抛弃 RESTful HTTP 拥抱 WebSocket,用一台服务器模拟谷歌的搜索补全功能
Posted 架构头条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了抛弃 RESTful HTTP 拥抱 WebSocket,用一台服务器模拟谷歌的搜索补全功能相关的知识,希望对你有一定的参考价值。
对于需要实时通信的网站,使用RESTful HTTP请求响应方法可能显得极不高效。我们提出了一种新方法,并通过一种需要实时通信的功能对其进行了验证,这种功能已经众所周知,并在很多网站中有所运用:搜索框自动补全。
作为最繁忙的搜索平台,根据Internet Live Stats估算,谷歌每秒钟大约要处理40,000次用户搜索。假设在每次搜索中自动补全功能产生6个请求,我们的实验表明MigratoryData只需一台1U服务器即可应对该负载。
准确来说,我们证明了通过1U服务器运行的一台MigratoryData服务器可以处理1百万并发用户产生的每秒240,000个自动补全请求,并实现平均11.82毫秒的往返延迟。
自动补全功能可以在用户通过搜索框输入查询的过程中提供搜索建议。目前所用的方法主要基于HTTP请求-响应模式,用户每输入一个字符,均需要向Web服务器发送一次HTTP请求,并通过HTTP响应获得搜索建议。这种方法有两个局限:带宽和延迟。
一方面,由于每个自动补全请求只包含少量字节(例如用户在搜索框中输入的字符),但浏览器会自动添加数百字节内容作为HTTP标头。对于用户搜索活动频繁的网站,大量额外的数据意味着带宽的巨大浪费,同时还需要耗费额外的CPU周期以处理这些不必要的HTTP标头。
另一方面,对于每个HTTP请求,都需要在用户和Web服务器之间新建一个TCP连接,甚至可能需要进行TLS/SSL握手。随着用户输入每个字符都进行这样的操作会对延迟产生极高影响(例如用户输入一个字符到看到搜索结果之间的等待时间)。为了消除这种局限可以使用HTTP保活(Keep-Alive)连接,借此在一次超时期间通过同一个TCP连接发送多个HTTP请求。然而尽管如此,当超时值到期后依然需要新建连接。
为了解决上文提到的RESTful HTTP方法所面临的局限,很多人选择使用WebSocket协议代替HTTP。WebSocket协议在开销方面只增加几字节数据,因此相比HTTP协议数百字节的数据增量,可大幅降低开销。更重要的是,WebSocket协议按照设计可使用持久连接,无需定期重连,可实现更低延迟的通信。
