stream Parser 的机制,将数据包的控制权转移到eBPF处理程序,而eBPF程序可以实现数据流的Redirect,这就实现了socket数据之间的offload短路处理: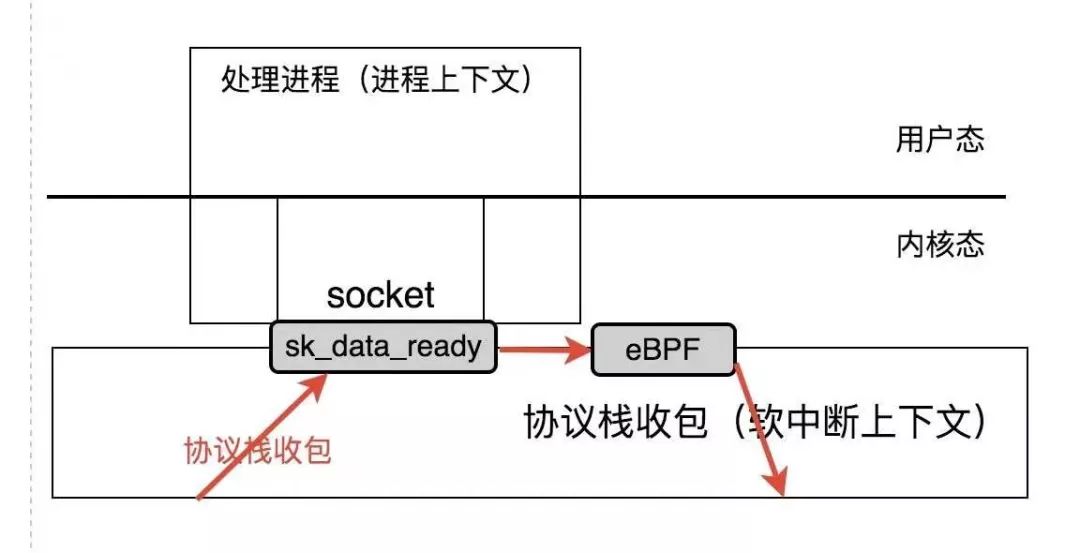
关于 Stream Parser ,详情参见其内核文档:https://www.kernel.org/doc/Documentation/networking/strparser.txt
实例演示
任何机制能实际run起来才是一个真正的起点,现在又到了实例演示的环节。
我们先从一个简单proxy程序开始,然后我们为它注入基于eBPF的sockmap逻辑,实现proxy的offload转发,从而理解整个过程。
我们的proxy程序非常简单,你可以将它理解成一个socket Bridge,它从一个连接接收数据并简单地将该数据转发到另一个连接,稍微修改一下即可实现socket Hub/Switch以及Service mesh。
socket Bridge代码如下:
// proxy.c
// gcc proxy.c -o proxy
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/select.h>
#include <netdb.h>
#include <signal.h>
#define MAXSIZE 100
char buf[MAXSIZE];
int proxysd1, proxysd2;
static void int_handler(int a)
{
close(proxysd1);
close(proxysd2);
exit(0);
}
int main(int argc, char *argv[])
{
int ret;
struct sockaddr_in proxyaddr1, proxyaddr2;
struct hostent *proxy1, *proxy2;
unsigned short port1, port2;
fd_set rset;
int maxfd = 10, n;
if (argc != 5) {
exit(1);
}
signal(SIGINT, int_handler);
FD_ZERO(&rset);
proxysd1 = socket(AF_INET, SOCK_STREAM, 0);
proxysd2 = socket(AF_INET, SOCK_STREAM, 0);
proxy1 = gethostbyname(argv[1]);
port1 = atoi(argv[2]);
proxy2 = gethostbyname(argv[3]);
port2 = atoi(argv[4]);
bzero(&proxyaddr1, sizeof(struct sockaddr_in));
proxyaddr1.sin_family = AF_INET;
proxyaddr1.sin_port = htons(port1);
proxyaddr1.sin_addr = *((struct in_addr *)proxy1->h_addr);
bzero(&proxyaddr2, sizeof(struct sockaddr_in));
proxyaddr2.sin_family = AF_INET;
proxyaddr2.sin_port = htons(port2);
proxyaddr2.sin_addr = *((struct in_addr *)proxy2->h_addr);
connect(proxysd1, (struct sockaddr *)&proxyaddr1, sizeof(struct sockaddr));
connect(proxysd2, (struct sockaddr *)&proxyaddr2, sizeof(struct sockaddr));
while (1) {
FD_SET(proxysd1, &rset);
FD_SET(proxysd2, &rset);
select(maxfd, &rset, NULL, NULL, NULL);
memset(buf, 0, MAXSIZE);
if (FD_ISSET(proxysd1, &rset)) {
ret = recv(proxysd1, buf, MAXSIZE, 0);
printf("%d --> %d proxy string:%s\n", proxysd1, proxysd2, buf);
send(proxysd2, buf, ret, 0);
}
if (FD_ISSET(proxysd2, &rset)) {
ret = recv(proxysd2, buf, MAXSIZE, 0);
printf("%d --> %d proxy string:%s\n", proxysd2, proxysd1, buf);
send(proxysd1, buf, ret, 0);
}
}
return 0;
}
我们来看一下它的工作过程。
首先起两个netcat,分别侦听两个不同的端口,然后运行proxy程序。在netcat终端敲入字符,就可以看到它被代理到另一个netcat终端的过程了: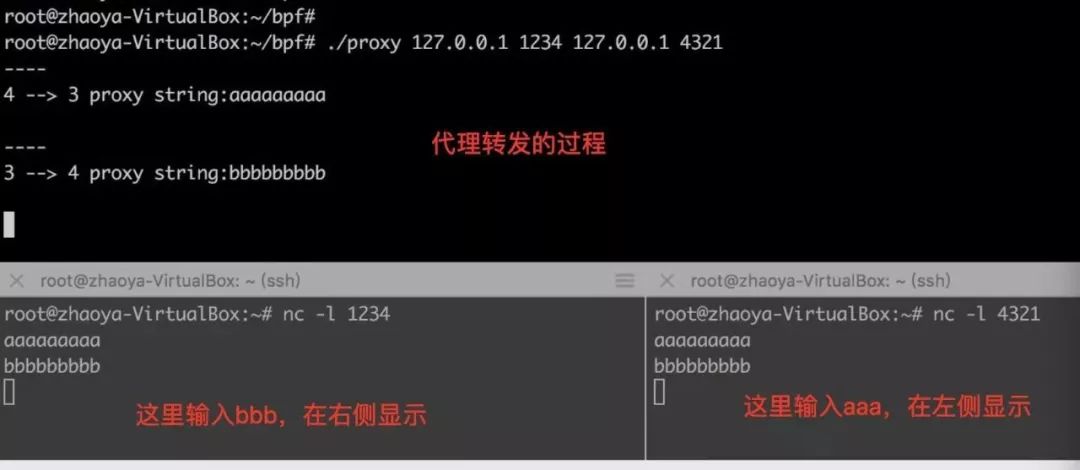
我们看到,一次转发经过了两次系统调用(忽略select)和两次数据拷贝。
我们的demo旨在演示基于eBPF的sockmap对proxy转发的offload过程,所以接下来,我们对上述代码进行一些改造,即加入对sockmap的支持。
这意味着我们需要做两件事:
写一个在socket之间转发数据的eBPF程序,并编译成字节码。
在proxy代码中加入eBPF程序的加载代码,并编译成可执行程序。
首先,先给出ebpf程序的C代码:
// sockmap_kern.c
#include <uapi/linux/bpf.h>
#include "bpf_helpers.h"
#include "bpf_endian.h"
struct bpf_map_def SEC("maps") proxy_map = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(unsigned short),
.value_size = sizeof(int),
.max_entries = 2,
};
struct bpf_map_def SEC("maps") sock_map = {
.type = BPF_MAP_TYPE_SOCKMAP,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 2,
};
SEC("prog_parser")
int bpf_prog1(struct __sk_buff *skb)
{
return skb->len;
}
SEC("prog_verdict")
int bpf_prog2(struct __sk_buff *skb)
{
__u32 *index = 0;
__u16 port = (__u16)bpf_ntohl(skb->remote_port);
char info_fmt[] = "data to port [%d]\n";
bpf_trace_printk(info_fmt, sizeof(info_fmt), port);
index = bpf_map_lookup_elem(&proxy_map, &port);
if (index == NULL)
return 0;
return bpf_sk_redirect_map(skb, &sock_map, *index, 0);
}
char _license[] SEC("license") = "GPL";
上述代码在内核源码树的 samples/bpf 目录下编译,只需要在Makefile中加入以下的行即可:
always += sockmap_kern.o
OK,下面我们给出用户态的测试程序,实际上就是将我们最初的 proxy.c 增加对ebpf/sockmap的支持即可:
// sockmap_user.c
#include <stdio.h>
#include <stdlib.h>
#include <sys/socket.h>
#include <sys/select.h>
#include <unistd.h>
#include <netdb.h>
#include <signal.h>
#include "bpf_load.h"
#include "bpf_util.h"
#define MAXSIZE 1024
char buf[MAXSIZE];