目前有很多WebSocket协议的服务器实现,然而相比RESTful HTTP方法,这些实现在带宽优化方面做的都略显不够,并非所有WebSocket服务器实现能提供同等程度的低延迟和可缩放性。
注意 – 相比Web服务器,WebSocket协议本身无法保证服务器能获得更好缩放性或更低延迟,该协议只能提供实现这些特性的前提。缩放性和延迟的程度取决于具体的WebSocket服务器实现。
MigratoryData Server就是一种此类WebSocket服务器实现。该产品是成功解决C10M问题(单一服务器上千万并发用户)的首个服务器实现。
MigratoryData提供了一套通用API,并为大部分主流编程环境,包括Web应用程序提供了所需的库。该产品可暴露一种基于主题(Subject)的发布/订阅通信范式,根据所采用的发布/订阅模式,还可暴露下列异步请求/响应模型:
一个生成方订阅至主题X
消耗方发送包含主题X的请求消息并附加回复主题Y(如果尚未订阅,消耗方可自动订阅主题Y)
生成方收到该消息后,从请求消息中提取出回复的主题Y,并使用包含主题Y的消息作为回复
下文我们将展示这种通过WebSocket实现的请求/响应交互如何作为可缩放的方法取代RESTful HTTP。
我们使用了四台完全相同的计算机,每台装备2颗2.60GHz主频Intel Xeon E5-2670 CPU,以及64GB内存:
计算机A运行一个MigratoryData Server 5.0.20实例
计算机B和计算机C运行两个Requestor工具实例,分别用于打开500,000个并发WebSocket连接,自动补全请求将通过这些连接发送
计算机D运行16个Provider工具实例,用于为每个自动补全请求提供搜索建议
四台计算机均运行CentOS Linux 7.2,使用默认的3.10.0-327.28.3.el7.x86_64内核,未进行任何内核调优。
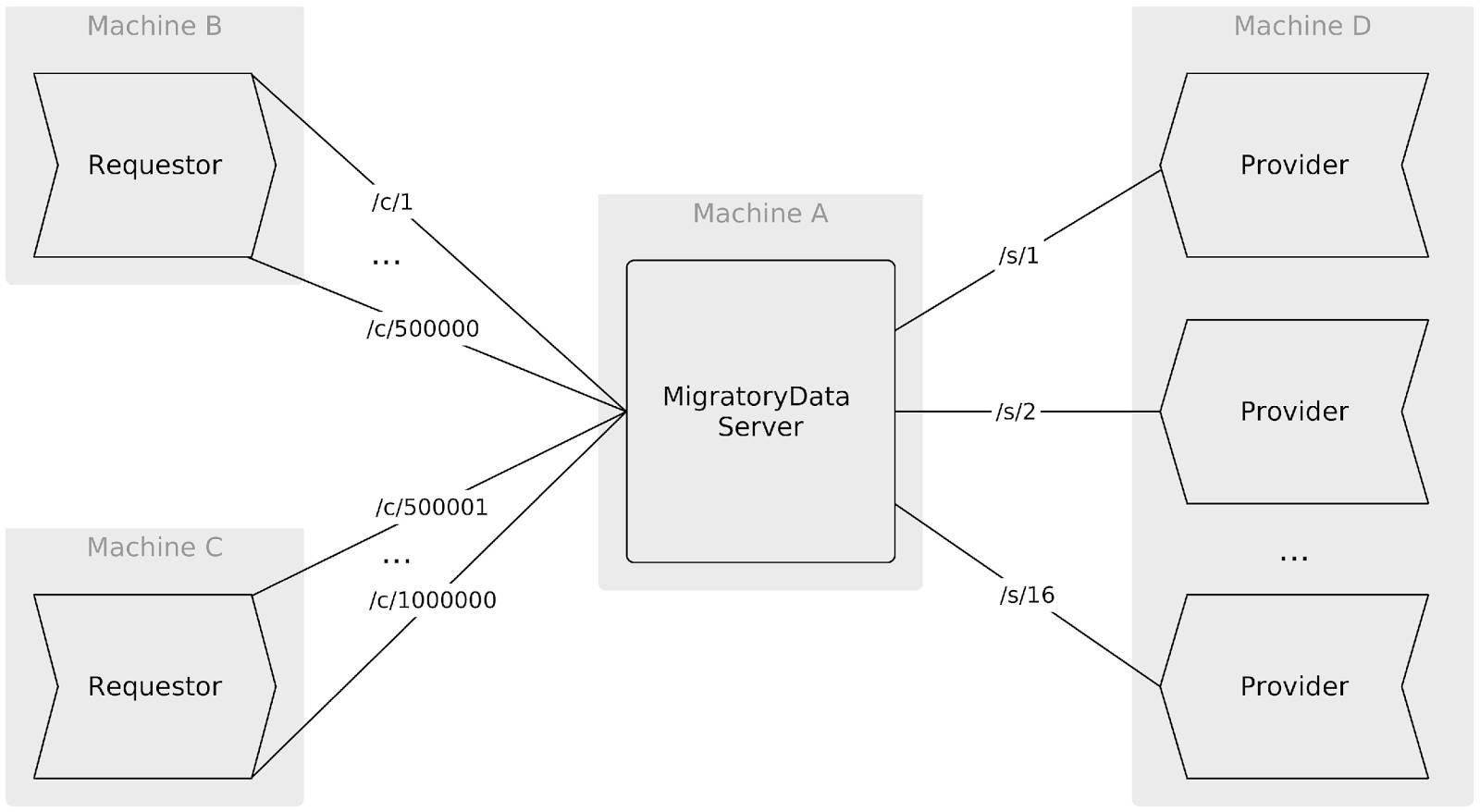
为了模拟一百万用户中的一位用户N发送一条自动补全请求,Requestor工具会随机选择十六个Provider所订阅的某一主题,例如/s/M。此外Requestor工具会将用户N订阅至主题/c/N(如果尚未订阅),并将具备下列属性的请求消息发布至MigratoryData Server:
主题:/c/N
主题:/s/M
载荷:一个代表搜索查询的32字节随机字符串
订阅至主题/s/M的Provider M将收到上述消息,通过向MigratoryData Server发布具备下列属性的回复消息即可作出回应:
主题:/c/N
载荷:一个代表搜索建议的256字节随机字符串
由于用户N已订阅至主题/c/N,便可收到上述回复信息。往返延迟将按照请求消息的创建完成到用户最终收到回复信息之间的时间差来计算。
注意 – 请求-回复通信的往返延迟包含请求消息从Requestor传递至MigratoryData Server,随后传递至Provider所需的时间,外加回复消息从Provider传递至MigratoryData Server,并最终传递至Requestor所需的时间。
最后需要注意,在上述环境中,有多个代表搜索服务的Provider实例对请求进行均衡。该架构使得搜索服务(包括其搜索缓存)能够横向缩放并模拟RESTful HTTP方法,此外还可通过多个搜索服务对请求进行均衡。
每秒钟,两个Requestor实例为从一百万并发用户中随机选择出的240,000个用户处理240,000个自动补全请求,获得搜索建议所需的平均往返延迟为11.8毫秒,其中第95百分位(95th percentile)延迟为20毫秒,第99百分位(99th percentile)延迟为130毫秒(通过超过40亿个请求的结果计算而来)。
| 指标 | 数据 |
| 并发WebSocket连接数 | 1,000,016 |
| 订阅主题数 | 1,000,016 |
| 每秒请求数 | 每秒请求240,000条消息 |
| 消息总吞吐率(Requestors与Providers收和发) | 每秒960,000条消息 |
| 平均延迟 | 11.82毫秒 |
| 标准偏差延迟 | 26.28毫秒 |
| 第95百分位延迟 | 20毫秒 |
| 第99百分位延迟 | 130毫秒 |
| 最大延迟 | 1783毫秒 |
| 请求总数 | 4,084,890,291 |
| 硬件 | 一台1U服务器,装备2颗2.60GHz主频Intel Xeon E5-2670 CPU与64GB内存,Intel X520-DA1 10 GbE网络适配器 |
| 操作系统 | CentOS Linux 7.2,默认内核3.10.0-327.28.3.el7.x86_64(未进行内核调优) |
| Java运行时环境 | Oracle 1.8.0_40-b25 |
| 入站网络利用率(Providers与Requestors总和) | 每秒1.06Giga字节 |
| 出站网络利用率(Providers与Requestors总和) | 每秒1.17Giga字节 |
| CPU利用率 | 65% |
MigratoryData Server可通过JMX和其他协议进行监视。我们使用jconsole工具(包含在Java Development Kit中)进行JMX监视。下列屏幕截图截取自JMX监视过程。
正如评测环境介绍中所述,我们通过两个Requestor实例创建了1,000,000个到MigratoryData服务器的并发WebSocket连接,借此模拟一百万用户。以百万用户中的每个均订阅至不同的主题,随后通过这些主题获得搜索建议。此外我们使用16个Provider实例打开16个到MigratoryData服务器的连接,借此模拟搜索建议服务。这16个服务中的每个均订阅至不同主题,借此响应自动补全请求。如下图所示,JMX的ConnectedSessions属性也显示出共有1,000,016个并发连接。
在评测环境中,用户每秒发出240,000条请求消息。因此每秒传入MigratoryData服务器的消息总数包含来自Requestors的每秒240,000条请求消息,外加来自Providers的每秒240,000条回复消息。
另外每秒传出MigratoryData服务器的消息总数为每秒发送给Requestors的240,000条回复消息,外加每秒发送给Provides的240,000条请求消息。
这些总数(每秒480,000条传出消息外加每秒480,000条传入消息)对应了下列截图中JMX的OutPublishedMessagesPerSecond和InPublishedMessagesPerSecond属性。
因此MigratoyData Server处理传入和传出消息的总吞吐量约为每秒1百万条消息。
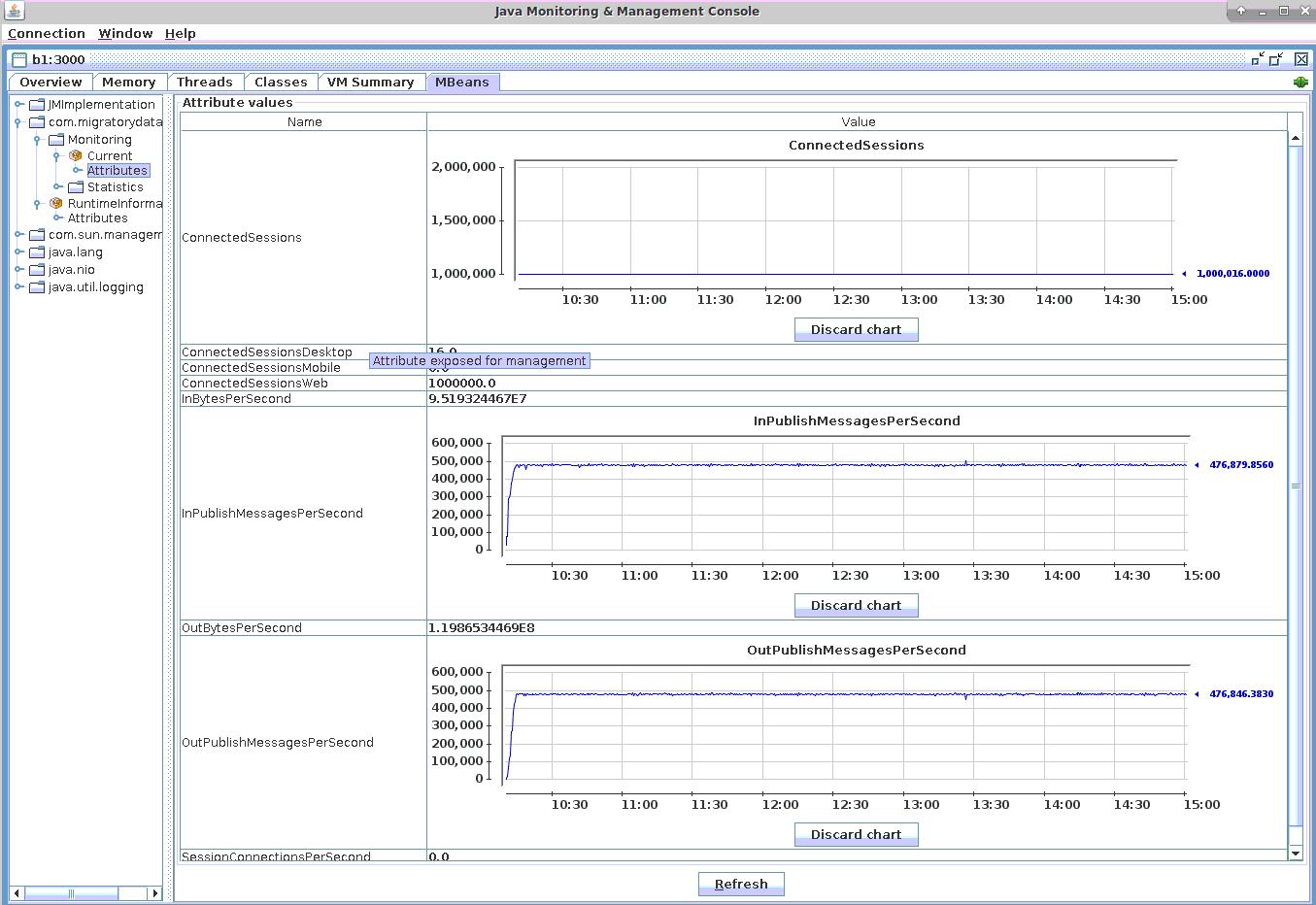
最后需要注意,该性能评测是在大致5小时内进行完毕的。按照每秒240,000个请求的速度,MigratoryData共处理了超过40亿个请求!