static int proxysd1, proxysd2;
static int sockmap_fd, proxymap_fd, bpf_prog_fd;
static int progs_fd[2];
static int key, val;
static unsigned short key16;
static int ctrl = 0;
static void int_handler(int a)
{
close(proxysd1);
close(proxysd2);
exit(0);
}
// 可以通过发送HUP信号来打开和关闭sockmap offload功能
static void hup_handler(int a)
{
if (ctrl == 1) {
key = 0;
bpf_map_update_elem(sockmap_fd, &key, &proxysd1, BPF_ANY);
key = 1;
bpf_map_update_elem(sockmap_fd, &key, &proxysd2, BPF_ANY);
ctrl = 0;
} else if (ctrl == 0){
key = 0;
bpf_map_delete_elem(sockmap_fd, &key);
key = 1;
bpf_map_delete_elem(sockmap_fd, &key);
ctrl = 1;
}
}
int main(int argc, char **argv)
{
char filename[256];
snprintf(filename, sizeof(filename), "%s_kern.o", argv[0]);
struct bpf_object *obj;
struct bpf_program *prog;
struct bpf_prog_load_attr prog_load_attr = {
.prog_type = BPF_PROG_TYPE_SK_SKB,
};
int ret;
struct sockaddr_in proxyaddr1, proxyaddr2;
struct hostent *proxy1, *proxy2;
unsigned short port1, port2;
fd_set rset;
int maxfd = 10;
if (argc != 5) {
exit(1);
}
prog_load_attr.file = filename;
signal(SIGINT, int_handler);
signal(SIGHUP, hup_handler);
// 这部分增加的代码引入了ebpf/sockmap逻辑
bpf_prog_load_xattr(&prog_load_attr, &obj, &bpf_prog_fd);
sockmap_fd = bpf_object__find_map_fd_by_name(obj, "sock_map");
proxymap_fd = bpf_object__find_map_fd_by_name(obj, "proxy_map");
prog = bpf_object__find_program_by_title(obj, "prog_parser");
progs_fd[0] = bpf_program__fd(prog);
bpf_prog_attach(progs_fd[0], sockmap_fd, BPF_SK_SKB_STREAM_PARSER, 0);
prog = bpf_object__find_program_by_title(obj, "prog_verdict");
progs_fd[1] = bpf_program__fd(prog);
bpf_prog_attach(progs_fd[1], sockmap_fd, BPF_SK_SKB_STREAM_VERDICT, 0);
proxysd1 = socket(AF_INET, SOCK_STREAM, 0);
proxysd2 = socket(AF_INET, SOCK_STREAM, 0);
proxy1 = gethostbyname(argv[1]);
port1 = atoi(argv[2]);
proxy2 = gethostbyname(argv[3]);
port2 = atoi(argv[4]);