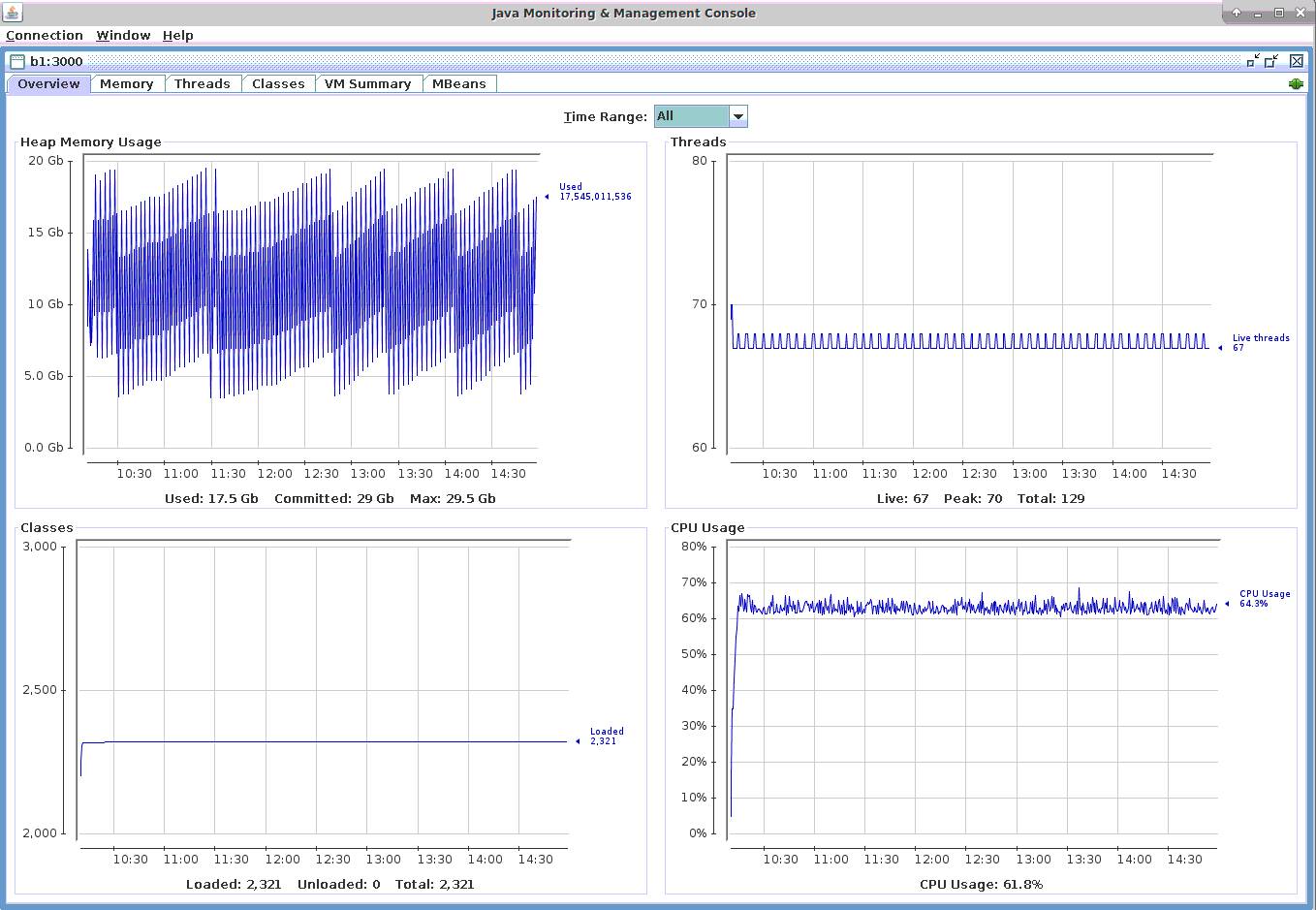
从截图中可以看到,评测过程中CPU用量始终低于70%。分配给JVM的内存最大值为30GB。最后,由于整个评测是在大约5小时内进行的,因此内存和CPU用量均呈现出规律性变化。
如上文评测环境介绍中所述,往返延迟是请求从Requestor传递至MigratoryData服务器,后传递至Provider所用时间,外加回复消息从Provider传递至MigratoryData服务器,并最终传递至Requestor所用时间总和。
从该评测中我们计算了每个请求/回复交互的往返延迟,共得出超过40亿个延迟值。此外我们还计算了延迟的平均值、标准偏差,以及最大延迟值。这些有关延迟的统计信息会随着每次新产生的请求/回复交互递增,结合超过40亿个延迟值汇总计算而来。简单总结延迟情况如下:
平均延迟:11.82毫秒
标准偏差延迟:26.28毫秒
最大延迟:1783毫秒
另外我们还使用HdrHistogram库计算了延迟的百分位数。在下图中可以看到请求数(百万计)和往返延迟(毫秒计)在不同百分位下的分布。
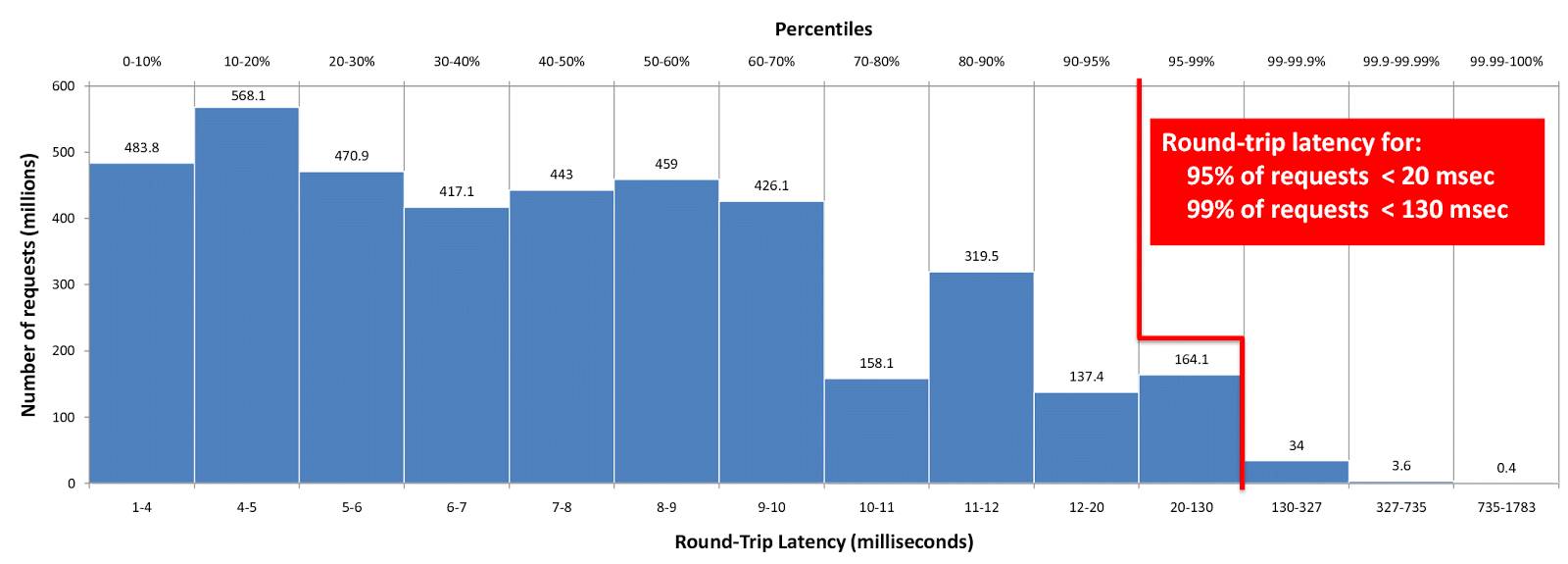
例如在上图中可以看到,第95百分位的延迟为20毫秒,第99百分位延迟为130毫秒。因此对于共40亿请求中的38亿个请求,往返延迟均低于20毫秒;而对于共40亿个请求中的39.6亿个请求,往返延迟均不超过130毫秒。