bzero(&proxyaddr1, sizeof(struct sockaddr_in));
proxyaddr1.sin_family = AF_INET;
proxyaddr1.sin_port = htons(port1);
proxyaddr1.sin_addr = *((struct in_addr *)proxy1->h_addr);
bzero(&proxyaddr2, sizeof(struct sockaddr_in));
proxyaddr2.sin_family = AF_INET;
proxyaddr2.sin_port = htons(port2);
proxyaddr2.sin_addr = *((struct in_addr *)proxy2->h_addr);
connect(proxysd1, (struct sockaddr *)&proxyaddr1, sizeof(struct sockaddr));
connect(proxysd2, (struct sockaddr *)&proxyaddr2, sizeof(struct sockaddr));
key = 0;
bpf_map_update_elem(sockmap_fd, &key, &proxysd1, BPF_ANY);
key = 1;
bpf_map_update_elem(sockmap_fd, &key, &proxysd2, BPF_ANY);
key16 = port1;
val = 1;
bpf_map_update_elem(proxymap_fd, &key16, &val, BPF_ANY);
key16 = port2;
val = 0;
bpf_map_update_elem(proxymap_fd, &key16, &val, BPF_ANY);
// 余下的proxy转发代码保持不变,这部分代码一旦开启了sockmap offload,将不会再被执行。
while (1) {
FD_SET(proxysd1, &rset);
FD_SET(proxysd2, &rset);
select(maxfd, &rset, NULL, NULL, NULL);
memset(buf, 0, MAXSIZE);
if (FD_ISSET(proxysd1, &rset)) {
ret = recv(proxysd1, buf, MAXSIZE, 0);
printf("%d --> %d proxy string:%s\n", proxysd1, proxysd2, buf);
send(proxysd2, buf, ret, 0);
}
if (FD_ISSET(proxysd2, &rset)) {
ret = recv(proxysd2, buf, MAXSIZE, 0);
printf("%d --> %d proxy string:%s\n", proxysd2, proxysd1, buf);
send(proxysd1, buf, ret, 0);
}
}
return 0;
}
同样的,为了和eBPF程序配套,我们在Makefile中增加下面的行:
hostprogs-y += sockmap
sockmap-objs := sockmap_user.o
最后直接在 samples/bpf 目录下make即可生成下面的文件:
-rwxr-xr-x 1 root root 366840 12月 20 09:43 sockmap
-rw-r--r-- 1 root root 12976 12月 20 11:14 sockmap_kern.o
为了验证效果,我们起五个屏,下面是一个演示的过程截图和步骤说明: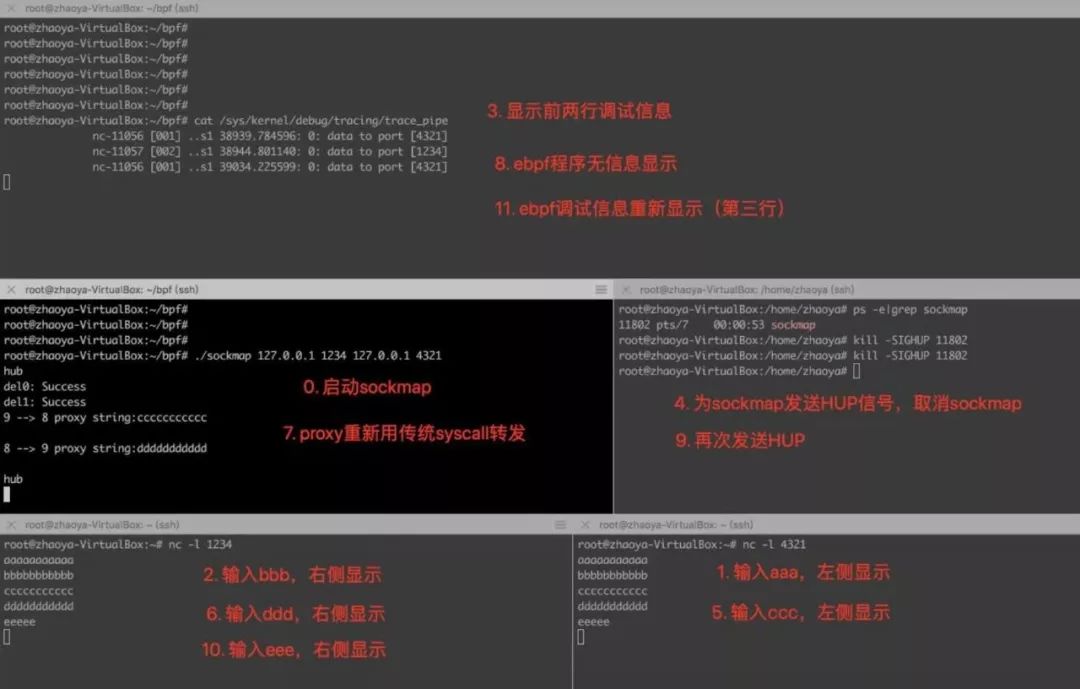
可见,proxy转发数据流的逻辑通过一个eBPF小程序从用户态服务进程中offload到了内核协议栈。用户态的proxy进程甚至不会由于数据的到来而被wakeup,这是比sendfile/splice高效的地方。
从上面的demo可以看到,sockmap顾名思义可以对接两个socket,这是eBPF这把 “瑞士军刀” 专门针对socket的一个小器件,这完美解决了sendfile的in_fd必须支持mmap的限制:
demo的代码和演示就到这里,我们再一次看到了eBPF之妙!