注意 – 通过进一步优化还可降低第99以及更高百分位的延迟。这些值通常会受到JVM垃圾回收机制的影响。在之前针对另一个场景进行的性能评测中我们发现,使用Azul Systems的Zing JVM对垃圾回收进行优化后,可以将第99百分位的延迟从585毫秒降低至25毫秒,最大延迟值则从1700毫秒降低至126毫秒。
本文中,我们为有大量用户、高频请求,以及/或需要低延迟通信的网站提出了一种新的通信架构,并通过搜索框自动补全功能这个用例进行了证实。
我们发现可缩放的WebSocket服务器提供了更易用的编程模型,例如发布-订阅,可以很好地取代目前所采用的RESTfull HTTP架构,在延迟和带宽使用方面均有更出色的表现,同时在编程的复杂度方面也基本持平。
咳咳咳,广告时间到。
QCon北京2017将于4月16日~18日在北京·国家会议中心举行,会务组(操劳准备半年)精心设计了智能化运维、支撑海量业务的互联网架构、大规模网关系统、微服务实践等30来个专题;将邀请来自Google、Facebook、阿里巴巴、腾讯、百度、美团点评、爱奇艺等典型互联网公司的技术专家,分享技术领域最新成果。目前票价处于8折期。感兴趣的小伙伴请识别下面二维码跳转了解详情。
以上是关于抛弃 RESTful HTTP 拥抱 WebSocket,用一台服务器模拟谷歌的搜索补全功能的主要内容,如果未能解决你的问题,请参考以下文章