附:eBPF-可编程内核利器
我先说下为什么我把eBPF看作一把瑞士军刀:
瑞士军刀,包含小巧的圆珠笔、牙签、剪刀、平口刀、开罐器、螺丝刀、镊子等...
eBPF呢,它可以附着在xdp,kprobe,skb,socket lookup,trace,cgroup,reuseport,sched,filter等功能点,有人可能会说eBPF不如nginx,不如OpenWRT,不如OVS,不如iptables/nftables...确实,但是这就好比说瑞士军刀不如AK47,不如东风-41洲际导弹,不如Zippo,不如张小泉王麻子,不如苏泊尔一样...
eBPF和瑞士军刀一样,小而全是它们的本色( eBPF严格限制指令数量 ),便携,功能丰富,手艺人离不开的利器。
eBPF让 内核可编程 变的可能!
内核可编程是一个很有意思的事情,它使得内核的一些关键逻辑不再是一成不变的,而是可以通过eBPF对其进行编程,实现更多的策略化逻辑。
目前,eBPF已经密密麻麻扎进了Linux的各个角落,eBPF的作用点还在持续增多,迄至Linux 5.3内核,Linux内核已经支持如下的eBPF程序类型:
enum bpf_prog_type {
BPF_PROG_TYPE_UNSPEC,
BPF_PROG_TYPE_SOCKET_FILTER,
BPF_PROG_TYPE_KPROBE,
BPF_PROG_TYPE_SCHED_CLS,
BPF_PROG_TYPE_SCHED_ACT,
BPF_PROG_TYPE_TRACEPOINT,
BPF_PROG_TYPE_XDP,
BPF_PROG_TYPE_PERF_EVENT,
BPF_PROG_TYPE_CGROUP_SKB,
BPF_PROG_TYPE_CGROUP_SOCK,
BPF_PROG_TYPE_LWT_IN,
BPF_PROG_TYPE_LWT_OUT,
BPF_PROG_TYPE_LWT_XMIT,
BPF_PROG_TYPE_SOCK_OPS,
BPF_PROG_TYPE_SK_SKB,
BPF_PROG_TYPE_CGROUP_DEVICE,
BPF_PROG_TYPE_SK_MSG,
BPF_PROG_TYPE_RAW_TRACEPOINT,
BPF_PROG_TYPE_CGROUP_SOCK_ADDR,
BPF_PROG_TYPE_LWT_SEG6LOCAL,
BPF_PROG_TYPE_LIRC_MODE2,
BPF_PROG_TYPE_SK_REUSEPORT,
BPF_PROG_TYPE_FLOW_DISSECTOR,
BPF_PROG_TYPE_CGROUP_SYSCTL,
BPF_PROG_TYPE_RAW_TRACEPOINT_WRITABLE,
BPF_PROG_TYPE_CGROUP_SOCKOPT,
};
一共26种类型,26个作用点。而在不久之前的Linux 4.19内核,这个数值也就22。可见eBPF吞噬内核的速度之快!
后面,我们还会看到eBPF在socket lookup机制所起的妙用。
浙江温州皮鞋湿,下雨进水不会胖。
(完)
觉得内容不错的话,别忘了右下角点个 在看 哦~
以上是关于用Linux内核的瑞士军刀-eBPF实现socket转发offload的主要内容,如果未能解决你的问题,请参考以下文章